
该项目使用PaddleX提供的图像分类模型,在 kaggle 驾驶员状态检测数据集进行训练;
训练得到的模型能够区分驾驶员正常驾驶、打电话、喝水等等不同动作,准确率为0.979;
并使用PaddleLite进轻量级推理框架进行部署;
该项目使用CPU环境或GPU环境运行,PaddleX会自动选择合适的环境;
- PaddleX工具简介;
- 数据集简介;
- 定义数据加载器;
- 定义并训练模型;
- 评估模型性能;
- 使用PaddleLite进行模型部署;
- 总结

PaddleX简介:PaddleX是飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通深度学习开发全流程,并提供简明易懂的Python API,方便用户根据实际生产需求进行直接调用或二次开发,为开发者提供飞桨全流程开发的最佳实践。目前,该工具代码已开源于GitHub,同时可访问PaddleX在线使用文档,快速查阅读使用教程和API文档说明。
PaddleX代码GitHub链接:https://github.com/PaddlePaddle/PaddleX/tree/develop
PaddleX文档链接:https://paddlex.readthedocs.io/zh_CN/latest/index.html
PaddleX官网链接:https://www.paddlepaddle.org.cn/paddle/paddlex

数据集地址:https://www.kaggle.com/c/state-farm-distracted-driver-detection

该数据集由kaggle提供,共包括十个类别:
'c0': 'normal driving',
'c1': 'texting-right',
'c2': 'talking on the phone-right',
'c3': 'texting-left',
'c4': 'talking on the phone-left',
'c5': 'operating the radio',
'c6': 'drinking',
'c7': 'reaching behind',
'c8': 'hair and makeup',
'c9': 'talking to passenger'
# 解压数据集(注意要根据环境修改路径——
!unzip /home/aistudio/data/data35503//imgs.zip -d /home/aistudio/work/imgs
!cp /home/aistudio/data/data35503/lbls.csv /home/aistudio/work/安装paddleX和1.7.0版本的paddlepaddle(这是由于paddlex并不支持最新版本)
!pip install paddlex -i https://mirror.baidu.com/pypi/simple
!pip install paddlepaddle-gpu==1.7.0.post107 -i https://mirror.baidu.com/pypi/simpleimport os
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.chdir('/home/aistudio/work/')# jupyter中使用paddlex需要设置matplotlib
import matplotlib
matplotlib.use('Agg')
import paddlex as pdx这里主要是通过 pdx.datasets.ImageNet 类定义用于识别任务的数据加载器;
import paddlehub as hub
import paddle.fluid as fluid
import numpy as np
base = './imgs/'
datas = []
for i in range(10):
c_base = base+'train/c{}/'.format(i)
for im in os.listdir(c_base):
pt = os.path.join('train/c{}/'.format(i), im)
line = '{} {}'.format(pt, i)
# print(line)
datas.append(line)
np.random.seed(10)
np.random.shuffle(datas)
total_num = len(datas)
train_num = int(0.8*total_num)
test_num = int(0.1*total_num)
valid_num = total_num - train_num - test_num
print('train:', train_num)
print('valid:', valid_num)
print('test:', test_num)
with open(base+'train_list.txt', 'w') as f:
for v in datas[:train_num]:
f.write(v+'\n')
with open(base+'test_list.txt', 'w') as f:
for v in datas[-test_num:]:
f.write(v+'\n')
with open(base+'val_list.txt', 'w') as f:
for v in datas[train_num:-test_num]:
f.write(v+'\n')
with open(base+'labels.txt', 'w') as f:
for i in range(10):
f.write('ch{}\n'.format(i))train: 17939
valid: 2243
test: 2242
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])train_dataset = pdx.datasets.ImageNet(
data_dir='data',
file_list='data/train_list.txt',
label_list='data/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='data',
file_list='data/val_list.txt',
label_list='data/labels.txt',
transforms=eval_transforms)2020-05-18 07:57:03 [INFO] Starting to read file list from dataset...
2020-05-18 07:57:03 [INFO] 17939 samples in file data/train_list.txt
2020-05-18 07:57:03 [INFO] Starting to read file list from dataset...
2020-05-18 07:57:03 [INFO] 2243 samples in file data/val_list.txt
num_classes = len(train_dataset.labels)
print(num_classes)10
这里使用 MobileNetv3 进行训练;
MobileNetv3详细介绍可以看我的这一篇博客:
https://blog.csdn.net/weixin_44936889/article/details/104243853
这里简单复述一下:


琦玉老师 和 龙卷(阿姨)小姐姐 告诉我一个道理——画风越简单,实力越强悍;
这篇论文只有四个词,我只能说:不!简!单!
为了使深度学习神经网络能够用于移动和嵌入式设备,
MobileNet 提出了使用深度分离卷积减少参数的方法;
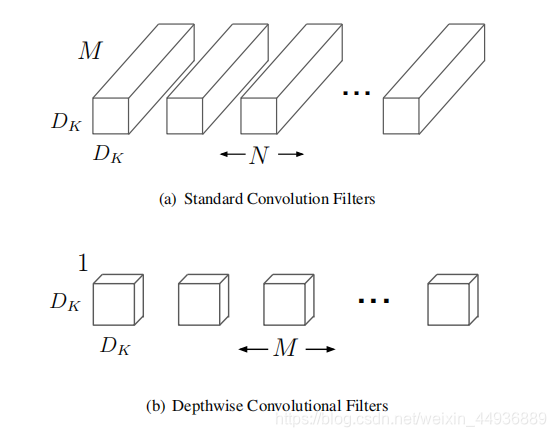
即先将特征层的每个channel分开,然后分别做卷积,这样参数大约少了N倍(N是输出特征层的channel数);
就是1×1卷积,用于融合不同channel的特征;
- 使用了两个黑科技:NAS 和 NetAdapt 互补搜索技术,其中 NAS 负责搜索网络的模块化结构,NetAdapt 负责微调每一层的 channel 数,从而在延迟和准确性中达到一个平衡;
- 提出了一个对于移动设备更适用的非线性函数
$h-swish[x]=x\frac{ReLU6(x+3)}{6}$ ; - 提出了
$MobileNetV3-Large$ 和$MobileNetV3-Small$ 两个新的高效率网络; - 提出了一个新的高效分割(指像素级操作,如语义分割)的解码器($decoder$);
对于有较大计算能力的平台,作者提出了 MobileNetV3-Large,并使用了跟 MnanNet-A1 相似的基于 RNN 控制器和分解分层搜索空间的 NAS 搜索方法;
对于有计算能力受限制的平台,作者提出了 MobileNetV3-Small;
这里作者发现,原先的优化方法并不适用于小的网络,因此作者提出了改进方法;
用于近似帕累托最优解的多目标奖励函数定义如下:
其中
作者在这里将权重因数
第二个黑科技就是 NetAdapt 搜索方法,用于微调上一步生成的种子模型;
NetAdapt 的基本方法是循环迭代以下步骤:
- 生成一系列建议模型(proposals),每个建议模型代表了一种结构改进,满足延迟至少比上一步的模型减小了
$\delta$ ,其中$\delta=0.01|L|$ ,$L$ 是种子模型的延迟;- 对于每一个建议模型,使用上一步的预训练模型,删除并随机初始化改进后丢失的权重,继续训练
$T$ 步来粗略估计建议模型的准确率,其中$T=10000$ ;- 根据某种度量,选取最合适的建议模型,直到达到了目标延迟
$TAR$ ;
作者将度量方法改进为最小化(原文是最大化,感觉是笔误):$\frac{\Delta Acc}{\Delta latency}$
其中建议模型的提取方法为:
- 减小 Expansion Layer 的大小;
- 同时减小 BottleNeck 模块中的前后残差项的 channel 数;
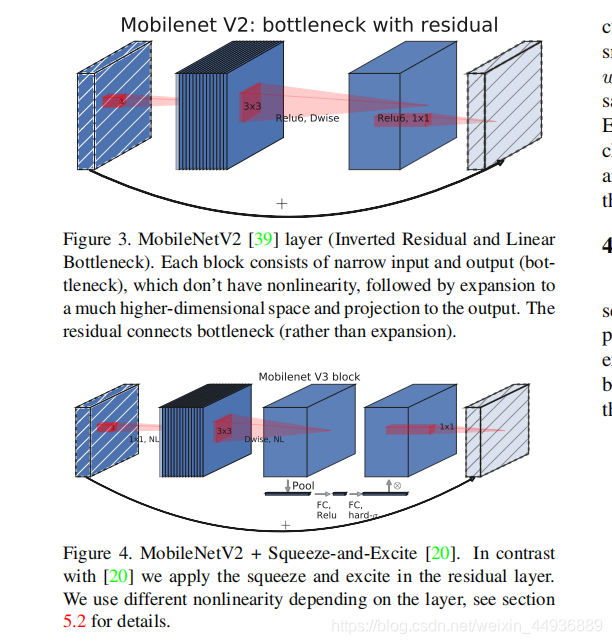
作者在 BottleNet 的结构中加入了SE结构,并且放在了depthwise filter之后;
由于SE结构会消耗一定的计算时间,所以作者在含有SE的结构中,将 Expansion Layer 的 channel 数变为原来的1/4;
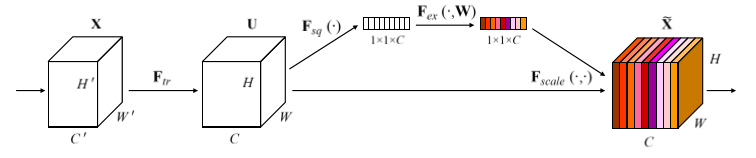
其中 SE 模块首先对卷积得到的特征图进行 Squeeze 操作,得到特征图每个 channel 上的全局特征,
然后对全局特征进行 Excitation 操作,学习各个 channel 间的关系,
从而得到不同channel的权重,最后乘以原来的特征图得到最终的带有权重的特征;
作者在研究时发现,网络开头和结尾处的模块比较耗费计算能力,因此作者提出了改进这些模块的优化方法,从而在保证准确度不变的情况下减小延迟;
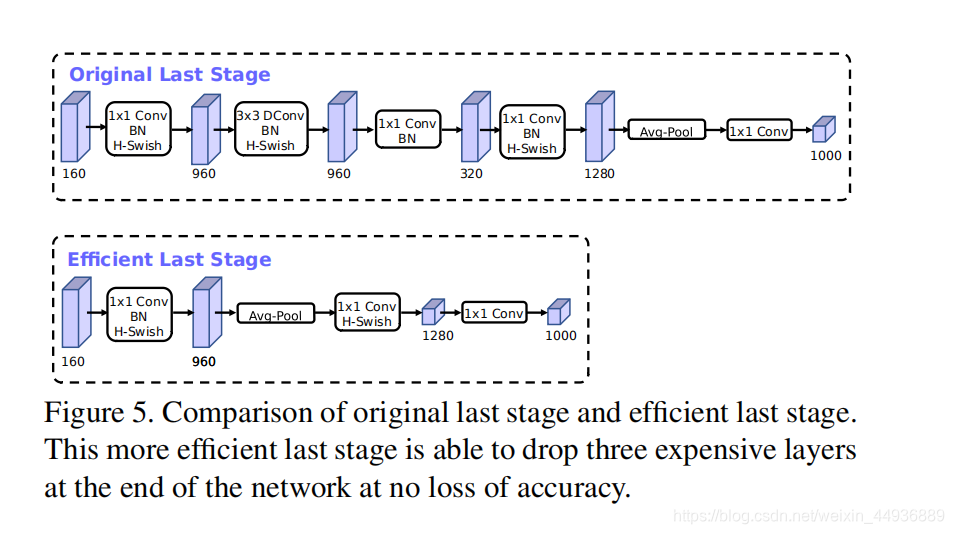
在这里作者删掉了 Average pooling 前的一个逆瓶颈模块(包含三个层,用于提取高维特征),并在 Average pooling 之后加上了一个 1×1 卷积提取高维特征;
这样使用 Average pooling 将大小为 7×7 的特征图降维到 1×1 大小,再用 1×1 卷积提取特征,就减小了 7×7=49 倍的计算量,并且整体上减小了 11% 的运算时间;
之前的 MobileNet 模型开头使用的都是 32 组 3×3 大小的卷积核并使用 ReLU 或者 swish 函数作为激活函数;
作者在这里提出,可以使用 h-switch 函数作为激励函数,从而删掉多余的卷积核,使得初始的卷积核组数从 32 下降到了 16;
之前有论文提出,可以使用
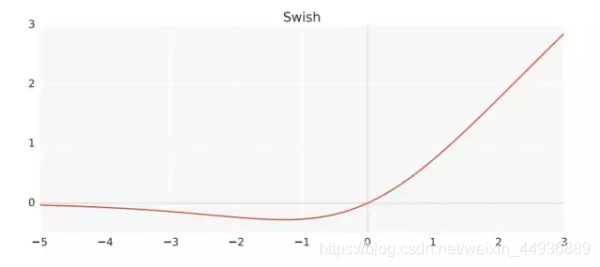
由于 sigmaoid 函数比较复杂,在嵌入式设备和移动设备计算消耗较大,作者提出了两个解决办法:
将 swish 中的 sigmoid 函数替换为一个线性函数,将其称为 h-swish:
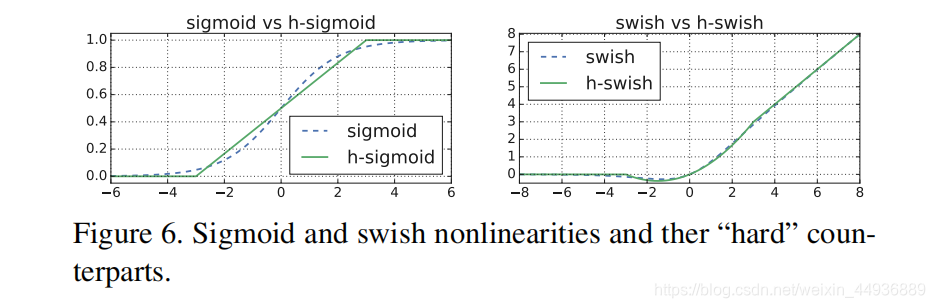
作者发现 swish 函数的作用主要是在网络的较深层实现的,因此只需要在网络的第一层和后半段使用 h-swish 函数;
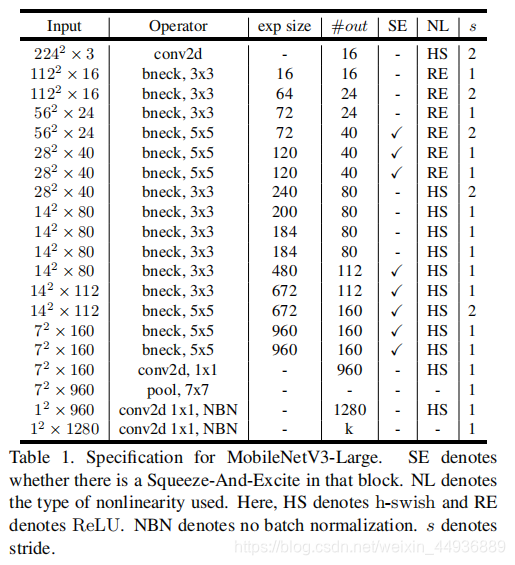
# 定义并训练模型
model = pdx.cls.MobileNetV3_small_ssld(num_classes=num_classes)
model.train(num_epochs=2,
train_dataset=train_dataset,
train_batch_size=32,
log_interval_steps=20,
eval_dataset=eval_dataset,
lr_decay_epochs=[1],
save_interval_epochs=1,
learning_rate=0.01,
save_dir='output/mobilenetv3')save_dir = 'output/mobilenetv3/best_model'
model = pdx.load_model(save_dir)
model.evaluate(eval_dataset, batch_size=1, epoch_id=None, return_details=False)2020-05-18 09:25:35 [INFO] Model[MobileNetV3_small_ssld] loaded.
2020-05-18 09:25:35 [INFO] Start to evaluating(total_samples=2243, total_steps=2243)...
100%|██████████| 2243/2243 [00:58<00:00, 38.38it/s]
OrderedDict([('acc1', 0.9790459206419974), ('acc5', 1.0)])
PaddleLite 是 paddle 提供的轻量级推理框架;

{kind=link}
文档地址:
https://paddle-lite.readthedocs.io/zh/latest/index.html#
简介: Paddle-Lite 框架是 PaddleMobile 新一代架构,重点支持移动端推理预测,特点为高性能、多硬件、轻量级 。
支持PaddleFluid/TensorFlow/Caffe/ONNX模型的推理部署,目前已经支持 ARM CPU, Mali GPU, Adreno GPU, Huawei NPU 等多种硬件,
正在逐步增加 X86 CPU, Nvidia GPU 等多款硬件,相关硬件性能业内领先。
# 进行模型量化并保存量化模型
pdx.slim.export_quant_model(model, eval_dataset, save_dir='./quant_mobilenet')
print('done.')# 加载模型并进行评估
quant_model = pdx.load_model('./quant_mobilenet')
quant_model.evaluate(eval_dataset, batch_size=1, epoch_id=None, return_details=False)-
使用PaddleX在驾驶员状态识别数据集训练了MobileNetv3模型;
-
使用PaddleLite实现了模型的轻量化部署;
北京理工大学 大二在读
感兴趣的方向为:目标检测、人脸识别、EEG识别等
将会定期分享一些小项目,感兴趣的朋友可以互相关注一下:主页链接
也欢迎大家fork、评论交流