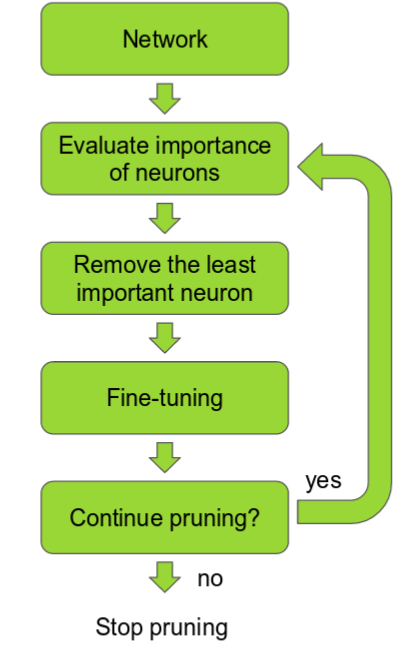
The purpose of this project is to evaluate the performance and efficiency tradeoffs of different pruning methods on a variety of popular deep learning models including AlexNet, BERT, VGG, ResNet. The pruning methods we considered here are L1/random unstructured pruning and structured pruning of convolutional layers. This methods will be applied iteratively as shown in the picture below.
torch.nn.utils.prune (Pytorch only mask out the weights. So we can only observe
changes in performance but not changes in inference time.)
torch_pruning (Actually prune the conv layers. Ref:https://github.com/VainF/Torch-Pruning)
Below are some example commands. Some hyperparameters are can be adjusted through arguments while others need to be modified in the code.
For training AlexNet:
python train_AlexNet.pyFor unstructured pruning of AlexNet with L1:
python prune_unstructured_AlexNet.py --prune_fraction 0.5 --iterations 6For structured pruning of AlexNet with L2:
python prune_structured_AlexNet.py --prune_fraction 0.1 --iterations 10For evaluating improvement in inference time of structurally-pruned AlexNet:
python evaluate_alexnet_efficiency.pyFor training BERT:
python train_BERT.pyFor unstructured pruning of BERT with L1:
python prune_unstructured_AlexNet.py --prune_fraction 0.1591 --iterations 12For training VGG16: Fine-tuned the pre-trained model
python train_vgg16.pyFor unstructured pruning of VGG16 with L1:
python prune-unstructured-vgg16.py --prune_fraction 0.1591 --iterations 12For structured pruning of VGG16 with L2:
python prune_structured_vgg16.py --prune_fraction 0.1 --iterations 10For evaluating improvement in inference time of structurally-pruned VGG16:
python evaluate_vgg16_efficiency.pyFor training ResNet: Fine-tuned the pre-trained model
python train_ResNet18.py
or
python train_ResNet50.pyFor unstructured pruning of ResNet with L1:
python prune-unstructured-resnet18.py --prune_fraction 0.1591 --iterations 10
or
python prune-unstructured-resnet50.py --prune_fraction 0.1591 --iterations 10For structured pruning of VGG16 with L2:
python prune_structured_resnet18.py --prune_fraction 0.1 --iterations 10
or
python prune_structured_resnet50.py --prune_fraction 0.1 --iterations 10For evaluating improvement in inference time of structurally-pruned ResNet:
python evaluate_resnet18_efficiency.py
or
python evaluate_resnet50_efficiency.pyResults are stored in numpy matrices and saved as txt files in performance folder.
For files *_performance.txt, the rows(from top to bottom) are fraction of model left,
test/train accuracies before finetuning, test/train accuracies after finetuning.
Improvement in inference time are stored in *_efficiency files.
Same as the above models, Results are also stored in numpy matrices and saved as txt files in performance2 folder.
For files *_performance.txt, the rows(from top to bottom) are fraction of model left,
test/train accuracies before finetuning, test/train accuracies after finetuning.
Improvement in inference time are stored in *_efficiency files.
*_structured_performance.txt records the variation of the number parameters left after pruning. the rows(from top to bottom) are fraction of model left, the number of parameters of original model, the number of parameters(unmasked) left for pytorch pruning and the number of parameters(unmasked) left for actually pruned model.