Error with Japanese subtitles #15
Comments
|
Thanks for reporting this. Do you have more details of the errors? Can you share if more things are displayed? (e.g. Traceback (most recent call last):) Does the problem appear if you execute the application with the parameter "--verbose False"? Finally, will be possible to share a file that allows me to reproduce the problem? Thanks |
|
Hi Jordi,
I'm happy to do more testing but need a little bit of help.
There's been some discussion here on this topic:
SubtitleEdit/subtitleedit#6816 (comment)
As I am going through SubtitleEdit I am not sure how to pass through
additional parameters.
Do you have a sample command line template I could use? For Whisper I was
using: whisper.exe --device cuda --language ja --model "base"
"C:\Users\rsmit\Dropbox\Videos\10 MPantry final new titles 2.mp4"
This is the file I've been testing (already public video with Japanese
narration):
https://www.dropbox.com/s/3gjxcubx7axftgk/10%20MPantry%20final%20new%20titles%202.mp4?dl=0
Really though any audio file should work as Whisper doesn't know what
language it is and will attempt to find Japanese if you tell it the source
is Japanese.
This is all the SubtitleEdit Error_log had for this:
…-----------------------------------------------------------------------------
Date: 04/14/2023 15:38:13
SE: 3.6.12.62 - Microsoft Windows NT 10.0.22621.0 - 64-bit
Message: C:\Users\rsmit\Dropbox\transfer
settings\Whisper-Faster\Whisper-Faster\whisper-ctranslate2.exe --language
ja --model "base" "D:\Temp\dbd53e23-f07c-4f50-9385-a72d2514d600.wav"
-----------------------------------------------------------------------------
Date: 04/14/2023 15:38:17
SE: 3.6.12.62 - Microsoft Windows NT 10.0.22621.0 - 64-bit
Message: Calling whisper (CTranslate2) with :
C:\Users\rsmit\Dropbox\transfer
settings\Whisper-Faster\Whisper-Faster\whisper-ctranslate2.exe --language
ja --model "base" "D:\Temp\dbd53e23-f07c-4f50-9385-a72d2514d600.wav"
UnicodeEncodeError: 'charmap' codec can't encode characters in position
26-216: character maps to <undefined>
File "encodings\cp1252.py", line 19, in encode
File "D:\whisper-fast\__main__.py", line 399, in cli
File "D:\whisper-fast\__main__.py", line 406, in <module>
Traceback (most recent call last):
[17000] Failed to execute script '__main__' due to unhandled exception!
Calling whisper CTranslate2 done in 00:00:03.3541655
Loading result from STDOUT
On Fri, Apr 14, 2023 at 2:35 PM Jordi Mas ***@***.***> wrote:
Thanks for reporting this.
Do you have more details of the errors? Can you share if more things are
displayed? (e.g. Traceback (most recent call last):)
Does the problem appear if you execute the application with the parameter
"--verbose False"?
Finally, will be possible to share a file that allows me to reproduce the
problem?
Thanks
—
Reply to this email directly, view it on GitHub
<#15 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/A5EWOZLFFT72AQOTP4OW4RLXBDO3PANCNFSM6AAAAAAW56RO3E>
.
You are receiving this because you authored the thread.Message ID:
***@***.***>
|
|
Try with --device cuda --language ja --model "base" --verbose False To see if makes any difference. Thanks |
|
Thanks for that.
So here's the full command line (ran cmd as admin): whisper-ctranslate2.exe
--device cuda --language ja --model "base" --verbose False
"C:\Users\rsmit\Dropbox\Videos\10 MPantry final new titles 2.mp4"
and here's the "output"- a few misheard characters repeated again and
again? I don't see any output srt file.
[image: image.png]
…On Fri, Apr 14, 2023 at 4:08 PM Jordi Mas ***@***.***> wrote:
Try with --device cuda --language ja --model "base" --verbose False
To see if makes any difference. Thanks
—
Reply to this email directly, view it on GitHub
<#15 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/A5EWOZJETEV3JTOKDVTUUI3XBDZYXANCNFSM6AAAAAAW56RO3E>
.
You are receiving this because you authored the thread.Message ID:
***@***.***>
|
|
Thanks I cannot see the image that you shared. My understading is that now it did finished but no contents on the files. Correct? |
|
It just gave a few repeated garbage characters and no file that I could find (nothing in the source footage folder or Faster Whisper folder). |

|
Thanks, let me have a a look in the next days and come back to you. |
|
I appreciate it and and am happy to perform more tests to isolate the issue. |
|
I did a test in Windows an it works for me:
Can you check which version of whisper-ctranslate2 are you running? Just type whisper-ctranslate2 --version |
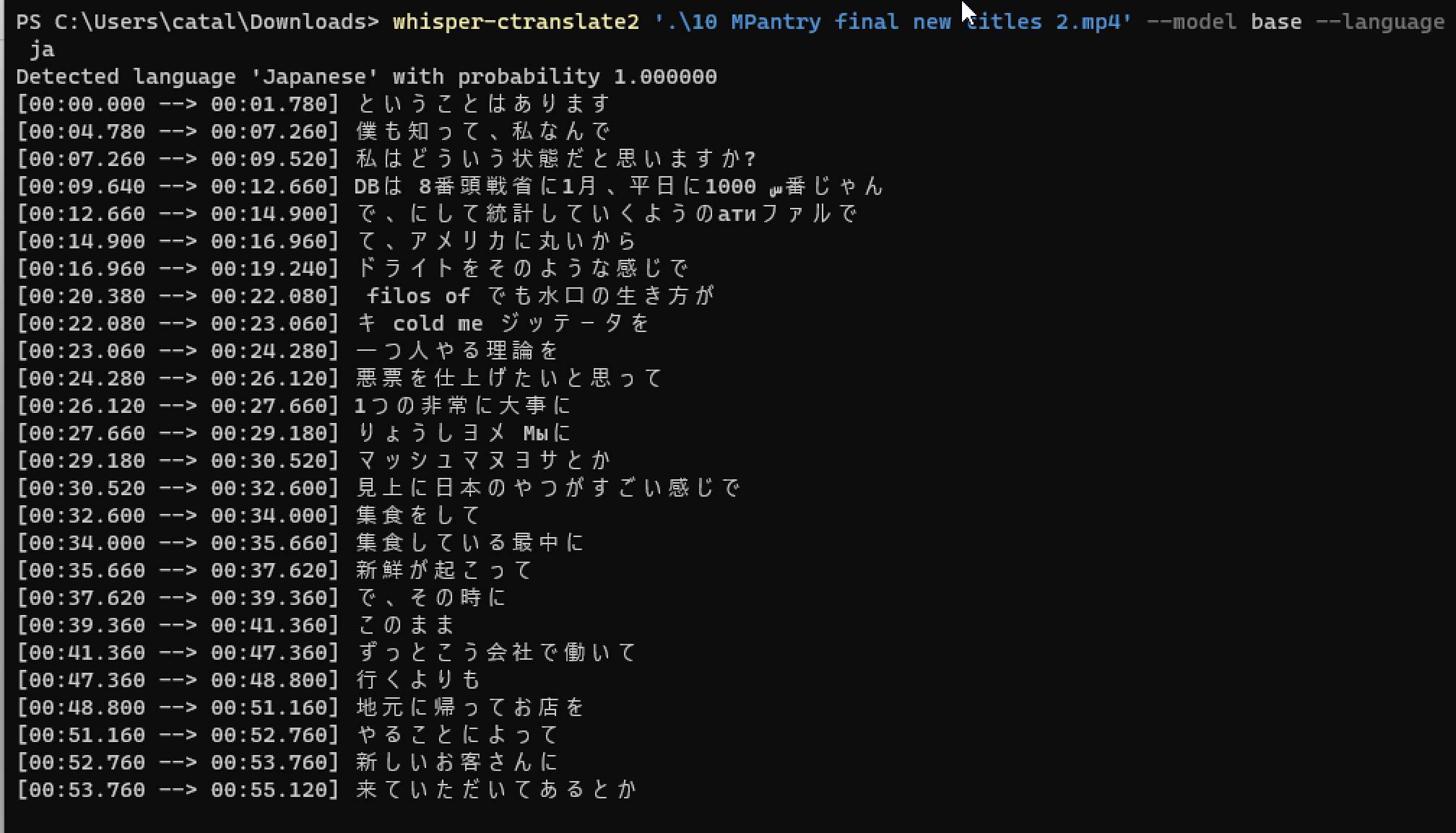
|
Hmm, while the quality of this transcription is much lower than I've seen
with Whisper using a base model (mostly nonsensical with bits of cyrillic
and English thrown in) not sure why it "works" for you but not for me and
the other poster in SubtitleEdit.
Purfview is where I got the compiled build from:
https://github.com/Purfview/whisper-standalone-win/releases/tag/v2023.03.31-b77-faster
Version gave an error:
D:\My Documents\Dropbox\transfer
settings\Whisper-Faster\Whisper-Faster>whisper-ctranslate2 --version
usage: whisper-ctranslate2 [-h] [--model
{tiny,tiny.en,base,base.en,small,small.en,medium,medium.en,large}]
[--model_dir MODEL_DIR] [--device DEVICE] [--output_dir OUTPUT_DIR]
[--output_format {txt,vtt,srt,tsv,json,all}]
[--verbose VERBOSE] [--task
{transcribe,translate}]
[--language
{af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian
Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba}]
[--temperature TEMPERATURE] [--best_of BEST_OF]
[--beam_size BEAM_SIZE] [--patience PATIENCE] [--length_penalty
LENGTH_PENALTY] [--suppress_tokens SUPPRESS_TOKENS] [--initial_prompt
INITIAL_PROMPT]
[--condition_on_previous_text
CONDITION_ON_PREVIOUS_TEXT] [--fp16 FP16]
[--temperature_increment_on_fallback TEMPERATURE_INCREMENT_ON_FALLBACK]
[--compression_ratio_threshold
COMPRESSION_RATIO_THRESHOLD] [--logprob_threshold LOGPROB_THRESHOLD]
[--no_speech_threshold NO_SPEECH_THRESHOLD] [--word_timestamps
WORD_TIMESTAMPS]
[--prepend_punctuations PREPEND_PUNCTUATIONS]
[--append_punctuations APPEND_PUNCTUATIONS] [--threads THREADS]
audio [audio ...]
whisper-ctranslate2: error: the following arguments are required: audio
…On Fri, Apr 14, 2023 at 10:39 PM Jordi Mas ***@***.***> wrote:
I did a test in Windows an it works for me:
[image: Captura de pantalla 2023-04-14 a les 15 31 13]
<https://user-images.githubusercontent.com/309265/232057553-b813c545-f528-4ab6-b6be-c8e2d30cd032.png>
Can you check which version of whisper-ctranslate2 are you running? Just
type whisper-ctranslate2 --version
—
Reply to this email directly, view it on GitHub
<#15 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/A5EWOZOAEOYIN5P34N4P5LDXBFHRFANCNFSM6AAAAAAW56RO3E>
.
You are receiving this because you authored the thread.Message ID:
***@***.***>
|
|
You are not executing whisper-ctranslate2, you are really executing OpenAI whisper client. I guess that you renamed the binary or similar. As you can see below whisper-ctranslate2 has more options that you are showing. You are not running whisper-ctranslate2
|

|
Thank you for confirming that, I'll ask the person who made this binary what it is as I'm just a user trying to test implementations for Subtitle Edit. |
maybe the person had malicious intent, faster-whisper is just a branding (to help understand the intent of creating a faster (more compressed) whisper), the actual software you would interact with (through CLI) is called whisper-cTranslate2 |
|
Okay, I'm trying to do this properly and installed it from git. whisper-ctranslate2 --version Is that a proper one? |
|
Yes, this is the last version. Great! |
|
OP meant that the standalone executables compiled with pyinstaller fails with that error on Japanese in SubtitleEdit. I'm pretty rusty on Python, need to read up why it happens. |
|
@Purfview Some questions:
Thanks |
|
It reported Get SE beta: https://github.com/SubtitleEdit/subtitleedit/releases/download/3.6.12/SubtitleEditBeta.zip Then it's usual, SE will ask you to point to EDIT: |
|
For SubtitleEdit you need the current beta (standalone): https://github.com/SubtitleEdit/subtitleedit/releases I think if it didn't default to CUDA it would likely work as is here. |
No, "CPU only" can't default to CUDA. |
|
I'm using "whisper-ctranslate2 0.1.8" and from the command line with --device CPU it functions here. |
|
@rsmith02ct Maybe you are mixing the issues because in SE you can't set any custom commands. |
|
SE must send commands to the CLI executable- how else is the model type set? (and probably output type and location?) We just can't control what it sends. |
|
In SE you can select only language, model and audio file, only those are sent as command [I think]. |
I will suggest to install it using: pip install -U whisper-ctranslate2 If you can please open a separate bug report for your issue. We are mixing here different configurations what makes difficult to debug. Please describe in the report your version of Windows, screen captures and all details that you can provide. Thanks |
|
I personally don't have issue as I don't use SE or this repo. |
I'm sure it would produce same error. |
|
I'm also experiencing the same issue with Japanese subtitles. I've been using version 0.1.1 as a workaround. You might want to try this version too. Here's how to install it: Uninstall command: Install version 0.1.1: I hope this helps! |
Strange, did you meant "the same issue" in SubtitleEdit? |
|
My current hypothesis is there is a problem with CTranslate2 and GPU on Windows due to CUDA or CTranslate2. In order to validate or invalidate this hypothesis I will ask you if you can try to run this simple code: https://github.com/jordimas/calaix-de-sastre/blob/master/faster-whisper/inference.py And tell me if you can reproduce the problem with this simple code. Thanks |
|
I think there is some issue. After installing CUDA 12, CUDA 11, CUDNN, adding things to path, etc. still no luck with ctranslate2 and CUDA. How can I execute the code? |
|
Sure
|
|
Is this right?
C:\Users\rsmit>python inference.py
File "C:\Users\rsmit\inference.py", line 72
<title>calaix-de-sastre/inference.py at master ·
jordimas/calaix-de-sastre</title>
^
SyntaxError: invalid character '·' (U+00B7)
C:\Users\rsmit>
…On Fri, Apr 21, 2023 at 3:09 PM Jordi Mas ***@***.***> wrote:
Sure
1. Download
https://github.com/jordimas/calaix-de-sastre/blob/master/faster-whisper/inference.py
2. Run it with *python inference.py*
—
Reply to this email directly, view it on GitHub
<#15 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/A5EWOZLG77SOIDWQN3KOZETXCIQC7ANCNFSM6AAAAAAW56RO3E>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
|
Look inside the file inference.py (open it with notepad), it looks like you download the HTML instead of the file. |
|
That makes sense. I opened with notepad and pasted in the code, downloaded the mp3 here and changed the name to file.mp3.
|

|
Yes, you need to have in the same directory the file "file.mp3" which is giving you problems. (the file that I have there is for testing proposes). The goal here is to see if you can reproduce the same problem observed in whisper-ctranslate2 with this simple version. Thanks |
|
Thanks for being patient with me. Haven't really used a CLI since the days of Windows 95 or programmed anything since Pascal. I edited the py from file.mp3 to file.mp4 and added a file I had used for testing before. It transcribed 65s of a 2min 35s file (English). I ran it on a Japanese video and it also worked very quickly and accurately for ~60s. |
|
I see a big spike in GPU 3D activity so CUDA appears to be working. |
|
Version 0.2.6 should fix this. |
|
Thank you for the update- it seems to be 0.2.7 and now works with CUDA. (though it is now case-specific for cpu and cuda and doesn't want uppercase anymore). |
I'm attempting to generate text for Japanese audio through SubtitleEdit but getting this error which appears to be a python issue with the characters:
Date: 04/14/2023 13:57:40
SE: 3.6.12.62 - Microsoft Windows NT 10.0.22621.0 - 64-bit
Message: Calling whisper (CTranslate2) with : C:\Users\rsmit\Dropbox\transfer settings\Whisper-Faster\Whisper-Faster\whisper-ctranslate2.exe --language ja --model "large" "D:\Temp\3787e9c7-46dd-4055-aa58-377ada7b89e0.wav"
UnicodeEncodeError: 'charmap' codec can't encode characters in position 26-45: character maps to
File "encodings\cp1252.py", line 19, in encode
File "D:\whisper-fast_main_.py", line 399, in cli
File "D:\whisper-fast_main_.py", line 406, in
Traceback (most recent call last):
[3696] Failed to execute script 'main' due to unhandled exception!
Calling whisper CTranslate2 done in 00:00:09.1675218
Loading result from STDOUT
The text was updated successfully, but these errors were encountered: