用尽可能少的代码,做尽可能多的事
这是一个相对简陋也非常轻量的ETL(Extract-Transform-Load)工具, 如果你有数据接口对接的业务场景,你可以参考它。
它会以数据库配置的方式,帮助你实现数据接口对接,减少重复编码的工作量。同时可以随时灵活调整、降低后续业务调整带来的影响。
它的核心代码只有三页,分别是EtlExtractService (数据抽取类)、EtlProcessService (数据处理类)、EtlLoadService (数据加载类);
更多信息可访问我的个人博客 https://leeblog.icu
数据抽取(Extract) -> 数据处理(Transform) -> 数据加载(Load)
- java 1.8+
- mysql5.6+
以下均为示例,作者很狗的找了个百度文库的接口来作请求
对接百度文库接口将返回书籍数据存入本地表demo_wenku_book中。
接口数据结构示例:
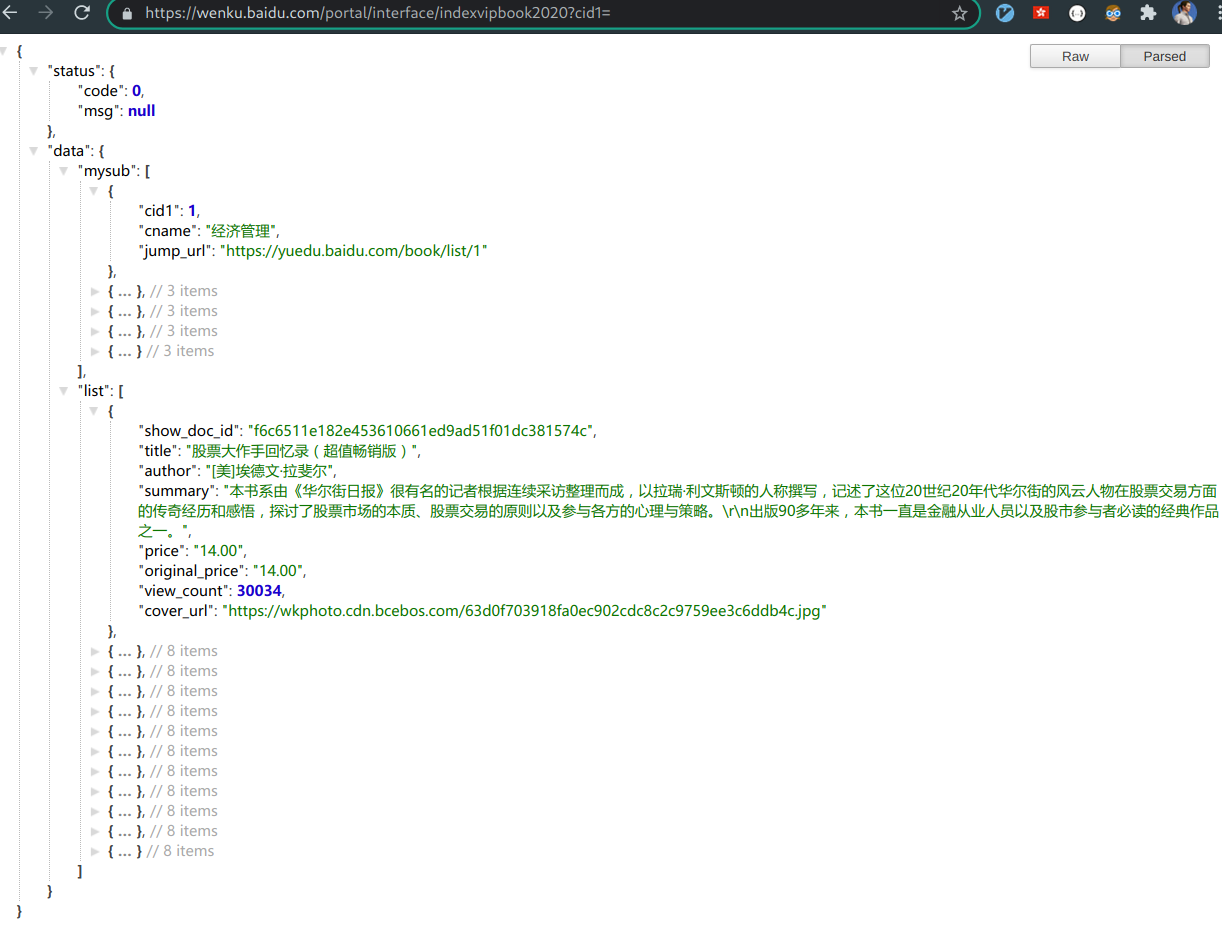
目标表表结构

- 将接口信息录入etl_source表

etl_source表字段意义解释:
source_key:一个数据同步任务的自定义标识,后面调用etl执行同步时会需要传入此标识
source_url:接口全路径,支持https调用
request_method:接口请求方式,‘GET’,‘post’等,不区分大小写
content_type:当前示例需求中并不需要。接口传参类型,支持0:form、1:json、2:urlencoded传参
process_method:接口数据处理方式,支持0:同步处理(同步进入数据处理及加载逻辑),1:异步处理(异步进入数据处理及加载逻辑),2:自定义处理(不进入数据处理及加载逻辑)
remark: 自定义备注
2.将数据处理规则录入etl_data_process_rule表

etl_data_process_rule表字段意义解释:
source_key:一个数据同步任务的自定义标识,同我们第一步中自定义的标识
data_key:源数据json结构中字段位置,data.list[].show_doc_id 中,[]标识为数组
has_mapping:当前示例需求中并不需要。该字段含义是是否需要联查当前数据库中其他字段值来替换,它应用的业务场景如:我们现有一张书籍分类表,源数据结构给了一个书籍分类字段"哲学",而我们需要转换成分类表对应id并给demo_wenku_book存入。
mapping_id:当前示例需求中并不需要。业务场景同上,该字段用于指定联查操作(etl_data_process_mapping)
has_distinct:当前示例需求中并不需要。标识是否需以此字段进行数据去重
target_table:对应存入表表名,该示例需求下为demo_wenku_book
target_columns:对应存入表字段字段名
default_value:源数据字段值为空时的默认值,无默认值为null
exec_sort:该示例需求中并不需要。一个数据同步任务下支持多次数据处理操作,该字段指定了数据处理的执行顺序。业务场景如:先将源数据的书籍分类信息去重存入分类表,再将源数据的书籍信息存入书籍表
exec_type:数据处理后的加载操作类型,支持insert(新增),replace(替换),update(修改),delete(删除),insert or update(根据条件动态新增或修改),java(执行一段java函数)
is_condition:该示例需求中并不需要。该字段的意义是是否为条件字段,条件字段应用于update、delete、insert or update操作类型。
condition_symbol:该示例需求中并不需要。该字段的意义是条件字段的比较符,支持 =``<``<=。当操作类型为java时,该字段用于指明java函数的入参类型(String/Integer)
remark:自定义备注
3.调用EtlExtractService.executorClient执行数据同步
void executorClient(@NotNull String sourceKey,
Map<String, Object> param,
Map<String, String> header)方法参数:
sourceKey:一个数据同步任务的自定义标识
param:该示例需求中并不需要。接口请求参数,这个其实也可以做成动态自定义而无需硬编码的,看实际需求业务场景
header:该示例需求中并不需要。接口请求头部信息,同上
所以该示例需求下这么调用一下:
etlExtractService.executorClient("wenku-book",
new HashMap<>(0),new HashMap<>(0));啊哦,肝到这里出了几个问题:
1.项目启动数据库一直连接不上,时区问题驱动版本问题都排查了个遍,最终在application配置文件上找到了原因:我们项目用的yml格式文件,
yml对小数点的解析有问题,而我嫖阿里的rds密码正好就有一个小数点,害,yml改不了俺改。
2.demo表忘记加主键自增了,这个倒没花啥时间
3.Data too long for column 'summary' at row 2,源数据返回的书籍简介超长了,问题不大,加大加长demo表对应字段的长度
ok继续
有了:
(看来大家都有一个发财梦)

与此同时我们的etl_source_data表中也多了一条数据,嗯是两条:
第一条是一条因为数据过长加载失败的记录。第二条最后成功加载的记录。
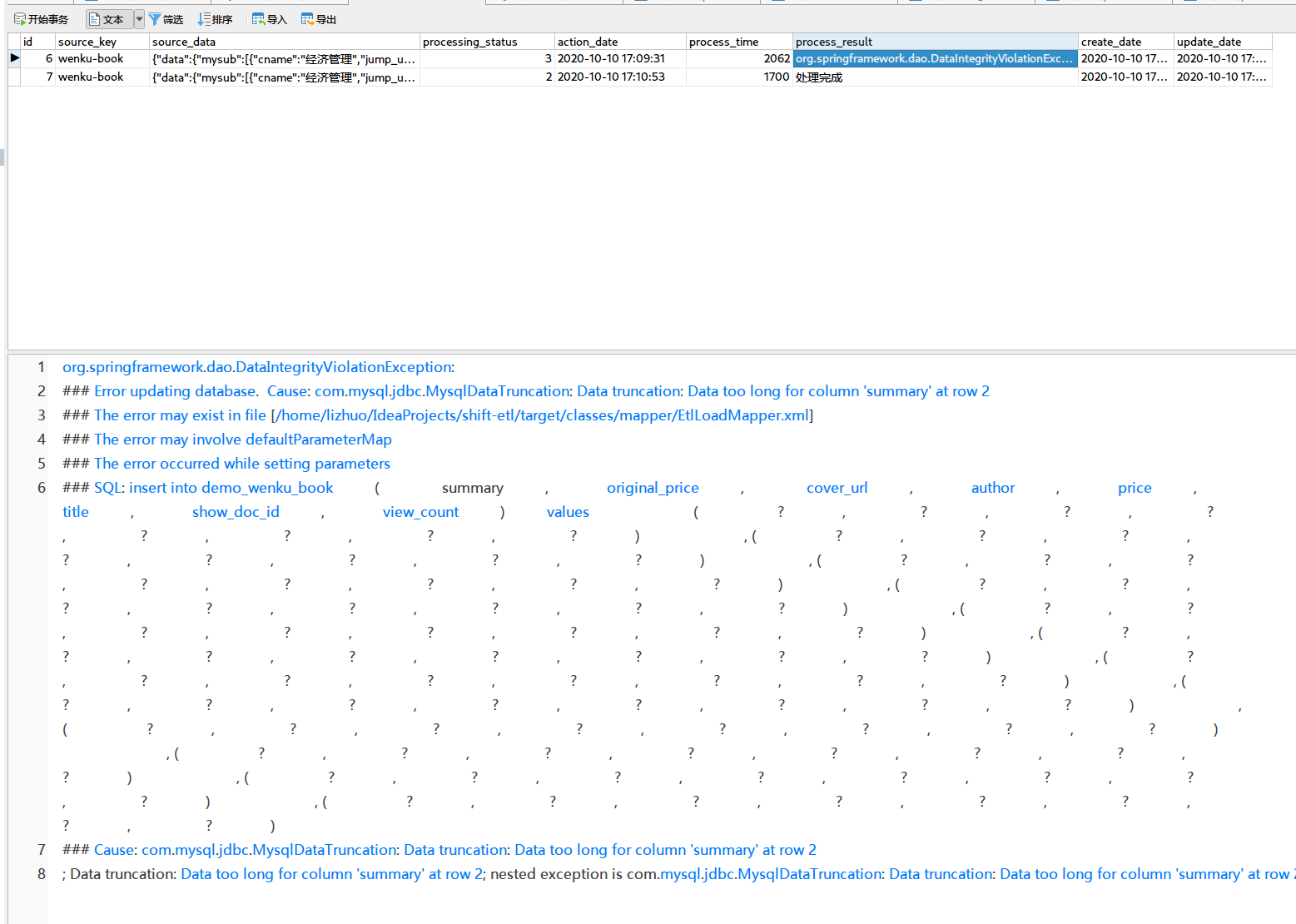
etl_source_data表字段意义解释:
source_key:一个数据同步任务的自定义标识,无需赘述
source_data:同步回来的源数据
processing_status:数据处理/加载状态0-未处理1-处理中,2-处理完成 3-处理失败
action_date:开始处理时间
process_time:处理及加载耗时(毫秒),我这里网络不好所以耗时较长,正常百毫秒
process_result:处理结果,处理状态失败的话这里会保存错误信息,便于排查
以上,啰嗦那么多其实操作就简单三步
shift etl能做到的不止如此,更多玩法明天再写,溜了。。。
ps:调用代码俺写在了test目录下,可以搞下来自己试运行下来.实际业务场景下大多是以定时器定时触发同步任务,而同步任务动态参数逻辑可以在定时任务中实现