| description | title | image | slug | last_update | ||||
|---|---|---|---|---|---|---|---|---|
我们继续在Seeed XIAO family的巨大的新微型设备ESP32S3 Sense上探索机器学习。 |
基于 Edge Impulse 的关键词识别 |
/cn/xiao_esp32s3_keyword_spotting |
|
{kind=link}

本教程将指导您在XIAO ESP32S3 Sense微控制器板上使用TinyML实现关键字识别(KWS)系统,并在Edge Impulse的帮助下进行数据收集和模型训练。KWS对于语音识别系统至关重要,借助TinyML的力量,可以在更小、低功耗的设备上实现。让我们使用Edge Impulse和XIAO ESP32S3 Sense构建我们自己的KWS系统!
在开始这个项目之前,请按照下面的准备步骤准备这个项目所需的软件和硬件。
为了顺利完成这个项目,您需要准备以下硬件。
-
XIAO ESP32S3 Sense
-
microSD卡(不大于32GB)
-
microSD读卡器
-
USB-C数据线
使用XIAO ESP32S3 Sense安装扩展板时,可以使用扩展板上的麦克风。
安装扩展板非常简单,只需要将扩展板上的连接器对准小ESP32S3上的B2B连接器,然后用力按下,听到“咔”的一声,安装完成。

XIAO ESP32S3 Sense支持高达32GB的microSD卡,所以如果您准备为XIAO购买microSD卡,请参阅此规格。并在使用microSD卡之前将microSD卡格式化为FAT32格式。
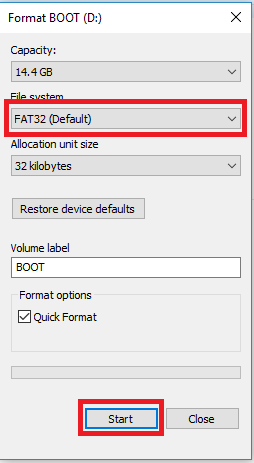
格式化后,您可以将microSD卡插入microSD卡插槽。请注意插入方向,金手指侧应朝内。

如果这是你第一次使用XIAO ESP32S3 Sense,那么在开始之前,我们建议你阅读以下两个Wiki来学习如何使用它。
让我们使用板载SD读卡器来保存。wav音频文件,我们需要先适应XIAO PSRAM。
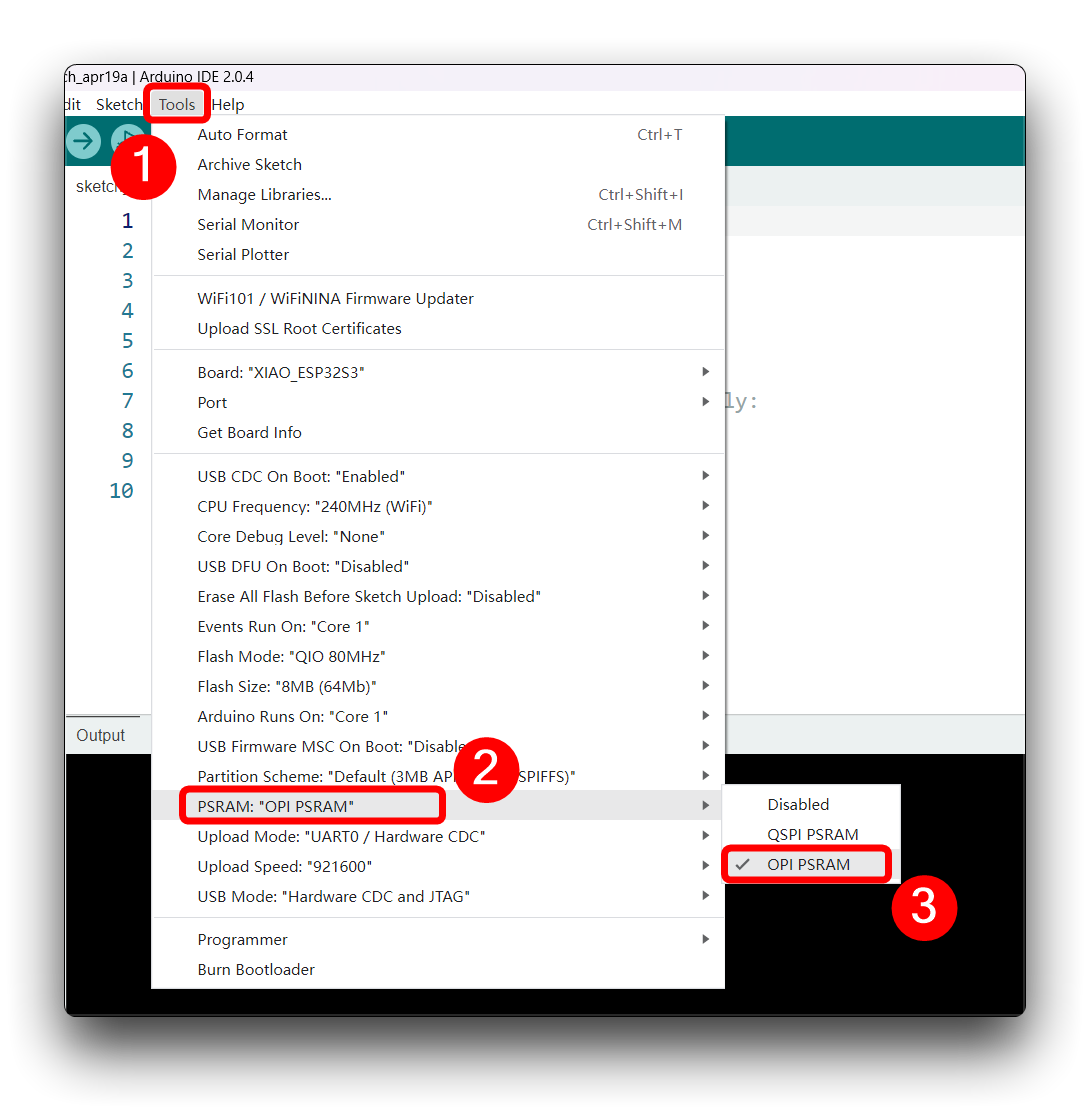
然后编译并上传以下程序到XIAO ESP32S3。
:::提示 本代码通过Seeed XIAO ESP32S3感音板的I2S接口录制音频,并将录制的音频以a.wav文件的形式保存在SD卡上,并允许通过串口监视器发送的命令来控制录制过程。音频文件的名称是可定制的(它应该是与训练一起使用的类标签),可以制作多个录音,每个录音保存在一个新文件中。该代码还包括增加录音音量的功能。 :::
/*
* WAV Recorder for Seeed XIAO ESP32S3 Sense
*
* NOTE: To execute this code, we will need to use the PSRAM
* function of the ESP-32 chip, so please turn it on before uploading.
* Tools>PSRAM: "OPI PSRAM"
*
* Adapted by M.Rovai @May23 from original Seeed code
*/
#include <I2S.h>
#include "FS.h"
#include "SD.h"
#include "SPI.h"
// make changes as needed
#define RECORD_TIME 10 // seconds, The maximum value is 240
#define WAV_FILE_NAME "data"
// do not change for best
#define SAMPLE_RATE 16000U
#define SAMPLE_BITS 16
#define WAV_HEADER_SIZE 44
#define VOLUME_GAIN 2
int fileNumber = 1;
String baseFileName;
bool isRecording = false;
void setup() {
Serial.begin(115200);
while (!Serial) ;
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, SAMPLE_RATE, SAMPLE_BITS)) {
Serial.println("Failed to initialize I2S!");
while (1) ;
}
if(!SD.begin(21)){
Serial.println("Failed to mount SD Card!");
while (1) ;
}
Serial.printf("Enter with the label name\n");
//record_wav();
}
void loop() {
if (Serial.available() > 0) {
String command = Serial.readStringUntil('\n');
command.trim();
if (command == "rec") {
isRecording = true;
} else {
baseFileName = command;
fileNumber = 1; // reset file number each time a new base file name is set
Serial.printf("Send rec for starting recording label \n");
}
}
if (isRecording && baseFileName != "") {
String fileName = "/" + baseFileName + "." + String(fileNumber) + ".wav";
fileNumber++;
record_wav(fileName);
delay(1000); // delay to avoid recording multiple files at once
isRecording = false;
}
}
void record_wav(String fileName)
{
uint32_t sample_size = 0;
uint32_t record_size = (SAMPLE_RATE * SAMPLE_BITS / 8) * RECORD_TIME;
uint8_t *rec_buffer = NULL;
Serial.printf("Start recording ...\n");
File file = SD.open(fileName.c_str(), FILE_WRITE);
// Write the header to the WAV file
uint8_t wav_header[WAV_HEADER_SIZE];
generate_wav_header(wav_header, record_size, SAMPLE_RATE);
file.write(wav_header, WAV_HEADER_SIZE);
// PSRAM malloc for recording
rec_buffer = (uint8_t *)ps_malloc(record_size);
if (rec_buffer == NULL) {
Serial.printf("malloc failed!\n");
while(1) ;
}
Serial.printf("Buffer: %d bytes\n", ESP.getPsramSize() - ESP.getFreePsram());
// Start recording
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, rec_buffer, record_size, &sample_size, portMAX_DELAY);
if (sample_size == 0) {
Serial.printf("Record Failed!\n");
} else {
Serial.printf("Record %d bytes\n", sample_size);
}
// Increase volume
for (uint32_t i = 0; i < sample_size; i += SAMPLE_BITS/8) {
(*(uint16_t *)(rec_buffer+i)) <<= VOLUME_GAIN;
}
// Write data to the WAV file
Serial.printf("Writing to the file ...\n");
if (file.write(rec_buffer, record_size) != record_size)
Serial.printf("Write file Failed!\n");
free(rec_buffer);
file.close();
Serial.printf("Recording complete: \n");
Serial.printf("Send rec for a new sample or enter a new label\n\n");
}
void generate_wav_header(uint8_t *wav_header, uint32_t wav_size, uint32_t sample_rate)
{
// See this for reference: http://soundfile.sapp.org/doc/WaveFormat/
uint32_t file_size = wav_size + WAV_HEADER_SIZE - 8;
uint32_t byte_rate = SAMPLE_RATE * SAMPLE_BITS / 8;
const uint8_t set_wav_header[] = {
'R', 'I', 'F', 'F', // ChunkID
file_size, file_size >> 8, file_size >> 16, file_size >> 24, // ChunkSize
'W', 'A', 'V', 'E', // Format
'f', 'm', 't', ' ', // Subchunk1ID
0x10, 0x00, 0x00, 0x00, // Subchunk1Size (16 for PCM)
0x01, 0x00, // AudioFormat (1 for PCM)
0x01, 0x00, // NumChannels (1 channel)
sample_rate, sample_rate >> 8, sample_rate >> 16, sample_rate >> 24, // SampleRate
byte_rate, byte_rate >> 8, byte_rate >> 16, byte_rate >> 24, // ByteRate
0x02, 0x00, // BlockAlign
0x10, 0x00, // BitsPerSample (16 bits)
'd', 'a', 't', 'a', // Subchunk2ID
wav_size, wav_size >> 8, wav_size >> 16, wav_size >> 24, // Subchunk2Size
};
memcpy(wav_header, set_wav_header, sizeof(set_wav_header));
}现在,将代码上传到XIAO并从关键字(hello和stop)中获取示例。你也可以捕捉噪声和其他单词。串行监视器将提示您收到要记录的标签。
发送标签(例如,hello)。程序将等待另一个命令:rec。
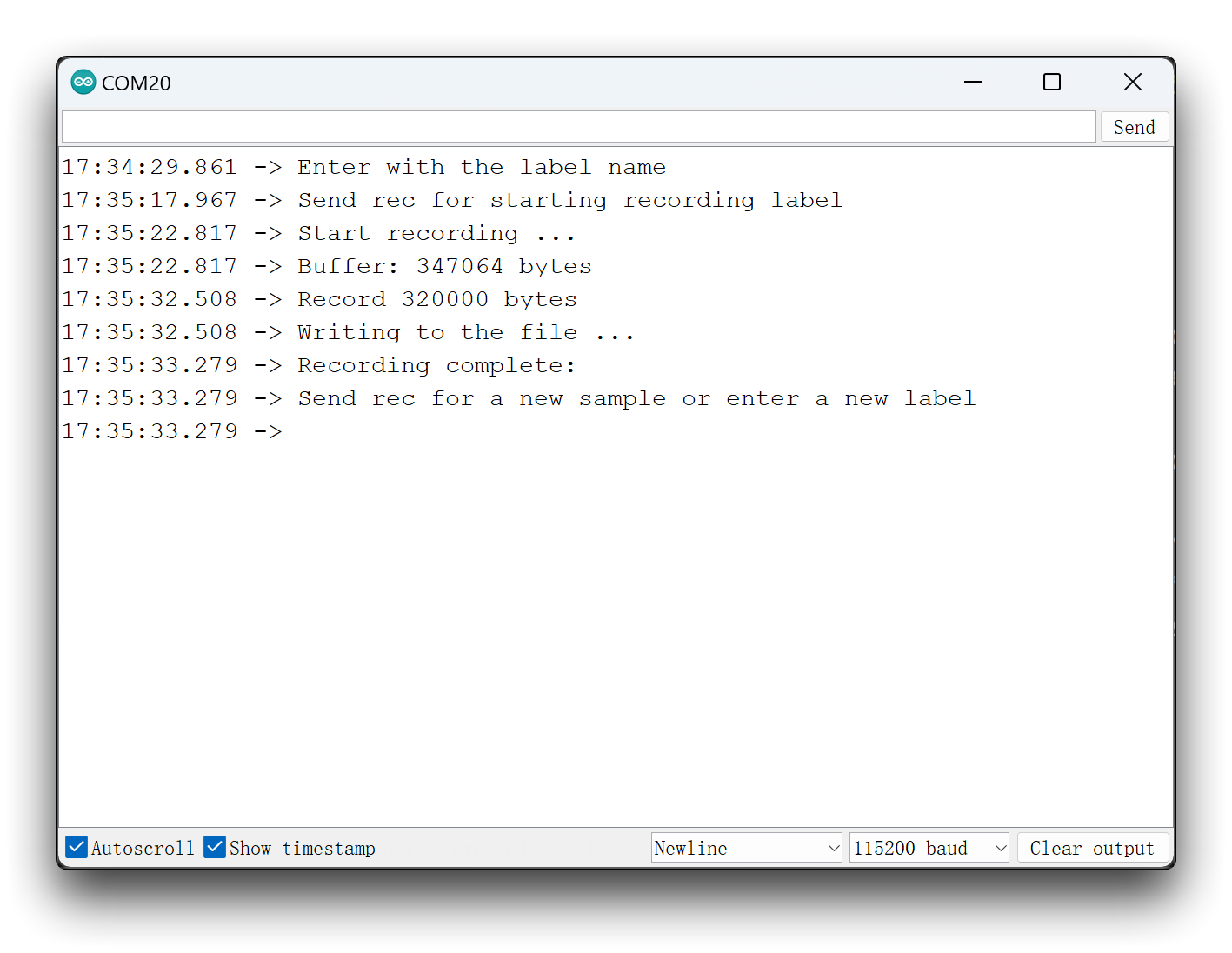
每次发送命令rec时,程序就会开始记录新的样本。文件将保存为hello.1.wav、hello.2.wav、hello.3.wav等,直到发送一个新标签(例如,stop)。在这种情况下,你应该为每个新样本发送命令rec,它将被保存为stop.1.wav、stop.2.wav、stop.3.wav等。
最终,我们将得到保存在SD卡上的文件。
:::请注意
我们建议您为每个标签样本提供足够的声音。你可以在每10秒的录制过程中重复你的关键词几次,我们将在后续步骤中对样本进行分割。但是关键字之间需要一些空格。 :::
当定义并收集原始数据集时,我们应该在Edge Impulse启动一个新项目。创建项目后,在Data Acquisition部分选择Upload Existing Data工具。选择要上传的文件。
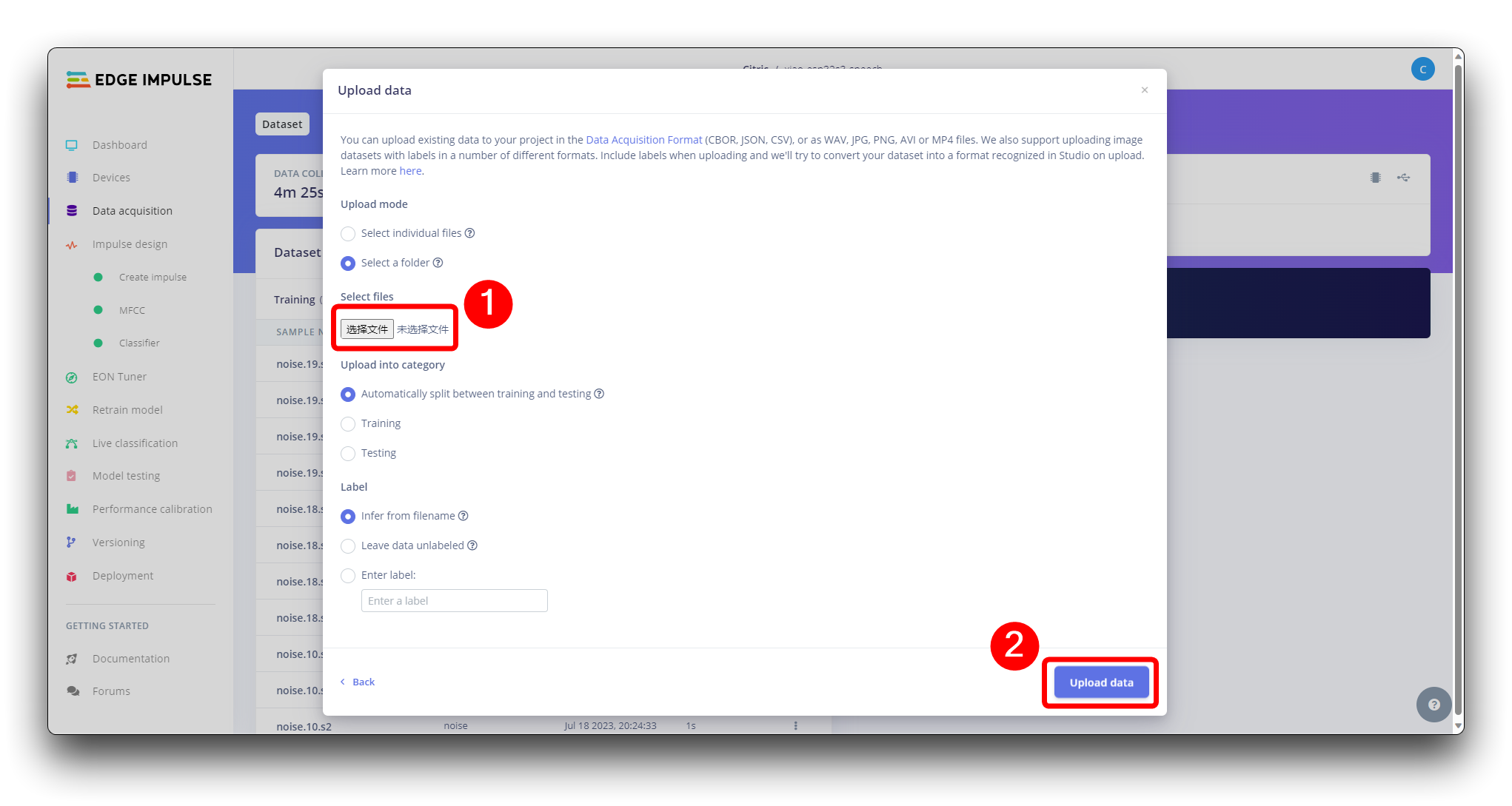
并将它们上传到工作室(你可以在训练/测试中自动分割数据)。重复到所有类和所有原始数据。
数据集上的所有数据长度都是1秒,但上一节中记录的样本长度为10秒,必须将其拆分为1秒的样本才能兼容。点击样本名称后的三个点,并选择Split sample.
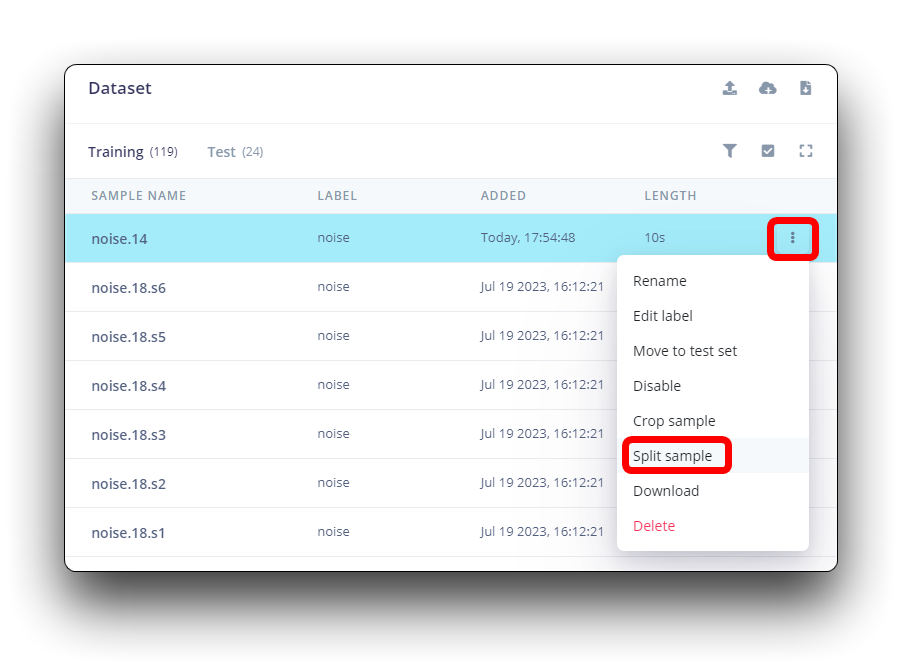
一旦进入该工具,将数据拆分为1秒的记录。如有必要,添加或删除片段。
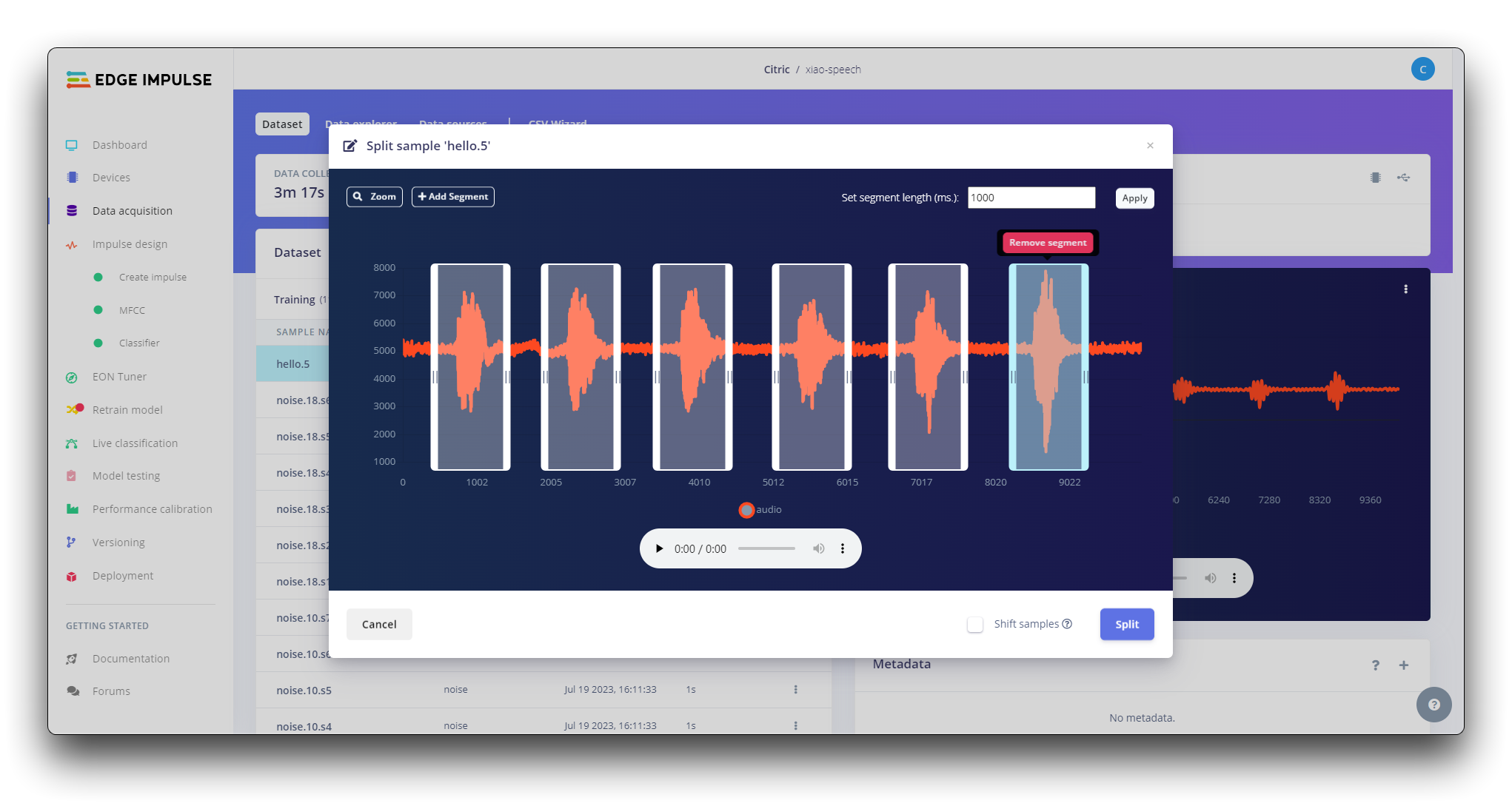
所有样品都应重复此程序。
脉冲信号接收原始数据,通过信号处理手段提取特征,再运用学习模块对新数据进行分类识别。
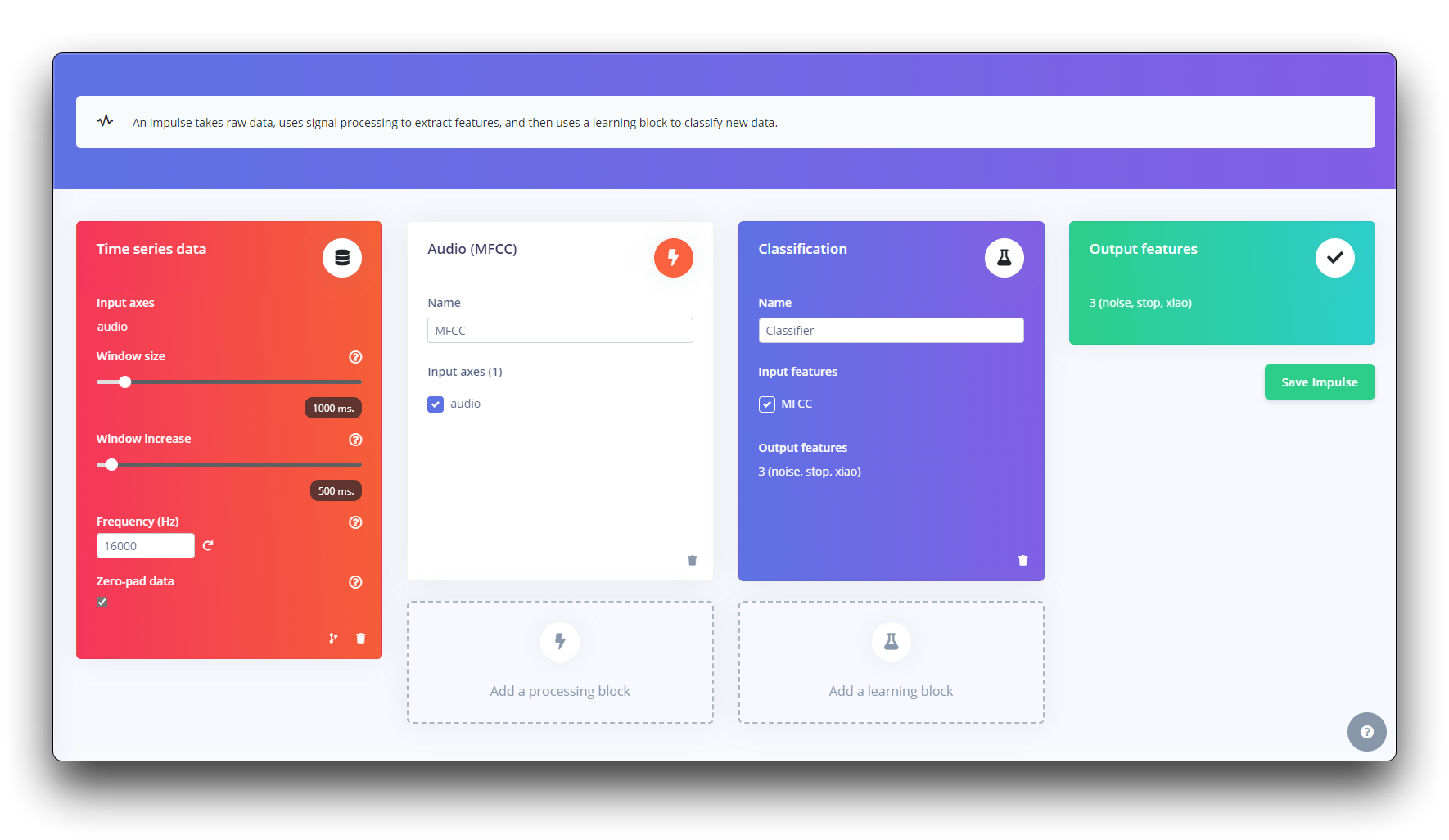
首先,我们将使用1秒的窗口获取数据点,增加数据,每500ms滑动该窗口。注意,设置了零填充数据选项。填充小于1秒的零样本是很重要的(在某些情况下,我减少了分割工具的1000毫秒窗口,以避免噪声和尖峰)。
每个1秒的音频样本应该经过预处理并转换为图像(例如,13 x 49 x 1)。我们将使用MFCC,它使用梅尔频率倒谱系数从音频信号中提取特征,这对人类声音非常有用。
接下来,我们选择KERAS进行分类,它通过使用卷积神经网络进行图像分类从头开始构建我们的模型。
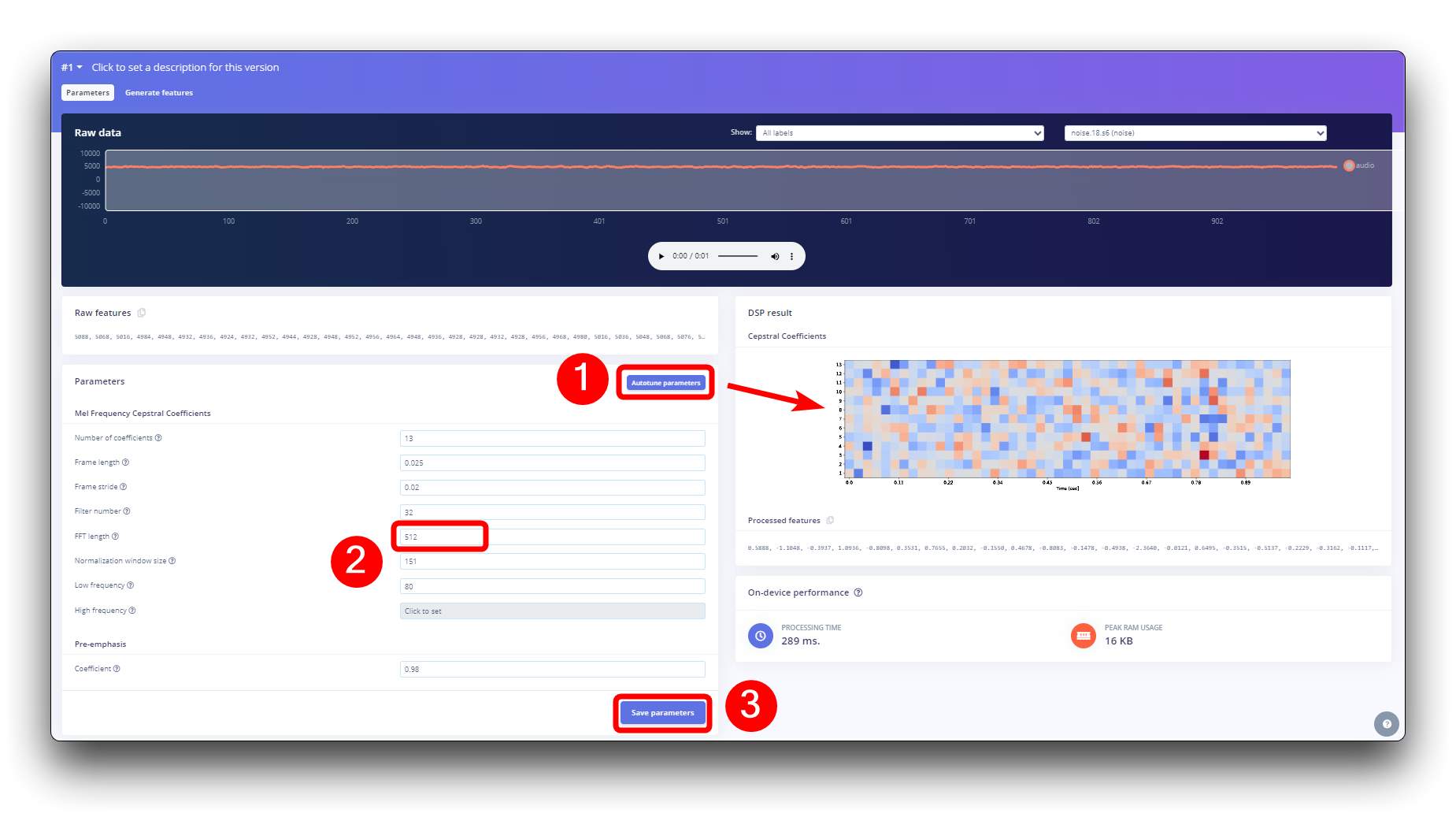
下一步是创建下一阶段要训练的图像。我们可以保留默认参数值,或者利用DSP的Autotuneparameters选项,我们将这样做。
我们将使用卷积神经网络(CNN)模型。基本架构由两个Conv1D + MaxPooling块(分别有8个和16个神经元)和0.25个Dropout定义。在最后一层,平展四个神经元后,每个类一个。
作为超参数,我们将有0.005的学习率和一个将被训练100个epoch的模型。我们还将包括数据增强,作为一些噪声。结果看起来还不错。

Edge Impulse将打包所有需要的库、预处理函数和训练好的模型,并将它们下载到您的计算机上。您应该选择Arduino库选项,并在底部选择Quantized (Int8)并按下按钮Build。
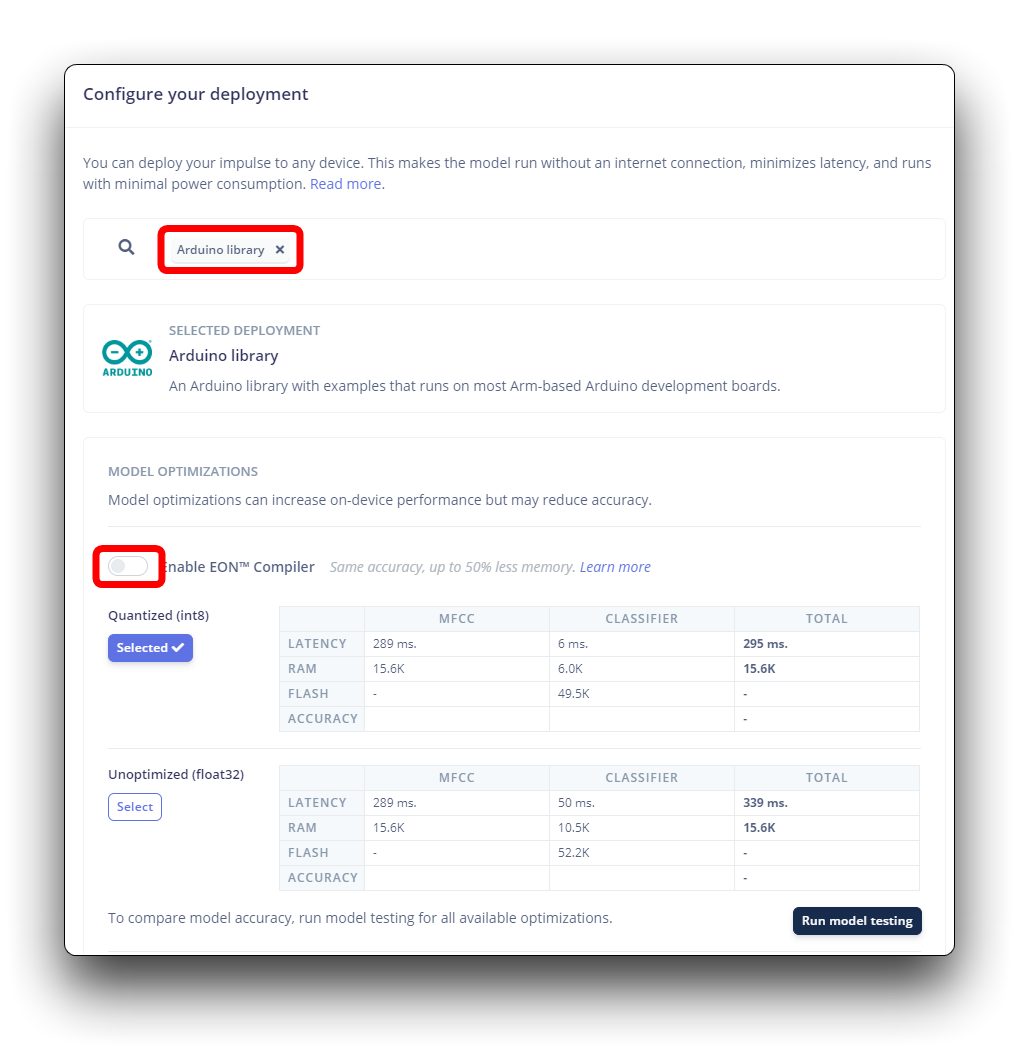
尽管Edge Impulse还没有发布使用ESP NN加速器的ESP32S3 SDK,但多亏了Dmitry Maslov,我们可以恢复并修复针对ESP32-S3的组装优化。这个解决方案还没有正式发布,一旦他们解决了与其他板的冲突,EI将会把它包含在EI SDK中。
:::提醒 目前,这只适用于非eon版本。因此,你还应该保持不选中启用EON编译器选项。 :::
选择Build按钮后,将创建一个Zip文件并将其下载到计算机。
在我们使用下载的库之前,我们需要启用ESP NN加速器。为此,您可以从项目GitHub下载初步版本,解压它,并将其替换为src/edge-impulse-sdk/移植/espressif/ESP-NN文件夹下的ESP NN文件夹,在您的Arduino库文件夹。
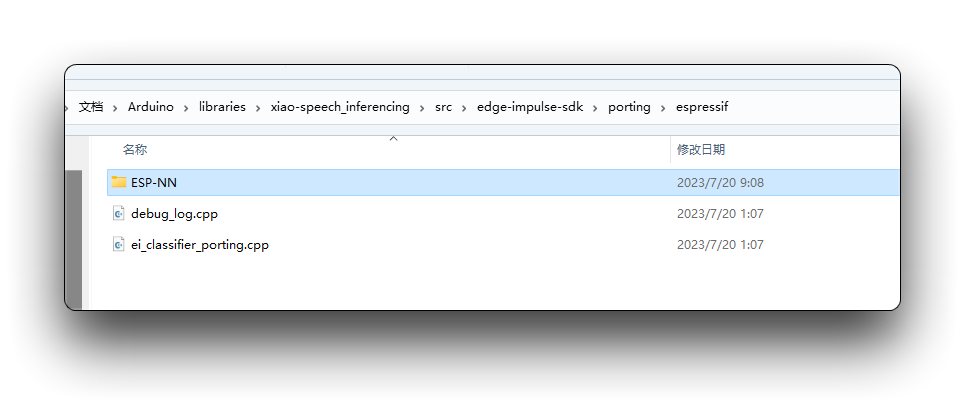
在您的Arduino IDE上,转到Sketch选项卡并选择选项Add .zip Library,并选择Edge Impulse下载的.zip文件。
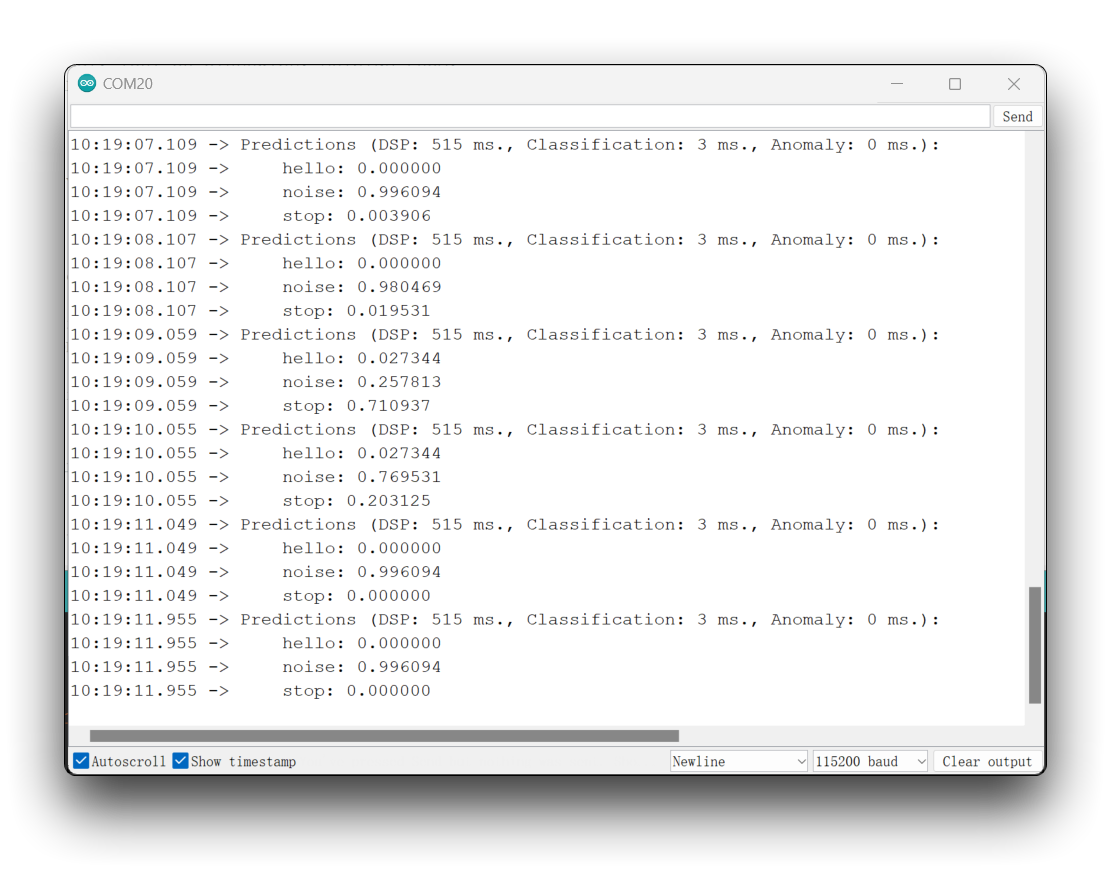
你可以在项目的GitHub上找到完整的代码。将草图上传到你的板上并测试一些真实的推论。
:::提示 在代码中导入的库需要更新为库的名称。亮起的逻辑也需要根据您实际训练的标签的顺序进行修改。 :::
/* Edge Impulse Arduino examples
* Copyright (c) 2022 EdgeImpulse Inc.
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*/
// If your target is limited in memory remove this macro to save 10K RAM
#define EIDSP_QUANTIZE_FILTERBANK 0
/*
** NOTE: If you run into TFLite arena allocation issue.
**
** This may be due to may dynamic memory fragmentation.
** Try defining "-DEI_CLASSIFIER_ALLOCATION_STATIC" in boards.local.txt (create
** if it doesn't exist) and copy this file to
** `<ARDUINO_CORE_INSTALL_PATH>/arduino/hardware/<mbed_core>/<core_version>/`.
**
** See
** (https://support.arduino.cc/hc/en-us/articles/360012076960-Where-are-the-installed-cores-located-)
** to find where Arduino installs cores on your machine.
**
** If the problem persists then there's not enough memory for this model and application.
*/
/* Includes ---------------------------------------------------------------- */
#include <XIAO-ESP32S3-KWS_inferencing.h>
#include <I2S.h>
#define SAMPLE_RATE 16000U
#define SAMPLE_BITS 16
#define LED_BUILT_IN 21
/** Audio buffers, pointers and selectors */
typedef struct {
int16_t *buffer;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static const uint32_t sample_buffer_size = 2048;
static signed short sampleBuffer[sample_buffer_size];
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static bool record_status = true;
/**
* @brief Arduino setup function
*/
void setup()
{
// put your setup code here, to run once:
Serial.begin(115200);
// comment out the below line to cancel the wait for USB connection (needed for native USB)
while (!Serial);
Serial.println("Edge Impulse Inferencing Demo");
pinMode(LED_BUILT_IN, OUTPUT); // Set the pin as output
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, SAMPLE_RATE, SAMPLE_BITS)) {
Serial.println("Failed to initialize I2S!");
while (1) ;
}
// summary of inferencing settings (from model_metadata.h)
ei_printf("Inferencing settings:\n");
ei_printf("\tInterval: ");
ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf(" ms.\n");
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));
ei_printf("\nStarting continious inference in 2 seconds...\n");
ei_sleep(2000);
if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {
ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
ei_printf("Recording...\n");
}
/**
* @brief Arduino main function. Runs the inferencing loop.
*/
void loop()
{
bool m = microphone_inference_record();
if (!m) {
ei_printf("ERR: Failed to record audio...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = { 0 };
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
int pred_index = 0; // Initialize pred_index
float pred_value = 0; // Initialize pred_value
// print the predictions
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
if (result.classification[ix].value > pred_value){
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// Display inference result
if (pred_index == 3){
digitalWrite(LED_BUILT_IN, LOW); //Turn on
}
else{
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
static void audio_inference_callback(uint32_t n_bytes)
{
for(int i = 0; i < n_bytes>>1; i++) {
inference.buffer[inference.buf_count++] = sampleBuffer[i];
if(inference.buf_count >= inference.n_samples) {
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
static void capture_samples(void* arg) {
const int32_t i2s_bytes_to_read = (uint32_t)arg;
size_t bytes_read = i2s_bytes_to_read;
while (record_status) {
/* read data at once from i2s - Modified for XIAO ESP2S3 Sense and I2S.h library */
// i2s_read((i2s_port_t)1, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
if (bytes_read <= 0) {
ei_printf("Error in I2S read : %d", bytes_read);
}
else {
if (bytes_read < i2s_bytes_to_read) {
ei_printf("Partial I2S read");
}
// scale the data (otherwise the sound is too quiet)
for (int x = 0; x < i2s_bytes_to_read/2; x++) {
sampleBuffer[x] = (int16_t)(sampleBuffer[x]) * 8;
}
if (record_status) {
audio_inference_callback(i2s_bytes_to_read);
}
else {
break;
}
}
}
vTaskDelete(NULL);
}
/**
* @brief Init inferencing struct and setup/start PDM
*
* @param[in] n_samples The n samples
*
* @return { description_of_the_return_value }
*/
static bool microphone_inference_start(uint32_t n_samples)
{
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
if(inference.buffer == NULL) {
return false;
}
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
// if (i2s_init(EI_CLASSIFIER_FREQUENCY)) {
// ei_printf("Failed to start I2S!");
// }
ei_sleep(100);
record_status = true;
xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void*)sample_buffer_size, 10, NULL);
return true;
}
/**
* @brief Wait on new data
*
* @return True when finished
*/
static bool microphone_inference_record(void)
{
bool ret = true;
while (inference.buf_ready == 0) {
delay(10);
}
inference.buf_ready = 0;
return ret;
}
/**
* Get raw audio signal data
*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr)
{
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
/**
* @brief Stop PDM and release buffers
*/
static void microphone_inference_end(void)
{
free(sampleBuffer);
ei_free(inference.buffer);
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor."
#endif其原理是,只要检测到关键字HELLO, LED就会亮起。同样的,除了打开LED,这也可以成为外部设备的“触发器”,就像我们在介绍中看到的那样。
特别感谢**MJRoBot (Marcelo Rovai)**)关于XIAO ESP32S3 Sense access to Edge Impulse的教程内容。原文非常详细,包含了很多关于机器学习的知识。
如果你想阅读这篇文章的原始内容,你可以直接向下滚动到原始文章。
MJRoBot还有很多关于XIAO ESP32S3的有趣项目。
感谢您选择我们的产品!我们在这里为您提供不同的支持,以确保您在使用我们产品的过程中尽可能顺利。我们提供多种沟通渠道,以满足不同的偏好和需求。