
Stemming and lemmatization are methods used by search engines and chatbots to analyze the meaning behind a word. Stemming uses the stem of the word, while lemmatization uses the context in which the word is being used.
Stemming is one of the most common data pre-processing operations we do in almost all Natural Language Processing (NLP) projects. Stemming algorithms work by cutting off the end or the beginning of the word, taking into account a list of common prefixes and suffixes that can be found in an inflected word. This indiscriminate cutting can be successful in some occasions, but not always, and that is why we affirm that this approach presents some limitations.
This approach does not require any language info. Some example are given below:
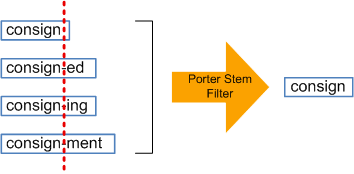
If we have the words — ask, asking and asked — we can apply stemming algorithms to get the root word — ask. Stemming is as simple as that. But (there’s always a but), unfortunately, it’s not as simple as that. We will some times have complications. And these complications are called over stemming and under stemming.
Over stemming is the process where a much larger part of a word is chopped off than what is required, which in turn leads to two or more words being reduced to the same root word or stem incorrectly when they should have been reduced to two or more stem words. For example, university and universe. Some stemming algorithms may reduce both the words to the stem univers, which would imply both the words mean the same thing, and that is clearly wrong. So we have to be careful when we select a stemming algorithm, and when we try to optimize the model.
In under stemming, two or more words could be wrongly reduced to more than one root word, when they actually should be reduced to the same root word. For example, consider the words “data” and “datum.” Some algorithms may reduce these words to dat and datu respectively, which is obviously wrong. Both of these have to be reduced to the same stem dat.
Lemmatization is a text normalization technique used in Natural Language Processing (NLP), that switches any kind of a word to its base root mode. Lemmatization is responsible for grouping different inflected forms of words into the root form, having the same meaning.Lemmatization is a vital part of Natural Language Understanding (NLU) and Natural Language Processing (NLP). It plays critical roles both in Artificial Intelligence (AI) and big data analytics. Lemmatization, on the other hand, takes into consideration the morphological analysis of the words. To do so, it is necessary to have detailed dictionaries which the algorithm can look through to link the form back to its lemma. It require the knowledge of the language. For example ate is a past word the lemmatization will convert it into the eat word.

Here are some of the other ways and areas in which lemmatization is used:
Sentiment analysis refers to an analysis of people’s messages, reviews, or comments to understand how they feel about something. Before the text is analyzed, it is lemmatized.
Lemmatizing is used for the purpose of mapping documents to common topics and displaying search results. To do so, it indexes when documents are increasing to large numbers.