打开Go语言的官网我们可以看到这样一句话:
Go是一种开源编程语言,可以轻松构建简单,可靠,高效的软件。
显然这句话中有三个关键字:简单,可靠,高效。
Go语言的哲学,是简简单单的一句话:
Less is more.
Less is more. 这句话来源于Rob Pike(Go语言的创造者之一)在2012年的6月份的演讲Less is exponentially more.,这个演讲直译成中文的意思是:“少是指数级的多”,意译过来则是大道至简。
Go语言相信越是简单的东西(语义,规则等等...)越是比复杂的东西更加强大。(事实上,开发Go语言的契机,正是Google公司请了一些人,来给员工讲解C++ 0x相比较之前的一些新的特性。Rob和Ken还有Robert也在听讲的人群当中。它们认为C++想要让自身变得更好的途径不应该是增加更多的特性,而是应该减少不必要的东西。)
Go想要这样做:使用足够简单的方式来解决一切问题。并且它做到了。Go语言的语法规范和C++相比简直不值一提。
扩展阅读:
在Go语言被设计的第一天,就有这样一个想法:以C语言作为起点。(虽然最后没这么做)
当程序员使用Go语言进行编程时,不需要像C语言的程序员那么提心吊胆去用心管理内存(这么说会显得使用其他编程语言的程序员不用心,但是事实上和C语言的管理内存相比,其他的工作真的只是小儿科)。Go语言会自动帮程序员管理内存,当然,程序员也还是要去在意类似于空指针,边界条件的判断等等(不用心管理内存并不代表不用脑子!)。
当然这个世界上的能够自动管理内存的编程语言不止一种,但是在当今的世界上对于内存不安全的语言是没有活路的。
扩展阅读:
也许Go语言是你人生中接触的第一门编程语言(我相信在不久的将来这个会变成现实的!)但是在现在(2019年)还是不太可能的,也就是说绝大多数人是因为Go语言的特性,或者说不得已的需求而接触的这门编程语言。
如果你是因为被Go语言的特性所吸引,那么你一定听说过一下几个关键词:静态强类型,可编译,高并发。
静态语言所带来的好处是在开发时的高效:编辑器可以有足够好的代码补全功能,很好的语法和类型检查,虽然和动态弱类型语言相比较,短期的开发时间较长,但是比动态语言更适合开发大型项目,且更加利于后期的维护,也就是说从长远的角度看是效率更好的。
以前的单CPU时代,人们尚且知道划分CPU时间片来进行并发(不是真正的并行计算,而是宏观上的并发),在计算能力更加发达的今天,多计算单元、多核心、多机器已经是司空见惯的模式了,在这个时候,Go语言继承自CSP、扎根于语言深部的高并发特性使之能够被称为是“二十一世纪编程语言”。而关于并发的部分会在后面介绍。
扩展阅读:
不怎么用Windows,所以暂时只有Linux/Ubuntu 18.04的安装
① 获取最新的golang安装源,并且更新到apt中
add-apt-repository ppa:longsleep/golang-backports
② apt更新
apt-get update
③ 安装golang
sudo apt-get install golang-go
④ 使用version查看版本
go version
GOROOT: Go语言编译、工具、标准库等的安装路径。 GOPATH:Go语言的工作目录。
go/
├── bin
├── pkg
└── src
├── github.com
│ ├── Muxi-X
│ ├── ...
│ └── ShiinaOrez
│ ├── goProject1 <- 你的仓库
│ └── ...
├── golang.org
└── ...众所周知,第一个例子永远是Hello(World之类的),我们也是一样的。
你的代码应该位于golang的工作目录下
创建一个文件:hello.go或者叫什么都无所谓,只要是.go文件就可以。
文件的内容如下:
package main
import "fmt"
func main() {
fmt.Println("Hello, golang!")
}保存,关闭,在文件目录下运行以下命令来直接运行:
go run hello.go
或者使用编译成可执行文件的形式来运行:
go build -o hello && ./hello
然后会获得以下输出:
Hello, golang!package关键字用来说明本文件是属于哪个包的,Go语言默认main包为运行或者编译的目标包。不然的话会引起以下错误:
go run: cannot run non-main packageimport关键字用于导入我们运行时需要的包,在下文中使用了fmt.Println方法,所以需要导入fmt包。
然后我们使用func关键字声明了一个函数main,这是一个没有参数也没有返回值的函数,它将是程序的入口。
在main函数中我们调用了fmt.Println()方法,输入了一个字符串为参数。
扩展阅读:
在我们的每一段程序的开头, 都要使用package关键字来声明这段代码属于哪个包, 但是关于Go语言的包管理机制我们还没有探讨过, 因此在这一节我们讲一下关于Go语言的包(package):
Go语言的代码一般位于$GOPATH/src下, Go语言的标准包可以直接引用, 第三方的包和自己定义的包必须放在这个目录下才可以引用.
比如: 如果我们要使用Go语言官方的strings包中的函数, 那么我们需要在代码中这样去引用:
import (
"strings"
)但是比如我们要引用Go语言中比较好用的ORM包: gorm的时候, 作为一个第三方的包, 我们应该这样去引用:
import (
"github.com/jinzhu/gorm"
)当然, 这都是使用绝对路径的引用方式, 我们还可以使用相对路径的引用方式: 使用./, ../这种方式去进行包的引用.
在引用之后, 我们就可以使用包名.的方式去使用包中的方法和变量了, 比如使用Go语言中的sort包的Ints方法:
sort.Ints(integerSlice)但是有的时候我们引用的包名会有冲突的状况, 又或者是这个包的名字太长, 写起来不太方便, 总之各种原因让我们需要给他一个别名, 那么这个时候就应该使用这样的方式去进行引用:
import (
S "sort" // import nickName "packagePath"
)
// ...
S.Ints(integerSlice)
// ...或者可以直接将包中的内容和当前代码做一个合并, 让我们可以直接调用:
import (
. "sort"
)
// ...
Ints(integerSlice)
// ...如果我们只是想调用一个包的初始化函数, 而并不会使用其中的任何一个其他的函数或者变量, 我们应该怎么办呢? 相信大家在建立数据库连接时都是这样去做的, 为了应对这样的情况, 在Go语言下可以使用下划线_来导入一个包:
import (
_ "packagePath" // 仅执行初始化函数 init()
)我们现在知道了该如何对包进行引用, 也就是对于import关键字的用法. 那么Go语言是以一种怎样的顺序去加载包的呢? 在这一节就来讲一下这个问题:
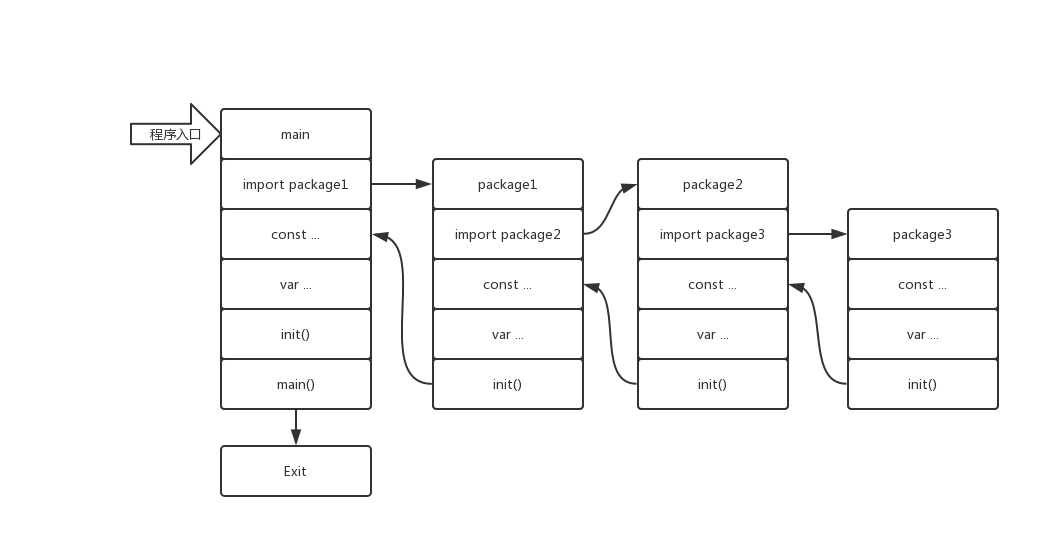
所以我先画了一个图在这里, 从这里大家可以看到包加载的基本过程:
- 在加载时, 如果有引入其他的包, 那么进入该包的加载过程
- 如果对于引入的包的加载完毕了, 那么开始进行常量的声明
- 常量的声明后是变量的声明
- 如果该包有init()函数, 那么执行init()函数
- 如果该包是main包, 那么在init()之后执行main()函数
其实加载的主要思想很简单, 就是记住加载的顺序就好了.
封装是面向对象编程思想中很重要的一部分, 封装的具体含义指隐藏具体的实现细节, 仅暴露出可以调用的接口和方法.
具体关于封装的细节就不详谈了, 因为一般教科书或者网络上关于封装的描述都是基于类的, 而Go语言的面向对象的实现不太一样, 因此不再赘述, 这个小节只关心如何实现封装, 也就是如何实现字段和方法对外的隐藏.
在Go语言中区分是否暴露给其他包的标志是名称是否以大写字母开头, 如果是以大写字母开头的类型, 变量, 常量或者函数, 是可以在当该包被其他包导入的时被暴露的. 反之则只能够在该包中进行使用.
同样的, 一个类型上绑定的方法, 如果是以大写字母开头, 则是可以被调用的. 类型中的字段也是一样的.
最后, Go语言中有大量的内置的包和第三方开发的包, 请大家不要重复造轮子, 灵活使用别人的轮子会事半功倍.
一般来说,强类型语言中的变量是盒子,而弱类型语言中的变量则多数是标签。
因为强类型,所以一个变量能够分配的内存空间相对来说是便于计算的,因此语言内部会在内存中为你的变量开辟一块内存空间,而这个内存空间的地址会被映射为变量名,而内存空间内存放的数据是什么并不被关心,就像是一个盒子,里面放了不同的数据。
在Go语言中,声明一个新变量的方式有两种:var关键字和:=运算符。
1. 使用var关键字:
var hello string // 声明一个变量hello,类型为string,默认值为string的零值,也就是空字符串。
var hello string = "Hello, golang!"
var hello, world string = "Hello", "World" // 可以同时声明多个变量并且初始化
var hello = "Hello, golang!" // 根据右侧值的类型来推断变量类型2. 使用:=运算符
:=运算符用于简化新变量声明的步骤,不希望程序员每次用到新变量都去使用var来声明。因此:=运算符只能用于新变量的声明。
hello := "Hello, golang!" // 等价为 var hello = "Hello, golang",也会进行类型的推断
var hello string; hello := "Hello, golang!" // 会报错,即使声明的变量未曾使用过,也不是一个新变量,因此不能使用 := 运算符
hello, err := someFunc() // 便捷地接收函数返回的结果,前提也是一定是新的变量名Go语言的类型系统非常的简单且多变,不同的组合形式可以产生成百上千上万的类型,也就是说,通过不同方式的组合,Go语言中可以有无数个类型。
1. 基本的数据类型
| 类型名称 | 标识符 | 描述 |
|---|---|---|
| 布尔类型 | bool | 布尔值仅有true和false两种值 |
| 字符串类型 | string | 在Go语言中的字符串是不可变的常量 |
| 字节类型 | byte | 字节类型,实质上是uint8 |
| Unicode字符类型 | rune | 实质上是int32类型 |
| 有符号整数类型 | int, int8, int16, int32, int64 | int是基于具体架构的类型,后面的数字代表在内存中所占的位数 |
| 无符号整数类型 | uint, uint8, uint16, uint32, uint64 | uint是基于具体架构的类型,后面的数字代表在内存中所占的位数 |
| 浮点数类型 | float32, float64, complex64, complex128 | float32和float64都是遵循IEEE-754标准,数字依然表示位数,而complex64和complex128分别表示32位和64位的实数和虚数 |
2. 派生类型
2.1 指针类型(pointer)
Go语言是内存安全的,但是开放了灵活的指针给程序员使用,又不涉及复杂的指针运算。
在Go语言中的类型都有对应的指针类型,以*为标识符,例如:
var stringPointer *string
var intPointer *int指针类型的变量存储着内存地址。可以使用&取地址符来获取一个变量的地址。
Go语言中的空指针为nil。
2.2 数组类型(array)
Go语言中的任意类型都可以有相应确定长度的数组类型:
var fourStringArray [4]string // 一个长度为4的字符串数组
var int2dArray [4][5]int // 一个长度为4的 长度为5的int数组 的数组,也就是一个二维数组值得注意的是:这里的数组名不代表数组的开始地址!,需要使用&来取得首地址,也不建议对它进行指针运算。
定长的原因很简单:可以很好的确定内存空间的大小。
2.3 结构化类型(struct)
结构体,没有人会陌生,如果这不是你接触的第一门语言的话。
结构化的自定义类型被广泛应用于组织和传递数据,以及Go语言的面向对象也是以结构体作为支撑的。 例子:
var myName struct {
FirstName string // 字段名在前,类型名称在后
LastName string
} // 声明了一个结构体变量
// 定义一个新的结构体类型
type Name struct {
FirstName string
LastName string
}
// 如何初始化一个结构体变量
myName := Name {FirstName: "Shiina", LastName: "Mashiro"} // 最后不需要添加逗号
myName := Name {
FirstName: "Shiina",
LastName: "Mashiro, // 需要添加逗号
}
// 使用某个字段
lastName := myName.LastName也可以用组合的方式定义新的结构体:
type Info struct {
Tel string
Address string
}
type Detail struct {
Name
Info
}
Go语言中没有类 (class),但是会给相应的类型绑定方法,具体的形式会在后面面向对象的部分进行讲解。
2.4 通道类型(channel)
如果你学习过CSP,或者你是仰慕Go语言的并发语义和并发模式而来,那么你一定知道什么是通道(channel):通道是一个可以带有一定缓冲的队列,用于goroutine之间的通信。
通过一个例子来看一下如何使用(channel可是Go语言的特色之一啊,睁大眼睛):
func tryChannel() {
ch := make(chan int, 10) // 使用make函数构造一个缓冲容量为10的int通道
for i:=0; i<10; i++ { ch<- i } // 循环的向通道中塞十个数据
for value := range ch { // 遍历通道(循环的取出数据)
fmt.Println(value)
if value == 9 { break } // 这里如果不结束循环的话,会引发DeakLock,具体的原因会在后面讲解,现在只是为了介绍类型
}
close(ch) // 手动关闭通道
}如果在调用make()方法的时候,没有传入通道的缓冲容量,则默认为0,也就是说同时传入和传出,否则的话只会阻塞。如果程序中的所有goroutine都阻塞了,则会触发DeadLock,这也解释了例子中为什么要中断循环。
channel是具有队列的性质的,也就是FIFO, First in First out,因此把channel当做队列数据结构来用的情况也是很多的(但是我更建议去手动实现和管理)。
2.5 函数类型(function)
在越来越多的支持面向对象编程语言中,函数被当做一等公民看待。因此也就有专门的函数对象,变量,类型。
函数变量的类型由几个因素组成:函数名、参数、返回值
例子:
type compareFunction func(int, int) int
var min compareFunction = func(x, y int) int {
if x < y {
return x
}
return y
}
fmt.Println(compareFunction(10, 20))同时函数当然也可以作为参数传入函数。
func less(x, y int, comp func(int, int) bool) {
if comp(x, y) {
return x
}
return y
}
func tryLess() {
comp := func(x, y int) bool { return x < y }
fmt.Println(less(10, 20, comp))
}匿名函数的使用等等,会在后面进行介绍。
2.6 切片类型(slice)
人们总是抱怨数组的定长不够方便,而在C++ STL的vector出现后,大家就开始疯狂使用这个名为动态数组的东西,还可以自己开辟内存空间,这真是太好用了!
动态数组出现之后,人们又在其基础之上发明了切片(slice),不仅长度可变,而且有很多利用[start:end:step]进行的操作。最典型的便是Python中的列表。
但是这是Go语言,所以我们来看看Go语言的切片:
type intSlice []int // 在类型定义上,和数组除了长度没有区别
func trySlice() {
ints := intSlice{1, 2, 3, 4, 5}
fmt.Println(len(ints), ints[1:3])// 使用len方法获取切片的长度,也可以使用cap方法获取切片的容量
anotherInts := make(intSlice, 5) // 使用make方法创建一个长度为5的切片
copy(anotherInts, ints) // 使用copy方法复制内容到新切片
fmt.Println(append(ints, 6)) // 使用append方法增加新元素到切片,但是不是原地操作
fmt.Println(append(ints, anotherInts...))
}2.7 接口类型(interface)
如果说能让程序员在这个强类型强到天上的语言中找到什么慰藉的,大概就是强大的接口了,至于接口是什么,可以看这个
定义接口的方式和定义结构体的方式相似:
type HumanNature interface {
Speak() string // 接口匹配方法
See(interface{}) // 空接口默认可以匹配所有的类型
}接口的知识太多了,放在以后赘述。
2.8 映射类型(map)
映射,很方便,很实用。因为查询的效率,无序性等等。
map的派生类型是由键类型和值类型共同决定的。常见的构建方式是使用make()方法。
func tryMap() {
newMap := make(map[int]string)
newMap[1] = "C" // 插入键值对
if value, have := newMap[2]; have { // 通常用这种方式检查是否有对应的键值对
// ...some code here
} else { fmt.Println("Key: 2 Not Found!") }
newMap[2] = "C++"; newMap[3] = "Java"
for key, value := range newMap { // 通过这种形式遍历map
fmt.Println(key, "-", value)
}
delete(newMap, 1) // 通过内置的delete方法来删除键值对
}map是使用Go语言时非常常用的类型,不论是编写并发代码还是正常代码,都是非常重要的。
扩展阅读:
我的介绍不尽详细,我个人的疏忽可能会导致这个教程的不正确性和不稳定性,欢迎阅读者提出issue。 还有,我饿了,就先写到这里吧。 -- 2019-09-04
众所周知的基本程序结构有顺序,分支,循环。
顺序就不再赘述,接下来讲解基本常见的分支和循环的书写和常用模式。
1. if-else
这是所有程序员都逃不开的结构,这实在是太重要了。if-else背后所潜藏的思想是非常深刻的。除了True,就是False。也就是对于全集取子集和补集,众所周知:世界是连续的,而计算机是离散的。而if-else背后的集合和真值的思想正是离散数学中的概念。
结论:if-else是将连续的世界离散化的重要发明。
普通的if-else长这个样子:
if condition_1 { // condition_1的值一定是布尔类型才可以,Go语言的if语句条件非常苛刻,不接受任何布尔类型之外的值
// ...some code here
} else if condition_2 {
// ...some code here
} else {
// ...some code here
}由于Go语言if语句的严苛,我们不可以这么写:
if 1 {
} else {
} // 错
if "string" {
} else {
} // 错
if !nil {
} else {
} // 错多个返回值的(或者需要预处理语句的)if-else是这个样子的:(之前的类型map介绍中已经提及过了)
if result, statu := function(); statu { // 在条件语句中的子语句是生效的,但是作用域和生命周期仅限于本语句的作用域
// ...some code here, using result // 使用分号``;``来分割判定的表达式和产生表达式值的语句
} else {
// ...some code here
}
// can not use result在Go语言的规范中,值是否存在,调用是否产生错误,产生的值都是习惯性的放在返回结果的最后一个,因此判断时的习惯也是一样的。
2. switch-case
为了避免众多的if-else if-else来进行大量的值的判断。人们发明了开关语句,也就是经典的switch-case-default语句。
大多数语言的switch-case语法都是相同的,但是在使用Go语言的switch-case语句时,需要小心,因为Go语言的switch-case语句是默认每个case后面自带break的,只是隐藏了而已。
switch value {
case value_1:
// ...some code here
// 这里有一个隐藏的break,也就是说不会继续执行下一个case
case value_2:
// ...some code here
break // 但是这里就算加了break也不会有问题
case value_3:
// ...some code here
fallthrough // fallthrough语句可以突破默认的break,可以继续进入下个case
default:
// ...some code here
}在Go语言中,大家都乐于使用在类型上没那么严格的接口,但是回过头来又要使用对应的强类型,这就要用到类型断言,在别的语言中也很常见的一种语法。而在Go语言这样常见的环境下,更是有对应的switch-type模式:
switch value := i.(type) {
case T:
// here v has type T
case S:
// here v has type S
default:
// no match; here v has the same type as i
}3. select-case
select-case是Go语言特有的语法,用于选择不同的通信操作。哪个通信操作最先不阻塞(收到结果),则最先进入哪个case,相比较switch-case而言,select-case的判断是无序的。语法如下:
select {
case communicationClause1:
// ...some code here
case communicationClause2:
// ...some code here
default:
// ...some code here
}在真实的使用场景中,常常和for一起组合为for-select使用,这些将会在后面介绍。
在Go语言中,表示循环的关键字就只有for。而for中可以有三种循环的模式:
正常的for循环:
正常的for循环遵循以下格式:
for initial; condition; after { // 和基本所有语言中的模式都是一样的
// ...some code here
}
for i:=0; i<10; i++ {} // 比如这样的while形式的for:
Go语言中的while循环也使用for关键字来实现:
for condition {
// ...some code here
}
死循环:
永真循环,也就是死循环,你可以使用while循环形式来实现,也可以用普通的形式来实现。当然也可以用Go语言提供的方式来实现。
for ;true; {} // 使用普通的for循环形式
for true {} // 使用while循环的形式实现
for {} // 使用Go语言提供的死循环的形式扩展阅读:
如果你是一个已经有了一定开发经验的程序员,那么你在接触Go语言之前会觉得编写并发代码是一件非常麻烦的事情:线程的管理,线程之间的通信等等,由于没有语言原语的支持,编写并发代码都是建立在大神编写的并发框架的代码之上的,正常情况下无法触碰到底层的具体逻辑和实现。
但是既然你现在开始接触神奇的Go语言了,你大可放下这方面的顾虑:因为Go语言提供了大量的并发原语来支持从零开始的并发代码开发。接下来就使用最简单的例子开始一个并发代码的编写:
package main
import "fmt"
func main() {
go func() { // 使用go关键字来开启一个goroutine
fmt.Println("Hello~Goroutine~")
}()
}上面这段代码已经是一个可以并发的代码了:如果你运行它,你会发现有时候并没有办法输出"HelloGoroutine"这段文字,这是因为打印文字和主函数已经是并发运行的了。
在Go语言中,包括主函数的程序运行在名为goroutine的轻量级进程上,而使用go关键字可以开启一个新的goroutine,从而达到并行的效果。因此在上面的一段代码中,主goroutine和匿名函数所在的goroutine是并行的,因此会存在两种情况:①主goroutine先结束 ②文字被先打印出来。
Goroutine是轻量级的,因此在Go语言的代码中你可以开启成千上万的goroutine,这在其他语言中是很难做到的。而进程之间的通信就交给Go语言的channel类型来完成(前面有介绍)。
package main
import "fmt"
func main() {
done := make(chan struct{}) // 定义一个空接口体类型的通道
go func() { // 开启一个goroutine
fmt.Println("Hello~Goroutine~")
done<- struct{}{} // 告诉done已经完成了工作
}() // 匿名函数声明的同时进行调用
<-done // 在通道内没有值之前,会堵塞在这里,因此程序不会在打印前结束
close(done) // 记得关闭通道
}现在使用了通道在goroutine之间进行通信,我们可以很好的来进行goroutine之间的同步了。
使用通信来进行goroutine之间的同步操作是基于CSP(通信顺序进程)的思想。但是很多人会更加习惯于去使用锁来进行同步,但是我认为锁是面向资源的,并不适合用于同步不同的线程或goroutine。
// 使用锁的例子
package main
import (
"fmt"
"sync"
)
func main() {
lock := new(sync.Mutex) // 声明一个锁
lock.Lock() // 锁上
go func() {
fmt.Println("Hello~Goroutine~")
lock.Unlock() // 开锁
}()
lock.Lock() // 锁上,但是在锁是打开的之前也会阻塞
}但是在同步goroutine的方面,还是使用通道来进行通信是比较推荐的方式。
扩展阅读:
函数的组成部分有名字, 形参列表, 可选的返回列表, 函数体:
func functionName(parameter-list) (result-list) {
// body
}我相信在前面写过的不少示例中,大家已经熟悉了这种声明方式。这是最普通,也是最基础的声明方法。但是Go语言中的函数还有和其他语言不同的地方。
当形参列表中的几个连续类型都相同时,可以选择只写一个类型标识符。
func min(x, y int) int
func min(x int, y int) int // 二者是完全相同的使用4种方式来声明具有同样函数签名的函数:
func add(x int, y int) int { return x+y } // 正常的声明
func sub(x, y int) (z int) { z = x-y; return } // 在返回值列表写好变量名,在返回时会自动返回该变量
func first(x int, _ int) { return x } // 下划线强调未使用
func zero(int, int) { return 0 } // 不使用参数的情况Go语言中的函数声明是非常灵活的。
和所有的语言一样。Go语言也支持函数的递归调用,也就是自身调用自身。
func dfs(node *TreeNode) { // 一个常见的对于二叉树的中序遍历的例子
if node.Left != nil {
dfs(node.Left)
} // 调用自身
// use this node
if node.Right != nil {
dfs(node.Right)
}
}整个例子,自己实现一下是很有趣的:
package main
import "fmt"
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func dfs(node *TreeNode) {
if node.Left != nil {
dfs(node.Left)
}
fmt.Println(node.Val)
if node.Right != nil {
dfs(node.Right)
}
}
func main() {
// construct a tree here
dfs(root)
}现在能够支持多个返回值的语言已经非常普遍了,如Python等等。Go语言也是支持多个返回值的,尤其是在错误处理方面,不像其他语言的try-except或者try-catch模式,而是直接在返回值中加入err的值。
下面是摘自strconv包的几个函数原型:
func ParseBool(str string) (bool, error)
func ParseFloat(s string, bitSize int) (float64, error)
func ParseInt(s string, base int, bitSize int) (i int64, err error)
func ParseUint(s string, base int, bitSize int) (uint64, error)可以很明显的看出来,由于从字符串解析不同的类型时,经常会出现无法解析,或者解析失败的情况,开发者们在内置函数的最后一个返回值放上了错误信息。而判定的方式也是非常简单的,因为error类型可以和nil进行比较:
_, err := strconv.Atoi("&&")
if err != nil {
// error handle
}所以当我们编写自己的函数的时候也要注意返回错误:
func yourHandler(str string) (int, error) {
val, err := strconv.Atoi(str)
if err != nil {
return 0, err // 将错误返回上层
}
return val, nil // 没有错误时返回nil
}函数变量在前面的派生类型中已经介绍过了,这里只是简单写一下用法实例。
函数变量的零值是nil,因此函数变量可以和nil进行比较,但是函数变量之间本身是不可以互相比较的!
var f func(int) int // 变量f为nil
f(4) // 调用一个为零值的函数会出错宕机
if f != nil {
f(4) // 判断函数是否为空
}现在在Go语言中,由于现在还不支持泛型程序设计,导致函数变量的地位还不是很高。但是在Go2出现泛型之后,函数变量的地位一定会飙升。
在Go语言中,匿名函数是非常常见的,除了方便撰写小规模的函数之外,还因为Go语言中的go关键字后面仅允许接函数,这就导致了匿名函数的大量使用。
普通的使用匿名函数:
x, y := 10, 20
fmt.Println(func(a, b int) int {
if a > b {
return a
}
return b
}(x, y))结合闭包的特性使用匿名函数:
func squares() func() int {
var x int // 在返回的匿名函数的眼中,这是一个全局变量,这是由于闭包的性质决定的
return func() int {
x++
return x*x
}
}
func main() {
f := squares()
fmt.Println(f(), f(), f(), f()) // 1, 4, 9, 16
}变长函数被调用的时候可以有可变的参数个数。最常见的就是fmt.Println(),那么如何声明一个变长函数呢?
在参数列表的,最后的类型名称之前使用省略号...,表示声明一个变长函数,调用这个函数的时候可以传递该类型任意数目的参数。
func sum(vals ...int) int {
tot := 0
for _, val := range vals { // 在变长函数中,以slice的形式组织多个相同类型的参数
tot += val
}
return tot
}所谓延迟调用,其实就是讲解一下defer关键字的作用。
有的时候,一些操作是需要成对进行的,比如内存的声明和释放(malloc、new和free),文件的打开和关闭(fopen和fclose),数据库的连接和释放等等。
在编写代码的时候,忘记,或者配对的语句失效的情况是很常见的:比如程序直接panic了,那么接下来的语句也不会执行了。如果你学习过Python语言,那么你一定知道with语句和上下文的概念(Python使用这种方式来确保能够让程序正常运行),而在Go语言中,使用了defer关键字来达到这种目的。
defer关键字的作用就是延迟目标函数的调用,在该语句的作用域退出前再进行执行。
比如:(对之前的示例进行改造)
func main() {
ch := make(chan struct{})
defer close(ch) // 相比之前的结构,我们现在可以使用更舒适的逻辑来编写程序
go func() {
fmt.Println("Hello, golang!")
ch<- struct{}{}
}
<-ch
// close(ch)实际会在这个位置执行
}为了证明即使宕机了也可以执行defer,我们做个实验:
func main() {
defer fmt.Println("I'am defer.")
f := func(int) int
f(4)
}多个defer语句执行的顺序是从后到前的,因为是栈嘛。
宕机和恢复,其实是讲panic()和recover()这两个Go语言的内置函数。
1. panic
当你的程序遇到不可操控的错误时,你的程序会宕机,也就是panic,当然我们可以自己去panic,这样往往比Go语言自动的panic更好也更可控,也更利于trouble-shooting,使用了panic函数之后你的程序会立刻退出。
func main() {
// ...do something
if err != nil { // error can not handle
panic(err) //
}
// normal logic
}2. recover
退出程序通常是正常处理宕机的方式,但是也有例外,在一定情况下是可以进行恢复的,比如在web开发时,一个具体的handler内部出现了足以让程序宕机的错误,但是这个时候应该做的是返回一个500的状态,而不是一直阻塞在那里(程序都崩溃了怎么给response啊)。
如果内置的recover函数在延迟函数的内部调用,而且这个包含defer语句的函数发生了宕机,recover会终止当前的宕机状态并且返回宕机产生的值。函数不会在宕机的位置继续运行,而是正常返回。
例如:
func main() {
defer func() {
if p := recover(); p != nil {
err = fmt.Errorf("Internal Error: %v", p)
}
}()
// ...some code here
// 如果这里发生了宕机,会在defer语句中执行错误的输出
}扩展阅读:
作为一门现代高级编程语言,Go语言当然支持面向对象的编程思想。但是和C++中萌芽初现的面向对象以及Java信奉的绝对的面向对象相比,Go语言的面向对象显然是太不合群了。
如果你使用过C++,那么你会知道面向对象的基础是对于类(class)的抽象,事实上Java也是这样。如果你对于面向对象是什么都不清楚的话,我觉得你需要看一下下面这篇文章:维基百科-面向对象程序设计
好了,现在开始我认为你了解了基本的面向对象程序设计的知识,那么你会不会也认为Go语言也会有一个名为class的关键字?毕竟C++,Java,Python都是这样的啊。
事实上,Go语言确实没有一个名为class的关键字用来声明一个类,甚至都没有类的概念。Go语言实现面向对象的基石是结构体。
接下来我们写一个最简单的面向对象的例子:
package main
import "fmt"
type HumanName struct {
FirstName string
LastName string
}
type Human struct {
Name HumanName
From string
}
func (human *Human) Speak() { // 为类型Human声明方法Speak
fmt.Println("I'm", human.Name.FirstName, human.Name.LastName+", and I came from", human.From)
}
func main() {
tom := Human{
Name: HumanName{
FirstName: "Jupter",
LastName: "Tom",
},
From: "USA",
} // 创建一个Human类型的实例
tom.Speak() // 调用实例的方法
}现在你应该恍然大悟了,原来Go语言没有类,只有类型。只不过可以给特定类型绑定上方法。而原来类中的属性就对应复合类型中的字段。只是知道这点就可以让我们进行简单的面向对象编程了。但是这还远远不够,我们还有很多问题没有解释清楚。
比如绑定在类型上的方法和绑定在类型指针上的方法的区别?Go语言这样一个强类型语言,一定会在这上面有特别的区分吧!
func (human *Human) Speak1() {} // 绑定在类型指针上,为指针方法
func (human Human) Speak2() {} // 绑定在类型上,为值方法
// 非常奇妙的事情,明明是不同的方法接收者,但是却不能使用同样的方法名在Go语言官方文档中有关于方法的值接收者和指针接收者的区别
对于没有涉及内存的操作(比如说打印一段话,使用值进行计算),值接收者和指针接收者没有什么区别,毕竟都可以使用.来取得值。
但是如果涉及到了值的改变,也就是对于内存的操作,事情就变得麻烦起来:
package main
import "fmt"
type TestInt int
func (value TestInt) Increase1() {
value += 1
}
func (pointer *TestInt) Increase2() {
(*pointer) += 1
}
func main() {
var number TestInt = 1
numberPointer := &number
fmt.Println(number) // 1
number.Increase1()
fmt.Println(number) // 1
numberPointer.Increase2()
fmt.Println(number) // 2
}很明显,也是我们预料中的结果,因为一个是对于传入的临时值进行了改变,而没有涉及main函数中定义的number变量。而传入指针可以让我们很好的操作内存空间。
我们这个示例中,对于值接收者和指针接收者都有不同的方法。但是对于值/指针调用值方法/指针方法的情况,我们还需要进行探讨。
// 我们只保留值方法
func (value TestInt) Increase() {
value += 1
}
func main() {
var number TestInt = 1
numberPointer := &number
fmt.Println(number) // 1
number.Increase()
fmt.Println(number) // 1
numberPointer.Increase()
fmt.Println(number) // 1
}我们运行这个代码,居然没有任何的错误信息!它照常的运行了。只不过值方法仍然没能改变值的值。使用指针调用值方法的时候,只会传入指针对应的值,而这个转换过程是Go语言内部执行的。实际效果:
(*numberPointer).Increase()如果我们只保留指针方法呢?结果是显而易见的
func (pointer *TestInt) Increase() {
(*pointer) += 1
}
func main() {
var number TestInt = 1
numberPointer := &number
fmt.Println(number) // 1
number.Increase()
fmt.Println(number) // 2
numberPointer.Increase()
fmt.Println(number) // 3
}也就是说,当只有对应的指针方法存在时,会将值的指针传入来调用指针方法,也就是说实际是这样的:
(&number).Increase()也就是说,Go语言会自动寻找和匹配当前最好的方法匹配策略:
- 如果同时兼有值方法和指针方法,会分别进行调用
- 如果只有值方法,会隐式转换指针为值进行调用
- 如果只有指针方法,会隐式转换值为指针进行调用
说到面向对象的时候,大家就会想到几个词:封装,继承,多态
不太凑巧,你在Go语言中,可能除了封装都见不到...
传统意义上的继承是指一种is a 的关系,比如pig is an animal,猪是一个动物,那么猪类就应该继承自动物类,动物能做的猪也都能做,而猪又有自己特有的方法和属性。
但是很遗憾,Go语言中并没有继承的概念,有的只是组合。因为面向对象依托于结构体的实现,因此一个新的类型只能通过组合的方式来产生:
type Eyes string // 眼睛类型
type Mouth string // 嘴类型
type Nose string // 鼻子类型
type Ears string // 耳朵类型
func (ears *Ears) Hear(s string) { // 耳朵类型的指针听方法
fmt.Println(s)
}
type Face struct { // 脸类型,由各个部分拼接而成
Eyes
Mouth
Nose
Ears
}
func main() {
face := Face{}
face.Hear("Golang is the best!") // 获得了耳朵的方法
}就像上面的例子,Face获得了Ears的方法,和is a的关系相比,更像是一种寄生的关系。
并且,在Go语言中是没有函数重载的。
嵌入和聚合:
寄生的关系可以使用两种方式来实现:嵌入和聚合。
type Head struct {
Organ // 器官
Face face
Hair hair
}Organ(器官)类型会有一些方法,比如说被福尔马林浸泡这种,那么我们调用头的浸泡福尔马林方法时,肯定不应该调用head.organ.Formalin(),而是应该调用head.Formalin(),这种将一个类型包含在另一个类型的内部的方式叫做嵌入。
相对应的,将一个类型声明为另一个类型的属性的方式叫做聚合,我们调用听的时候,肯定是想要去这样调用:head.ear.Hear(),而不是head.Hear()。
在合适的嵌入的时候嵌入,在合适聚合的时候聚合。
当你看到这个教程的时候,我认为你是一个有一定面向对象编程经验的人,如果你对于接口这个概念不太理解,那么可以先去了解接口的定义和作用。
Go语言的接口类型是对于其他类型行为的抽象和概括,因为接口类型不会和特定的实现细节绑定在一起,通过这种抽象方式我们可以让对象更加灵活和更具有适应性。
如果你对于Python有足够的了解,那么你会知道面向对象思想中的鸭子类型和白鹅类型,所谓鸭子类型说的是:
如果一个Obejct走起路来像鸭子,叫起来像鸭子,那么它就可以是一个鸭子。或者只是在我们在意的方面和鸭子相似,我们便可以把它当做鸭子。
比如一个鸭子除羽毛器:它接收一个动物,然后除去它的羽毛。
当然,你可以放一只真的鸭子进去,然后你会得到一个没有羽毛的鸭子。但是你要是放一只山雀应该也没什么问题(大家要保护野生动物),因为除羽毛器不关心动物的品种,只关心有没有羽毛。
而白鹅类型则更像一个DNA检测器:它要求接受和猴子有相同基因片段的生物。那么你放进去一个猴子,它抽了一管血,并且检查出了相同的片段。你把自己放进去大概也不会有什么问题。但是如果你把一个猴子电动玩具放了进去:假设经过人工智能的训练,这个玩具几乎和真正的猴子的行为是一致的,这个DNA检测器可能会坏掉并且把你炸飞。
白鹅类型在乎的不是抽象的行为,而是血统,也就是面向对象中的继承关系。
Go语言实现的是鸭子类型。
接口的声明和定义我们在之前已经讲过了,这里不再赘述,只是分析Go语言中的io.Reader和io.Writer来丰富我们对于接口的认识:
io.Reader & io.Writer
首先看看具体的定义:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}啊,这两个接口是多么的简单。事实上这两个是最小粒度的接口,分别实现了读方法和写方法。
如果我们需要一个类型,既可以读,也可以写呢?我们是要声明一个具有读方法和写方法的接口吗?如果Go语言只支持继承的话,可能会演变出两种类型:
-
- 继承自Reader,额外实现了Write()方法的类型
-
- 继承自Writer,额外实现了Read()方法的类型
有点奇怪,定义一个新类型也有点奇怪。
所以我们使用Go语言中嵌入的方法来实现io.ReadWriter接口类型:
type ReadWriter interface {
Reader
Writer
}那么也就是说,我们可以通过嵌入的方式来扩展一个接口。从而可以构建不同粒度的接口。我们可以在我们自己的代码中扩展接口,从而利用许多既有的方法:比如可以给任意一个自定义类型定义好Read()方法,返回一个JSON字符串,从而完成自定义的JSON生成和解析。
接口的显式转换和隐式转换
在Go语言中对于接口类型的互相转换相对于其他类型而言较为宽松。
一般我们在使用除了接口以外的类型时,进行类型转换只能通过强制类型转换来实现,甚至连将一个int类型的值赋值给int64类型都坐不到。而接口和一般类型之间往往需要使用类型断言来实现。
但是接口之间的转换却是十分的方便(相对而言),这里借鉴柴先生书中的一个示例:
var (
// 隐式转换,*os.File满足io.ReadCloser接口
a io.ReadCloser = (*os.File)(f)
// 隐式转换
b io.Reader = a
// 隐式转换
c io.Closer = a
// 显式转化,io.Closer不满足io.Reader接口
d io.Reader = c.(io.Reader)
)接口和接口之间灵活的转换,对于平常被强类型摁在地上摩擦的Go语言程序员而言简直就像是天使一般,但是在幸福的同时往往最可能犯错!接口之间的过于灵活让大家开始担忧无意之间类型适配的问题。
于是大家给特定的接口特有的方法,这样便可以大概率的阻止无意义的适配。
接口是Go语言面向对象编程时的利器,但是使用时也要特别注意!
相信在经过了前面几章的摸索和学习之后, 读者已经可以进行简单的Go语言程序的开发了, 那么从本章开始将进行对于Go语言内置包的运用.
在本节中, 我们主要使用的包为 net/http 包.
- 客户端和服务端
在网络编程中, 最基本的概念是客户端: client和服务端: server的概念. 客户端相当于是和用户进行交互的一端, 比如说浏览器, 而服务端是用于提供服务的一端, 负责和客户端进行交互, 还有和其他服务端进行交互, 比如说运行在服务器上的一个服务.
Client Server
客户端 <=====> 服务端
- 请求-响应 循环
相信读者应该听说过请求: request和响应: response的概念, 请求是由客户端或者服务端向服务端发送的想要获取信息的数据流. 在这里简单介绍一下HTTP请求:
HTTP请求是遵循HTTP协议的请求方式, 一般拥有的属性有: 请求方法: method, 请求头: header 和 请求数据域: payload
请求方法指出了一个HTTP请求对于资源操作的具体方式:
GET,POST,PUT,DELETE,PATCH,OPTION等等... 一般我们接触最多的就是GET,POST,PUT和DELETE这四种.
- GET: 表示对于资源的获取操作
- POST: 表示对于资源的创建的操作和需要发送数据的操作
- PUT: 表示对于资源的修改的操作
- DELETE: 表示对于资源的删除操作
方法终究只是用于标识请求意义的字段, 如果你想要在GET里塞很多的数据当然也是可以的...
请求头包含了一个请求的基本信息, 其中比较重要的有
Content-Type和Cookie和User-Agent字段
当然所有的Header都很重要! 关于每一个Header字段的意义可以参考一下MDN的资料
请求中的数据域包含了几个来源, 其实
header也可以算其中的一个, 除此之外还有path,query-string和data
- path是指包含在路由中的参数, 比如:
/user/1/info/这里的1就是所谓的路径参数 - query-string, 字面意思, 就是用于查询操作的字符串, 一般位于整个URL的最后, 由
?和&拼接而成, 比如:/comments?length=12, 这里的query-string便包括了length:12这个键值对 - data就是数据包, 现在常用的编码方式有:
form-data和json
许多的应用场景中,对于数据的传输都使用特定的方法,比如:
- 在许多的搜索API中,往往将数据放在query-string中,并且使用GET方法去调用接口。
- 在一般的POST方法中,传输数据的方式往往是以data,也就是数据载荷的方式来传输的。
- 而对于唯一确定资源的主键,比如id或者hash-key,则往往放在path当中
注意:对于上面提到的一部分情况,不是完全规定死的,而是可以随意变更的,使用什么方法,怎么去传输数据都可以随着个人的喜好而改变,只是很多时候大家达成了共识而已。
- 前后端分离的开发方法
在很多人开始写自己的第一个项目的时候,往往都是撰写一个前后端合并的项目:比如一个个人博客网站啦,一个所谓的宠物网店啦(致敬flasky)等等这个时候往往是程序员自己又写前端又写后端,使用HTML模板的方式来调用自己撰写的后端逻辑。
前后端合并的方式是比较初级的开发方式:由一个人独立开发整个应用,这使得对于程序员的技术要求更高,因为需要同时熟悉使用前端和后端的技术栈,这对于个人能力的考验是很大的。并且由个人维护的应用往往会出现难以让他人参与开发,难上手等各种问题。
因此在现在普遍使用的是前后端分离的开发方法,前端和后端约定一套应用编程接口,然后分离开发,这样既可以降低对于程序员个人能力的要求,对于整个应用的维护也是很好的。
首先,使用net/http需要在代码中使用以下语句:
import "net/http"然后一起来写一个最简单的示例:
package main
import (
"fmt"
"net/http"
"time"
)
func showTimeNow(w http.ResponseWriter, r *http.Request) {
t := time.Now()
str := fmt.Sprintf(t.Format(time.RFC3339))
w.Write([]byte(str))
return
}
func main() {
http.HandleFunc("/time/now/", showTimeNow)
http.ListenAndServe(":8080" ,nil)
}这个示例的作用非常的清晰:主函数内我们首先使用http.HandleFunc方法来建立处理函数和路由的映射关系,然后使用http.ListenAndServe方法来进行对于某个端口的监听。
在我们运行了这个简单的示例之后,就可以在本机的localhost:8080/time/now/建立起一个API,可以使用浏览器直接打开,你会看到格式化输出的当前的时间。
众所周知,我们所有能使用浏览器打开的网页,或者说能够在互联网上获取到的资源,全部都可以使用脚本模仿相同的方式去访问的到。而这种使用脚本获取互联网上资源的方式的程序,叫做爬虫程序。
爬虫这个名字大家都是耳熟能详的,这个小节就给大家揭开一点点爬虫的面纱。
一般简单的爬虫的目的就是模拟人的行为,从而获取到自己想要的数据。有点像那个电脑上的按键精灵的软件,由于程序处理数据的能力远远大于我们人类的肉眼和大脑,所以使用计算机程序来进行对于从互联网山获取的海量的数据中来挑取对于自己有用的信息。
以获取一个网页上的信息为例,这个最简单的爬虫的流程如下:
- 获取整个页面
- 从页面中筛选自己想要的信息
至于如何循环自动获取不同的页面,怎么去筛选自己想要的信息,那是需要另写一个爬虫教程的内容了,我们这里就只放一个最简单的,获取我们刚刚撰写的接口内容并且打印的程序。
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
resp, err := http.Get("http://127.0.0.1:8080/time/now/")
if err != nil {
fmt.Println("Get content failed.")
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
fmt.Println(string(body))
}这个示例非常的简单:首先使用Get方法从我们本地的接口获取一个响应,然后对于响应的Body进行读取,由于网络中数据的传输是通过字节流的形式进行的,因此都会被转换为Reader和Writer来进行读取和写入,因此需要Close。
拿到内容之后我们打印出来就可以了,我的命令行会打印出:2019-12-12T00:27:27+08:00。
作为一个集成了HTTP中内容的包,net/http包中包含了大量的类型和接口,以便向用户提供更友好的方法。
在net/http官方文档中可以看到全部的类型的定义,以及所有的方法以及作用,本小节主要介绍以下几个类型:
- Client
- Cookie
- Header
- Request
- Response
- Client
Client类型的实例是一个HTTP协议的客户端,它的默认值(零值)是使用DefaultTransport的可用客户端。
客户端一般会在内部维护一个传输的状态,比如带有缓存的TCP链接,因此在必要时,应该重新使用客户端,而不是重复的创建客户端。一个Client可以被多个goroutine安全的并发使用。
Client比起RoundTripper更加的高级,还附加了对于HTTP中详细信息的处理机制,比如Cookie和重定向。
在重定向请求时,Client将转发在初始请求中设置的全部请求头,但是以下情况不会:
- 当带有敏感信息的头部被转发到不被信任的目标时:比如"Authorization", "WWW-Authenticate"和Cookie。当重定向到不匹配的子域或者不是初始域时,以上头部会被忽略。比如,请求从"foo.com"重定向到"foo.com"或"sub.foo.com"时,带有敏感信息的头部会被一起转发,但是转发到"bar.com"时是不会的。
- 当使用内部CookieJar为nil的Client转发Cookie时,由于每一次的重定向都可能改变CookieJar的状态,因此一次重定向可能会改变初始请求中的CookieJar。所以当转发Cookie头部时,所有的突变都会被无视,面对这种情况CookieJar会把这些突变的值更新到Jar中。如果CookieJar为nil,则原封不动的转发初始请求的Cookie。
Client类型的实例拥有六个方法:CloseIdleConnections, Do, Get, Head, Post, PostForm. 可以很明显的看出Get, Head, Post, PostForm,都是一类方法:它们代表具体的请求方法,而PostForm则是以特定的方式:表单,去提交数据。
而在源码中,以上这些特殊方法:PostForm是调用Post方法来实现的。而Get, Head, Post都是通过调用Do方法来实现的,比如让我们看一下Get方法的源码:
func (c *Client) Get(url string) (resp *Response, err error) {
req, err := NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
return c.Do(req)
}在该方法中,首先根据传入的参数(url)构建了一个GET方法的请求(请求类型Request),然后紧接着就调用了我们没有解释过的Do方法。
关于Do
Do方法的意义非常的“字面化”,就是客户端去执行(Do)一个特定的请求,然后返回该请求的响应。net/http封装了特定的请求方法,但是实际上这些方法都是依托Do方法来实现的。因此所有人在需要时都可以自己封装类似于Delete, Option之类的方法,或者PostJSON这种方法。或者直接手动构建一个请求然后去调用Do方法,这样更加直截了当。
最后一个没有提到的方法是CloseIdleConnections,字面意思是关闭所有的空闲连接,实际上也确实如此。
- Cookie
HTTP Cookie是服务器发送到用户浏览器并且保存在本地的一小部分数据,它会在浏览器下次向同一个服务器再次发起请求时被一起携带。通常来讲,它用于告知服务端两个请求是否来自同一个浏览器(用户),比如保持用户的登录状态,Cookie使得基于无状态的HTTP协议记录稳定的状态信息成为了可能。(摘自Mozilla-Cookie)
而http包中的Cookie类型,代表从HTTP响应中Set-Cookie头部接受,或者在请求的Cookie头部中发送的信息。
Cookie类型是内容向类型,内部结构:
type Cookie struct {
Name string
Value string
Path string // optional
Domain string // optional
Expires time.Time // optional
RawExpires string // for reading cookies only
// MaxAge=0 means no 'Max-Age' attribute specified.
// MaxAge<0 means delete cookie now, equivalently 'Max-Age: 0'
// MaxAge>0 means Max-Age attribute present and given in seconds
MaxAge int
Secure bool
HttpOnly bool
SameSite SameSite // Go 1.11
Raw string
Unparsed []string // Raw text of unparsed attribute-value pairs
}其中的字段都和RFC-6265中描述的一致,作用可以自己去查看。
Cookie类型的实例拥有一个名为String的方法,用于返回一个Cookie字符串。
- Header
Header代表HTTP中的头部信息,以键值对的方式来进行存储。
type Header map[string][]string很是简单,对不对?因为Header就是键值对,而一个键可以有多个值,因此对应的是一个string的切片。
Header类型的实例拥有Add, Clone, Del, Get, Set, Write, WriteSubset。看上去就是基本的CURD的操作,事实上也确实如此。
Add方法传入一个键值对,将其添加到Header中,并且是大小写不敏感的。
Clone方法返回一个实例的副本,当实例为nil时返回nil。(这里需要注意,Header所有方法的接受者是值接受者,因此允许为nil进行方法调用)
Del方法用于删除一个键值对,传入一个键。
Get方法传入一个键的string,然后返回一个格式化后的字符串。
Set方法也是传入键值对的方式,但是会把该键对应的目标值直接替换为传入的值,而不是追加。同样的,大小写不敏感。
Write方法将Header的内容写进传入的Writer,写入的格式是有线的。
WriteSubset方法除了传入一个Writer之外,还将传入一个Map,用于标志写入哪些Header中的键值对。当传入的Map为nil时全部写入,否则,将Map中值为true的键不进行写入。
- Request
请求和响应,是每个网络相关包的大头,内容过长警告
一个Request类型的对象表示一个从服务端发向客户端的HTTP请求。对于客户端和服务端而言Request中某些字段的语义略有不同。
Request结构体的内部结构:(注释太多都删掉了,想看的可以去这里看)
type Request struct {
Method string
URL *url.URL
Proto string // "HTTP/1.0"
ProtoMajor int // 1
ProtoMinor int // 0
Header Header
Body io.ReadCloser
GetBody func() (io.ReadCloser, error) // Go 1.8
ContentLength int64
TransferEncoding []string
Close bool
Host string
Form url.Values
PostForm url.Values // Go 1.1
MultipartForm *multipart.Form
Trailer Header
RemoteAddr string
RequestURI string
TLS *tls.ConnectionState
Cancel <-chan struct{} // Go 1.5
Response *Response // Go 1.7
}接下来将一一解释其中的意义:
Method字段表示一个确切的HTTP请求方法,不支持CONNECT方法。当字段为空串时,为GET方法。
URL字段为*url.URL类型,表示了一个确切的要被请求的URI(对于服务器的请求)或URL(对于客户端的请求),对于大多数的请求而言,除了Path和Query之外的字段都是空。
附:url.URL(真的越写越多,越写越长)
type URL struct {
Scheme string
Opaque string // encoded opaque data
User *Userinfo // username and password information
Host string // host or host:port
Path string // path (relative paths may omit leading slash)
RawPath string // encoded path hint (see EscapedPath method); added in Go 1.5
ForceQuery bool // append a query ('?') even if RawQuery is empty; added in Go 1.7
RawQuery string // encoded query values, without '?'
Fragment string // fragment for references, without '#'
}Proto字段标识使用的HTTP协议。默认是HTTP/1.0
ProtoMajor字段标识HTTP协议版本号的整数部分,默认为1.
ProtoMinor字段标识HTTP协议版本号的小数部分,默认为0.
Header字段存储着请求的头部信息,之前介绍过了。
Body字段为io.ReadCloser类型,内容就是请求的主体(Body)信息,对于客户端的请求,本字段为nil表示请求没有主体内容,比如一个GET请求。而对于服务端的请求而言,本字段将不会为nil,但是主体不为空的时候,将直接返回一个EOF,然后服务端就会立即关闭这个Reader。
GetBody字段为一个函数,直接返回一个io.ReadCloser和error。本字段定义了一个可选的能够返回Body的副本的函数。通常用于一个需要多次读取Body的重定向请求。在调用这个函数之前要确保Body的值被设置了。而对于服务端的请求而言,这个字段是没有意义的。
ContentLength字段为一个int64类型的整数,用于记录携带内容的长度,如果是-1则代表长度是未知的,大于零则代表可能从Body中读取的字节序列的长度。对于客户端的请求,本字段为0且Body为nil讲同等为长度未知对待。
TransferEncoding字段为一个字符串切片类型,列出了一个请求从最外层到最内层的编码序列,空列表表示“Identity”编码。本字段通常可以被忽略,分块编码会在发送和接受时视需求而自动增删。
Close字段为bool类型,对于服务器请求而言,表示是否在响应一个请求之后关闭连接,而对于客户端请求而言,表示是否在发送这个请求并接收到响应之后关闭连接。对于服务器端的请求,HTTP服务器会自动处理,因此不需要特殊处理。而对于客户端请求而言,设置本字段会在发起每个请求时创建连接,就设置了DisableKeepAlives一样。
Host字段为字符串类型,对于服务器请求而言,为其请求URl中的Host部分。对于国际域名,本字段可能为Punycode或者Unicode结构,可以使用golang.org/x/net/idna来自由进行转换。为了遏制DNS的重绑定攻击,服务器上的处理函数应该验证本字段是否是被认证的的。
Form字段为url.Values类型,包含了解析后的表单数据,既有URl中的Query参数,也有PATCH,POST和PUT方法提交的表单数据。本字段只有在调用了ParseForm()方法之后才是可用的。HTTP客户端无视表单,转而使用Body传输数据。
PostForm字段也为url.Values类型,包含的是单纯的由PATCH,POST和PUT方法提交的表单数据。也是要先行调用ParseForm()方法。
MultipartForm字段为*multipart.Form类型,其内容是Multipart的表单数据,比如说上传的文件。同样要在调用ParseMultipartForm()方法之后才可用。
Trailer字段是Header类型的,对于服务端请求,本字段将仅仅包含在Trailer头部中的键,值全部为nil。当处理程序从Body中读取数据时,必须不能引用本字段,只有在Body返回EOF时,本字段才能再次被读取,并且会包含有非空数据(如果客户端发送了的话)。对于客户端请求而言,本字段必须被初始化为接下来可能要发送的键的map,值可以是nil或者其他零值,在分块发送时ContentLength字段必须为0或者-1。在请求发送之后,当请求发送的数据被读取时,本字段的值可以被更新。一旦在请求的数据被读出EOF后,本字段不可被更改。只有极少的HTTP客户端,服务器和代理支持本功能。
RemoteAddr字段为字符串类型,本字段允许HTTP服务器或者其他软件记录下发送请求的机器的网络地址,通常用于输出日志。本字段不会被ReadRequest()方法自动填充,并且没有固定的格式。HTTP客户端可以忽略本字段。
RequestURI字段为字符串类型,本字段是从客户端到服务器,未经更改的原请求目标URI,通常使用URL。
TLS字段为*tls.ConnectionState类型,本字段允许HTTP服务器或者其他的软件记录接收到请求的TLS连接的信息,同样,本字段不会因为调用ReadRequest()方法而变得可用。本包中的HTTP服务器在调用处理程序之前会设置TLS-enabled字段,否则字段将为零值。HTTP客户端会忽略本字段。
Cancel字段为<-chan struct{}类型,用于取消客户端发起的请求,对于服务端请求则不适用。本字段是可选的,并不是所有的RoundTripper都支持取消请求。
Response字段为*Response类型,是导致本请求创建的重定向响应,本字段仅在客户端重定向期间会被使用。
- Response
一个Response类型的对象代表对于一个HTTP请求的响应。当HTTP客户端和Transport接收到了来自服务器的响应头时,会立即返回Response的实例。在读取Response的Body字段时,将以按需的方式从字节流中进行读取。
Response的内部构成:
type Response struct {
Status string // e.g. "200 OK"
StatusCode int // e.g. 200
Proto string // e.g. "HTTP/1.0"
ProtoMajor int // e.g. 1
ProtoMinor int // e.g. 0
Header Header
Body io.ReadCloser
ContentLength int64
TransferEncoding []string
Close bool
Uncompressed bool // Go 1.7
Trailer Header
Request *Request
TLS *tls.ConnectionState // Go 1.3
}Status字段为字符串类型,和注释中写的一样,是由状态码和描述一起拼接而成的。
StatusCode字段为int类型,用于表示响应的状态码,比如2xx, 3xx, 4xx, 5xx等等,至于具体的状态码是什么意思,自己去查。
Proto字段为字符串类型,用于标识HTTP协议。
ProtoMajor字段为int类型,代表当前的HTTP协议的版本号的整数部分。
ProtoMinor字段为int类型,代表当前HTTP协议的版本号的小数部分。
Header字段为Header类型,代表响应头。
Body字段为io.ReadCloser类型,代表响应的正文内容。本字段是以按需的方式读取,以字节流的方式进行传输的。如果网络连接失败或者服务器终止响应,则读取本字段时将会抛出异常。HTTP客户端和Transport保证了即便响应没有包含正文,或者正文长度为0时,本字段也不为nil。调用者一定要关闭对于正文的读取,否则之后的HTTP客户端不会重用以前的TCP连接。
ContentLength字段为int64类型,记录了相关联内容的长度,如果值为-1则代表长度是未知的。除非请求的方法是HEAD,否则本字段代表能从Body字段中读出的字节数。
TransferEncoding字段为字符串切片类型,包含从最外部到最内部的传输编码,如果值为nil,则表示使用Identity编码。
Close字段为布尔类型,本字段记录了在读取正文之后,是否关闭连接。
Uncompressed字段为布尔类型,本字段标识响应是否被压缩发送但是又被http包解压缩了。如果本字段为真,则从Body中读取解压后的内容而非服务端实际发送的被压缩的内容,ContentLength字段的值被设置为-1,并且Content-Length和Content-Encoding两个字段将在响应头中被删除。
Trailer字段是Header类型的,本字段将trailer中的键值对映射为Header的格式。本字段初始化时仅包含nil,所有的值都来源于服务端发送的Trailer头部,这些被解析出的值不会被添加到响应头中。在读取响应正文时,本字段不允许被调用。只有当Body返回io.EOF后,本字段的所有值才就绪(可以被使用且是正确的)。
Request字段为Request的指针类型,是本响应所对应的请求。
TLS字段为*tls.ConnectionState类型,包含了TLS连接到具体接收响应的链路信息,对于没有加密的响应,本字段的值应该为nil。