Real-Time Video Segmentation on Mobile Devices
Video Segmentation, Mobile, Tensorflow Lite
Running vision tasks such as object detection, segmentation in real time on mobile devices. Our goal is to implement video segmentation in real time at least 24 fps on Google Pixel 2. We use efficient deep learning network specialized in mobile/embedded devices and exploit data redundancy between consecutive frames to reduce unaffordable computational cost. Moreover, the network can be optimized with 8-bits quantization provided by tf-lite.

Example: Reai-Time Video Segmentation(Credit: Google AI)
- Compressed DeepLabv3+[1]
- Backbone: MobileNetv2[2]
- 8-bits Quantization on TensorFlow Lite
- Video Segmentation on Google Pixel 2
- Datasets
- PASCAL VOC 2012
- DeepLabv3+ on tf-lite
- Use data redundancy between frames
- Optimization
- Quantization
- Reduce the number of layers, filters and input size
More results here bit.ly/jejunet-output

Video Segmentation on Google Pixel 2
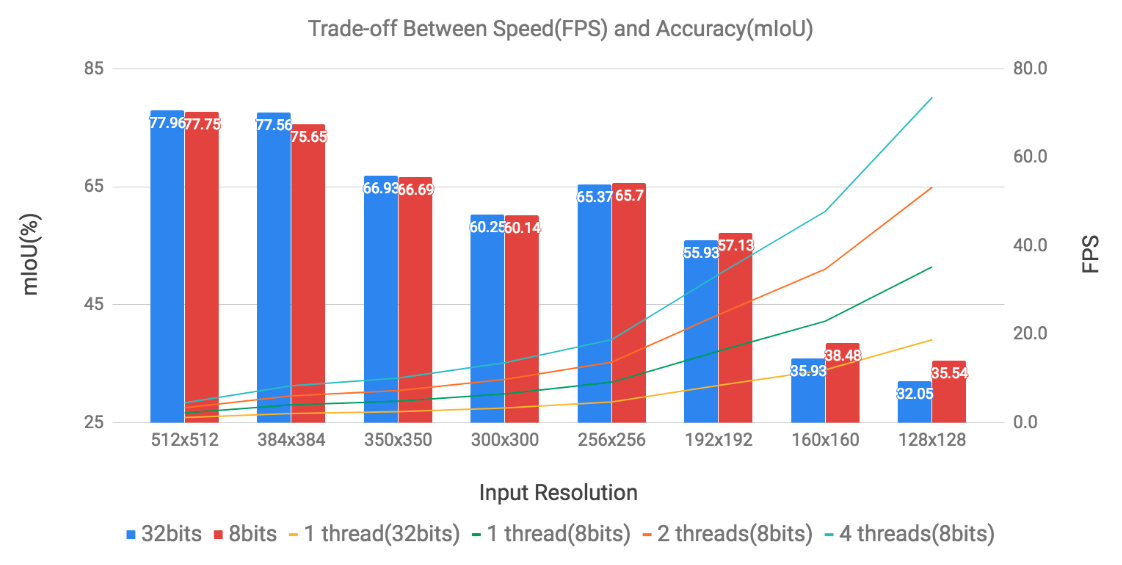
| Network | Input | Stride | Quantization(w/a) | PASCAL mIoU | Runtime(.tflite) | File Size(.tflite) |
|---|---|---|---|---|---|---|
| DeepLabv3, MobileNetv2 | 512x512 | 16 | 32/32 | 79.9% | 862ms | 8.5MB |
| DeepLabv3, MobileNetv2 | 512x512 | 16 | 8/8 | 79.2% | 451ms | 2.2MB |
| DeepLabv3, MobileNetv2 | 512x512 | 16 | 6/6 | 70.7% | - | - |
| DeepLabv3, MobileNetv2 | 512x512 | 16 | 6/4 | 30.3% | - | - |

-
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam. arXiv: 1802.02611.
[link]. arXiv: 1802.02611, 2018.
-
Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
[link]. arXiv:1801.04381, 2018.
- Taekmin Kim(Mentee) @tantara
- Jisung Kim(Mentor) @runhani
This work was partially supported by Deep Learning Jeju Camp and sponsors such as Google, SK Telecom. Thank you for the generous support for TPU and Google Pixel 2, and thank Hyungsuk and all the mentees for tensorflow impelmentations and useful discussions.
© Taekmin Kim, 2018. Licensed under the MIT License.