mnist_with_backpropagation:network.py
- numpy
| 関数 | |
|---|---|
| 活性化関数 | シグモイド関数 |
| コスト関数 | 平均2乗誤差 |
活性化関数はシグモイド関数を用いている
シグモイド関数は以下のようなものである
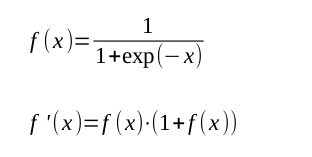
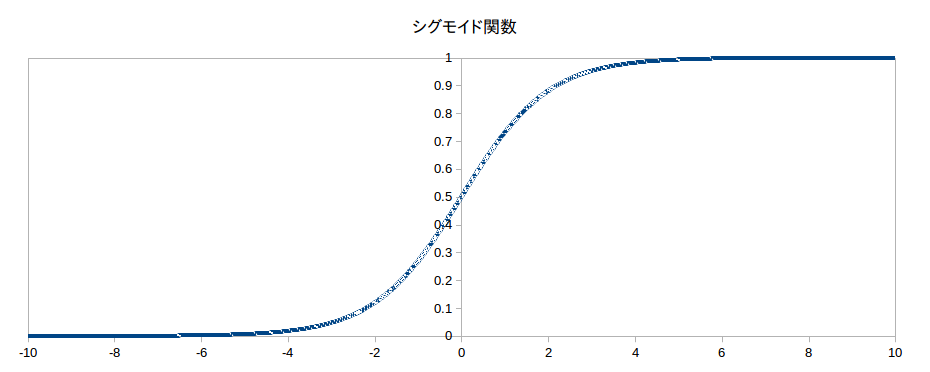
この関数のグラフを示す
この関数をコード化すると以下のようになる
さらにそれをnumpy.vectorize()によってベクトル化している
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_prime(x):
return sigmoid(x) * (1.0 - sigmoid(x))
sigmoid_vec = numpy.vectorize(sigmoid)
sigmoid_prime_vec = numpy.vectorize(sigmoid_prime)ネットワークの重みとバイアスを乱数を用いて初期化
- 重み(self.w)はn行m列の行列
n: その層のニューロンの数
m: 入力データの数 - バイアス(self.b)はj行1列の行列
j: その層のニューロンの数
def __init__(self, layers):
self.layers = len(layers)
self.layer = layers
self.w = [np.random.randn(x, y) for x, y in zip(layers[1:], layers[:-1])]
self.b = [np.random.randn(x, 1) for x in layers[1:]]
self.Errors = []これらは行列のリストとして定義されている
バイアスはベクトルとして定義されているが1列の行列として扱うことにする
def train(self, training_data, epoch=10, mini_batch_size=2, learning_rate=0.5, error_log=False):
for count in xrange(epoch):
mini_batches = [training_data[x:x + mini_batch_size] for x in xrange(0, len(training_data), mini_batch_size)]このコードでは訓練データからミニバッチに切り分けている
そして分けたミニバッチでネットワークを訓練している
for m in mini_batch:
self.update_mini_batch(m, learning_rate)def update_mini_batch(self, mini_batch, learning_rate):
N = len(mini_batch)
Ninv = 1.0 / len(mini_batch)
U = []
Z = []
X = []
D = []
Y = []
for x, y in mini_batch:
X.append(x)
D.append(y)
X = numpy.array(X).ravel().reshape((self.layer[0], N))
Z.append(X)
U.append(X)
for l, w, b in zip(xrange(self.layers), self.w, self.b):
U.append(numpy.dot(w, Z[l]) + numpy.dot(b, numpy.ones((1, N))))
Z.append(sigmoid_vec(U[-1]))
Y.append(Z[-1])
Y = numpy.array(Y).reshape((self.layer[-1], N))
D = numpy.array(D).reshape((self.layer[-1], N))
Delta = [0] * self.layers
Delta[-1] = Y - D
for l in xrange(2, self.layers):
active = sigmoid_prime_vec(U[-l])
buf = np.dot(self.w[-l+1].transpose(), Delta[-l+1])
Deltaa[-l] = numpy.multiply(active, buf)
for l, w in zip(xrange(1, self.layers), self.w):
dw = Ninv * numpy.dot(Delta[l], Z[l-1].transpose())
db = Ninv * numpy.dot(Delta[l], numpy.ones((N, 1)))
dw = dw * learning_rate * -1.0
db = db * learning_rate * -1.0
self.w[l-1] += dw
self.b[l-1] += db