The input is a logical expression containing a number, and the output is the boolean value after calculation and the number of comparisons skipped due to short-circuit operations. The output format is "Output: [true or false], [number of times]". Note that the evaluation of the logical expression conforms to the short-circuit algorithm. Among them, the operater "!" counts the number of logical operations, and "==" or "!=" are only used for non-boolean numeric comparisons.
Flex is an open source lexical analyzer. The compiler converts the pattern input by the developer into a state transition diagram, and generates the corresponding implementation code, which is stored in the .yy, c files.
| token | symbol | meaning |
|---|---|---|
| dight | [0-9]|[1-9][0-9]* | number |
| LT | < | less than |
| GT | > | greater than |
| LE | <= | less or equal to |
| GE | >= | greater or equal to |
| EQ | == | equal to |
| NE | != | not equal to |
| AND | && | and |
| OR | || | or |
| NOT | ! | not |
| LP | ( | left parentheses |
| RP | ) | right parentheses |
| newline | \n\r | line-termination |
| whitespace | \t\f\v | whitespace |
By using bison and flex together, it can convert the grammar rules provided by the user into a parser, read the productions of the grammar provided by the user, generate a LALR(1) action table in C language format, and include it in a C function named yyparse. The function of yyparse is to use this action table to parse the token stream, and the token stream is obtained by scanning the source program by the lexical analyzer generated by flex.
In bison, ":" represents a "->", different productions of the same non-terminal symbol are separated by "|", and the end with ";" indicates the end of a non-terminal symbol production; each production is followed by a curly bracket is a piece of C code that will be executed when the production is applied. This code is called an action. Comments can be inserted between the production and inside the C code (more on this code in this document later) ; When the right-hand side of the production is ε, there is no need to write any symbol, and a comment /* empty */ is generally used instead.
bison treats the nonterminal symbol on the left of the first production in the Productions section (Program in this document) as the start symbol of the grammar, and, to ensure that the start symbol is not on the right side of any production, bison will automatically generate the augmented grammar, and the newly added symbol is used as the starting symbol for parsing.
The precedence and associativity of these operator tokens are defined in the .y file. In the code, the first declaration has a lower precedence, and the tokens declared at the same time have the same precedence. The rules are as follows:
| Priority(top-down) | simbol | Associativity |
|---|---|---|
| 1 | OR | Left |
| 2 | AND | Left |
| 3 | LT GT LE GE | Left |
| 4 | EQ NE | Left |
| 5 | NOT | Right |
| 6 | LP RP | Left |
According to the form of logical expressions, the following grammar is summarized:
● Program => Exp
● Exp => NOT Exp
| Exp AND Exp
| Exp OR Exp
| Exp LT Exp
| Exp LE Exp
| Exp GT Exp
| Exp GE Exp
| Exp EQ Exp
| Exp NE Exp
| LP Exp Rp
| VALUE
Program is the start symbol of the grammar, and the corresponding augmented grammar Program' will be automatically generated after bison compilation.
The number of short circuits is only relevant to the AND and OR operators. First, in the .y file, define a global variable to count the number of short circuits:
int short_cut = 0; // record the number of shortcuts For AND operation, if the result of the first expression is False, a short circuit is performed. Then the short_cut number is incremented by 1, and the return is True; for OR operation, if the result of the first expression is True, a short circuit is performed, and the short_cut value is incremented 1, returned as True. In other cases, the short-circuit operation is not considered. The part of the code corresponding to the short-circuit operation is as follows:
| Exp AND Exp { // AND operation
if ( $1 == 0 ) { // The first operand is False, so short-circuit
short_cut++;
$$ = 0;
}
else
{
if ($3 == 1) { $$ = 1; }
else { $$ = 0; }
}
}
| Exp OR Exp { // OR operation
if ($1 == 1) { // The first operand is True, so short-circuit
short_cut++;
$$ = 1;
}
else {
if ($3 == 0) { $$ = 0; }
else { $$ = 1; }
}
} All input symbols accepted by the program are as follows:
%token LT // <
%token GT // >
%token LE // <=
%token GE // >=
%token EQ // ==
%token NE // !=
%token AND // &&
%token OR // ||
%token NOT // !
%token LP // (
%token RP // )
digit [0-9]|[1-9][0-9]* // Numbers
whitespace [ \t\f\v] // Whitespace
newline [\r\n] // Newline When the input character is not in the above list, the program outputs an error message and displays the content of the first input error character. When there are multiple errors, only the first error will be displayed, and the operation will stop immediately when an error is detected. Code shows as below:
/* error, incorrect character */
. {
printf("Error! Wrong token '%s'.\n", yytext);
exit(0);
} Compile files:

Compile succeeds, generates files listed below:
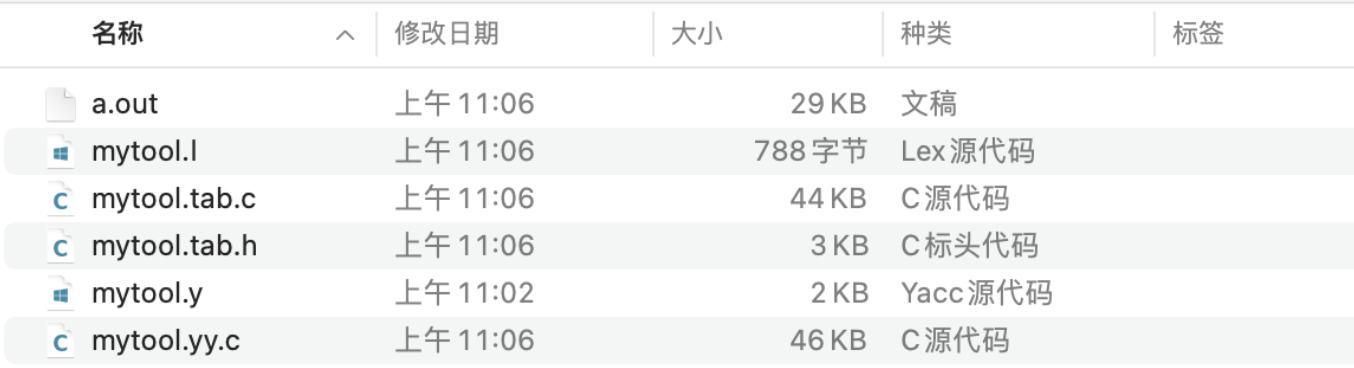
Test program output:
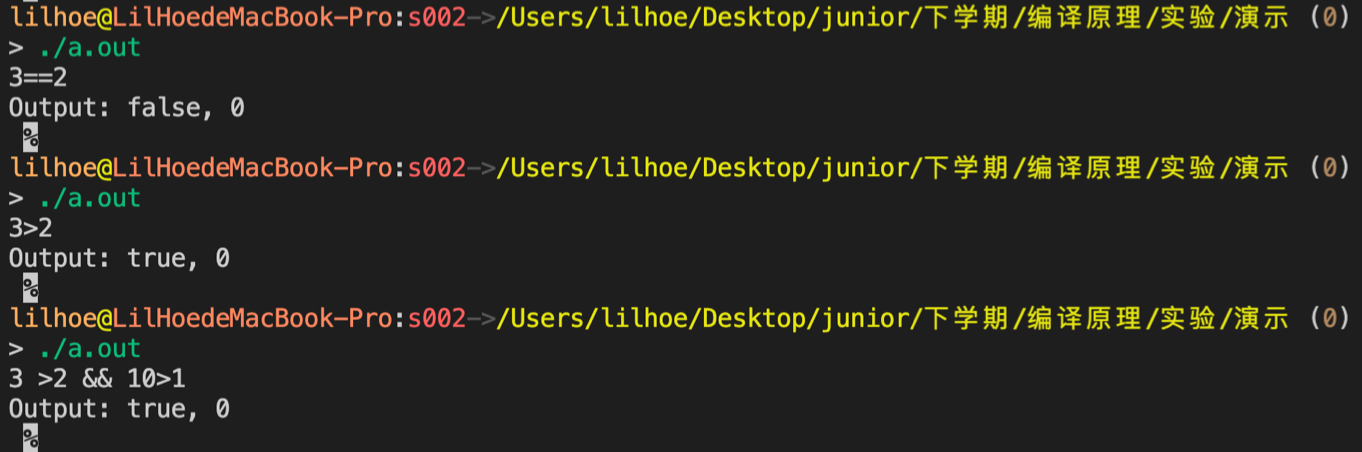
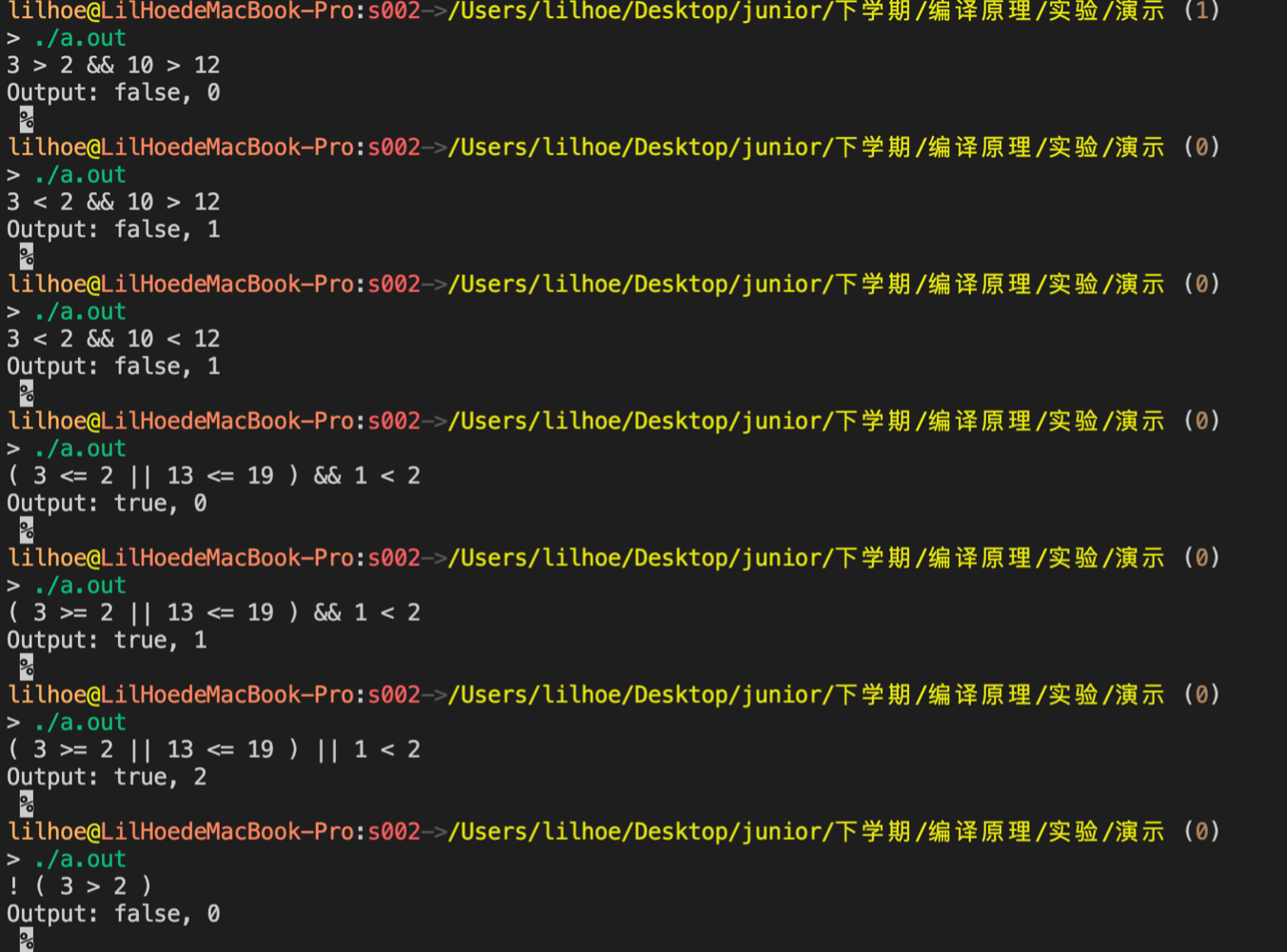

Let's test some illegal grammars:

The program works as expected.