Architecture
The implementation of Nutmeg has two parts: the compiler and the runner. The compiler's job is to take a bunch of source files and create an executable object, which we call the bundle file. The bundle-file is actually a SQLITE database who tables contain a lot of (indexed) JSON text that encode a program. The runner loads the program from the bundle file and then executes the program.

The compiler orchestrates a sequence of filter-like components such as parser, resolver and code-generator. The chain of components starts with the contents of a single file, transform it and then pass it along to the next component, and so on until the final component. The final component has the responsibility of stuffing the contents into the bundle-file.
For the purposes of development, we can actually invoke the components separately. For example we can parse the expression 'x + 1' like this:
% echo 'x + 1' | nutmeg parse
{
"arguments": {
"body": [
{
"kind": "id",
"name": "x",
"reftype": "get"
},
{
"kind": "int",
"value": "1"
}
],
"kind": "seq"
},
"kind": "syscall",
"name": "+"
}
The full pipeline is illustrated in the next picture, which gives snapshots of the intermediate stages.
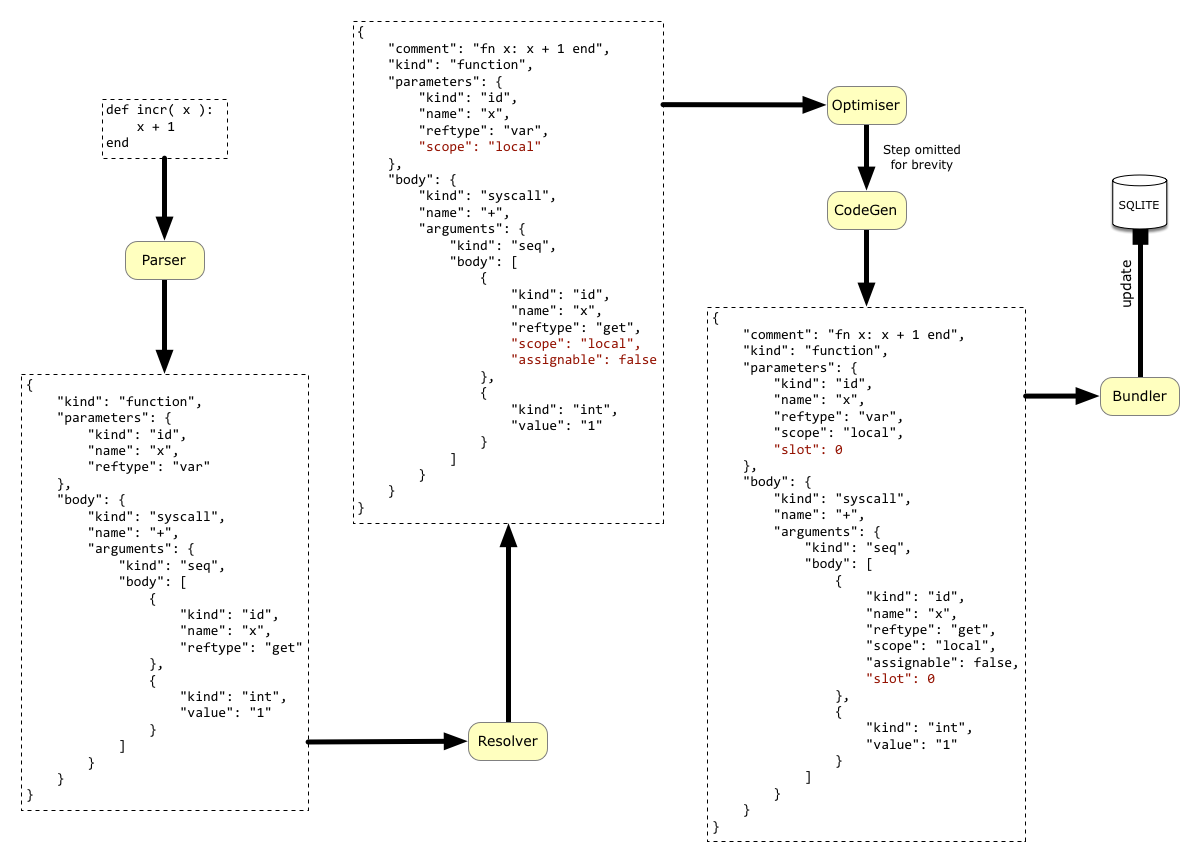
The bundle file is a SQLITE database, which is to say a single file that can be used like a SQL database. The bundle contains the compiled Nutmeg source code plus file-like assets (images, CSV data etc) that the program might need at run-time. This is intended to make it possible to deliver a wide variety of programs as a single file and avoid the necessity of self-homing, which is a long-running nightmare on UNIX systems.
The key table is called Bindings, which maps the name of variables from the source files into their compiled JSON form.
| IdName | Value |
|---|---|
| hello | { "kind": "function", "parameters": { "kind": "seq", "body": [] }, "body": { "kind": "syscall", "name": "println", "arguments": { "kind": "id", "name": "msg", "reftype": "get" } } } |
| msg | { "kind": "string", "value": "hello, world!" } |
Another table called EntryPoints, tells the runner which variables needed to be loaded from the Bindings table for a given entry-point. This means that a single bundle can contain multiple programs (entry-points) that have a lot of shared libraries but when a particular program runs only the stuff that it needs actually gets loaded.
The runner is used to run a compiled Nutmeg program that has been packed into a bundle file. It starts from a bundle-file, an entry-point and some command-line options. The command-line options may be for the runner or for the Nutmeg program - the two being distinguished by whether they come before or after the bundle-file argument respectively.
The runner will load all the bindings that are required by the entry-point into main memory, deserialising them from JSON on-the-fly. This initial loaded form is then transformed into a more efficient runnable-graph of 'Runlet' objects, where the control flow is represented by pointers from one object to the next. This means that if-statements become forks in the graphs and loops become circles in the graph. These transformed Runlets are installed into a top-level dictionary.
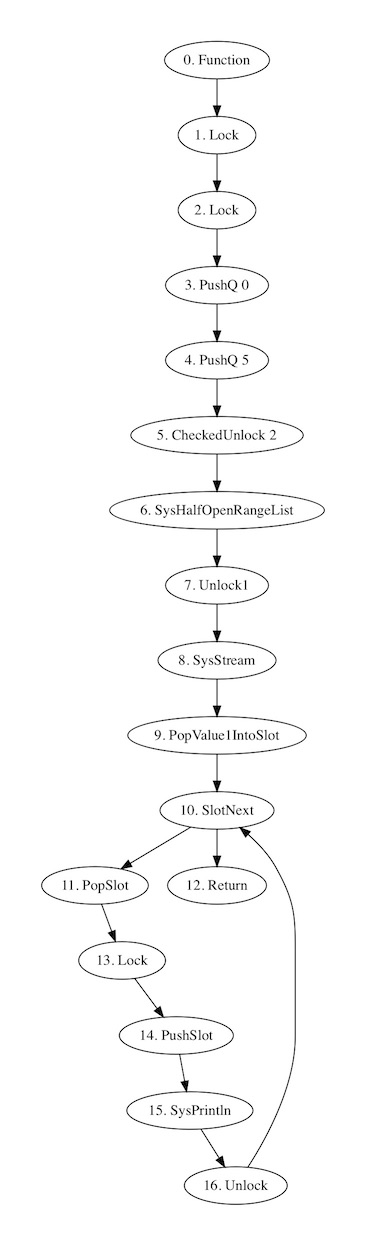
To help with debugging, Runlet graphs can be dumped in graphviz format, which is an ASCII format, using the --graphviz option. Here is an output showing the code generated for an iteration over a half-open range: