


- Introduction
- Repository Status Update
- Quick Start
- Installation
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- Contributing
- License
- Get in Touch
Disclaimer: This project is not officially associated with DeepSeek AI. It is an independent reverse engineering effort to explore the DeepSeek Chat Website.
🚀 Repository Status Update:
🛑 Important Notice:
This repository is no longer maintained by the owner Devs Do Code (Sree). Any contribution in this repository is heartily welcomed 💝💝
-
Clone the Repository:
git clone https://github.com/SreejanPersonal/DeepSeek-API-Unofficial.git
-
Access the DeepSeek Playground:
- Navigate to the DeepSeek Playground and sign in with your account.
- This platform allows you to interact with the available models and observe API requests.
-
Access Developer Tools:
- Open the Developer Tools in your browser with
Ctrl + Shift + I(Windows/Linux) orCmd + Option + I(Mac). - Select the
Networktab to monitor network activity.
- Open the Developer Tools in your browser with
-
Initiate a New Conversation:
- Choose any available model (e.g., Coder v2 or Chat v2) on the DeepSeek Playground to start a conversation.
- Enter a query in the chat interface, such as
Hi, Introduce yourself.
-
Locate the
completionsRequest:- In the
Networktab, find the API request labeledcompletions. - Click on this request to inspect its details.
- In the
-
Obtain the JWT Token:
- In the
Request Headerssection, locate theAuthorizationentry. - Copy the
JWT Tokenvalue (it appears as a long string without theBearerprefix). This token serves as your API key and must be kept confidential. - Example format:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzc29faWQiOiI3OTg3ZTZmYS1kZDUzLTRlMzQtYjkxNC1lNWUzZWVlM2IwYjMiLCJpc19vYXV0aCI6MSwib2F1dGhfcHJvdmlkZXIiOiJ......
- In the
After cloning the repository and obtaining your JWT Token, follow these steps to set up and run the project:
-
Navigate to the Project Directory:
cd DeepSeek-API-Unofficial -
Create a
.envFile:- Inside the project directory, create a
.envfile. - Add your
JWT Tokento this file. You can use the provided .env.example file as a reference.
cp .env.example .env
- Open the
.envfile and insert your token:
DEEPSEEK=your_jwt_token_here - Inside the project directory, create a
-
Install Required Dependencies:
- Ensure you have
pipinstalled and run:
pip install -r requirements.txt
- Ensure you have
-
Run the Application:
- Execute the main script to start interacting with the DeepSeek API:
python main.py
By following these steps, you will set up the environment and be able to interact with the DeepSeek models using the unofficial API.
Today, we’re introducing DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger performance, and meanwhile saves 42.5% of training costs, reduces the KV cache by 93.3%, and boosts the maximum generation throughput to 5.76 times.


We pretrained DeepSeek-V2 on a diverse and high-quality corpus comprising 8.1 trillion tokens. This comprehensive pretraining was followed by a process of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to fully unleash the model's capabilities. The evaluation results validate the effectiveness of our approach as DeepSeek-V2 achieves remarkable performance on both standard benchmarks and open-ended generation evaluation.
- 2024.05.16: We released the DeepSeek-V2-Lite.
- 2024.05.06: We released the DeepSeek-V2.
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 16B | 2.4B | 32k | 🤗 HuggingFace |
| DeepSeek-V2-Lite-Chat (SFT) | 16B | 2.4B | 32k | 🤗 HuggingFace |
| DeepSeek-V2 | 236B | 21B | 128k | 🤗 HuggingFace |
| DeepSeek-V2-Chat (RL) | 236B | 21B | 128k | 🤗 HuggingFace |
Due to the constraints of HuggingFace, the open-source code currently experiences slower performance than our internal codebase when running on GPUs with Huggingface. To facilitate the efficient execution of our model, we offer a dedicated vllm solution that optimizes performance for running our model effectively.
| Benchmark | Domain | LLaMA3 70B | Mixtral 8x22B | DeepSeek-V1 (Dense-67B) | DeepSeek-V2 (MoE-236B) |
|---|---|---|---|---|---|
| MMLU | English | 78.9 | 77.6 | 71.3 | 78.5 |
| BBH | English | 81.0 | 78.9 | 68.7 | 78.9 |
| C-Eval | Chinese | 67.5 | 58.6 | 66.1 | 81.7 |
| CMMLU | Chinese | 69.3 | 60.0 | 70.8 | 84.0 |
| HumanEval | Code | 48.2 | 53.1 | 45.1 | 48.8 |
| MBPP | Code | 68.6 | 64.2 | 57.4 | 66.6 |
| GSM8K | Math | 83.0 | 80.3 | 63.4 | 79.2 |
| Math | Math | 42.2 | 42.5 | 18.7 | 43.6 |
| Benchmark | Domain | DeepSeek 7B (Dense) | DeepSeekMoE 16B | DeepSeek-V2-Lite (MoE-16B) |
|---|---|---|---|---|
| Architecture | - | MHA+Dense | MHA+MoE | MLA+MoE |
| MMLU | English | 48.2 | 45.0 | 58.3 |
| BBH | English | 39.5 | 38.9 | 44.1 |
| C-Eval | Chinese | 45.0 | 40.6 | 60.3 |
| CMMLU | Chinese | 47.2 | 42.5 | 64.3 |
| HumanEval | Code | 26.2 | 26.8 | 29.9 |
| MBPP | Code | 39.0 | 39.2 | 43.2 |
| GSM8K | Math | 17.4 | 18.8 | 41.1 |
| Math | Math | 3.3 | 4.3 | 17.1 |
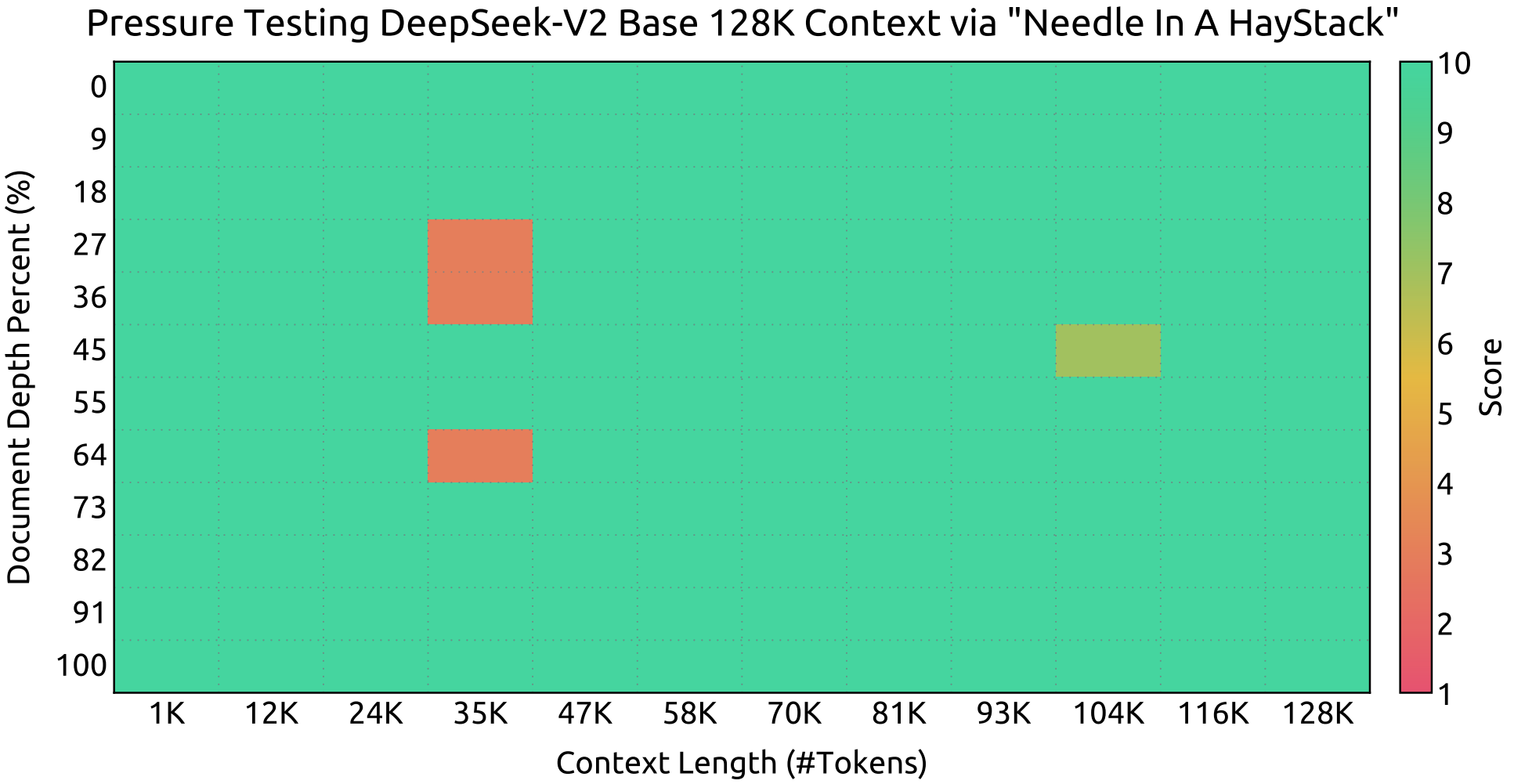
Evaluation results on the Needle In A Haystack (NIAH) tests. DeepSeek-V2 performs well across all context window lengths up to 128K.
| Benchmark | Domain | QWen1.5 72B Chat | Mixtral 8x22B | LLaMA3 70B Instruct | DeepSeek-V1 Chat (SFT) | DeepSeek-V2 Chat (SFT) | DeepSeek-V2 Chat (RL) |
|---|---|---|---|---|---|---|---|
| MMLU | English | 76.2 | 77.8 | 80.3 | 71.1 | 78.4 | 77.8 |
| BBH | English | 65.9 | 78.4 | 80.1 | 71.7 | 81.3 | 79.7 |
| C-Eval | Chinese | 82.2 | 60.0 | 67.9 | 65.2 | 80.9 | 78.0 |
| CMMLU | Chinese | 82.9 | 61.0 | 70.7 | 67.8 | 82.4 | 81.6 |
| HumanEval | Code | 68.9 | 75.0 | 76.2 | 73.8 | 76.8 | 81.1 |
| MBPP | Code | 52.2 | 64.4 | 69.8 | 61.4 | 70.4 | 72.0 |
| LiveCodeBench (0901-0401) | Code | 18.8 | 25.0 | 30.5 | 18.3 | 28.7 | 32.5 |
| GSM8K | Math | 81.9 | 87.9 | 93.2 | 84.1 | 90.8 | 92.2 |
| Math | Math | 40.6 | 49.8 | 48.5 | 32.6 | 52.7 | 53.9 |
| Benchmark | Domain | DeepSeek 7B Chat (SFT) | DeepSeekMoE 16B Chat (SFT) | DeepSeek-V2-Lite 16B Chat (SFT) |
|---|---|---|---|---|
| MMLU | English | 49.7 | 47.2 | 55.7 |
| BBH | English | 43.1 | 42.2 | 48.1 |
| C-Eval | Chinese | 44.7 | 40.0 | 60.1 |
| CMMLU | Chinese | 51.2 | 49.3 | 62.5 |
| HumanEval | Code | 45.1 | 45.7 | 57.3 |
| MBPP | Code | 39.0 | 46.2 | 45.8 |
| GSM8K | Math | 62.6 | 62.2 | 72.0 |
| Math | Math | 14.7 | 15.2 | 27.9 |
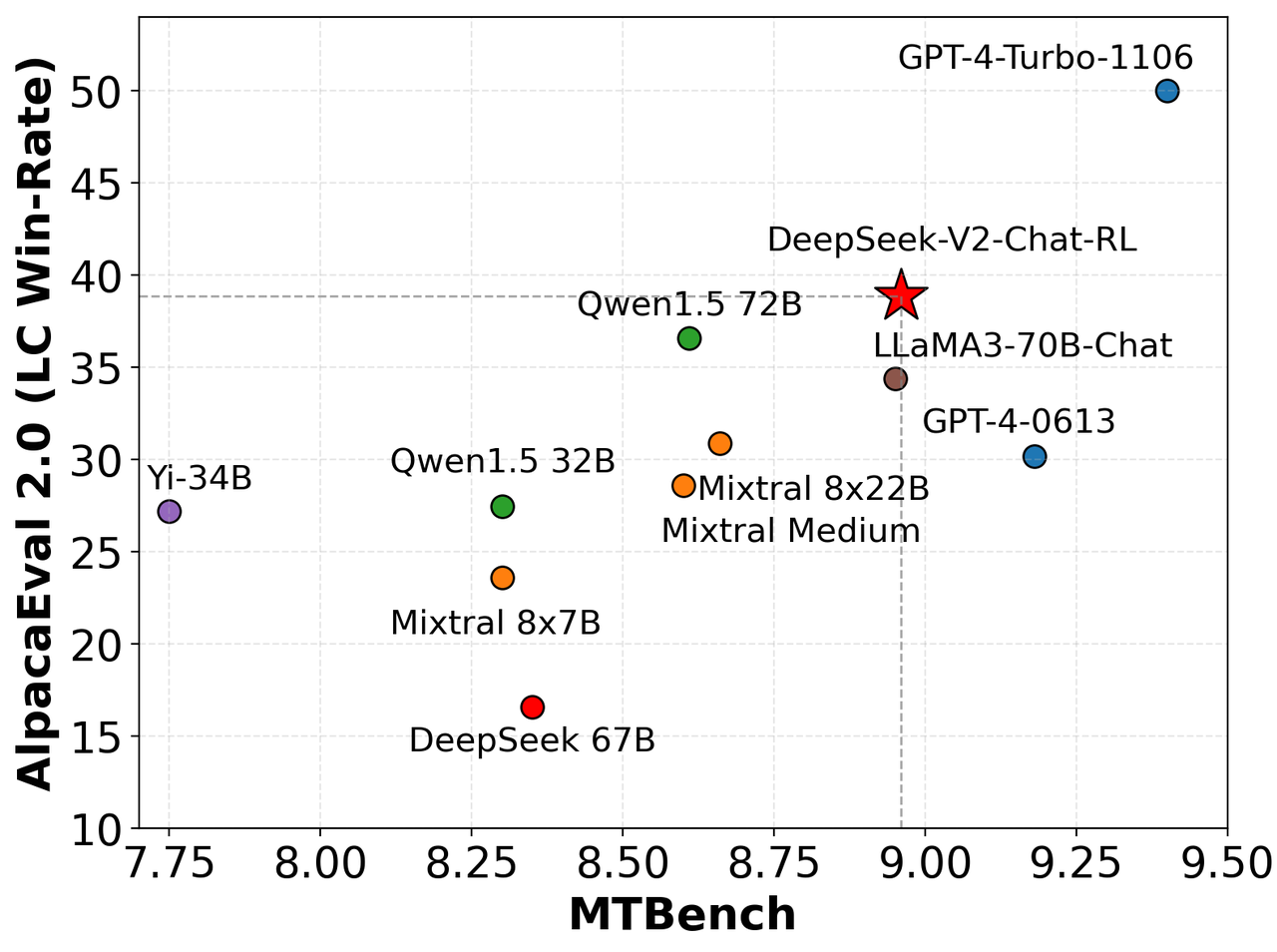
We evaluate our model on AlpacaEval 2.0 and MTBench, showing the competitive performance of DeepSeek-V2-Chat-RL on English conversation generation.
Alignbench (https://arxiv.org/abs/2311.18743)
| 模型 | 开源/闭源 | 总分 | 中文推理 | 中文语言 |
|---|---|---|---|---|
| gpt-4-1106-preview | 闭源 | 8.01 | 7.73 | 8.29 |
| DeepSeek-V2 Chat (RL) | 开源 | 7.91 | 7.45 | 8.36 |
| erniebot-4.0-202404 (文心一言) | 闭源 | 7.89 | 7.61 | 8.17 |
| DeepSeek-V2 Chat (SFT) | 开源 | 7.74 | 7.30 | 8.17 |
| gpt-4-0613 | 闭源 | 7.53 | 7.47 | 7.59 |
| erniebot-4.0-202312 (文心一言) | 闭源 | 7.36 | 6.84 | 7.88 |
| moonshot-v1-32k-202404 (月之暗面) | 闭源 | 7.22 | 6.42 | 8.02 |
| Qwen1.5-72B-Chat (通义千问) | 开源 | 7.19 | 6.45 | 7.93 |
| DeepSeek-67B-Chat | 开源 | 6.43 | 5.75 | 7.11 |
| Yi-34B-Chat (零一万物) | 开源 | 6.12 | 4.86 | 7.38 |
| gpt-3.5-turbo-0613 | 闭源 | 6.08 | 5.35 | 6.71 |
| DeepSeek-V2-Lite 16B Chat | 开源 | 6.01 | 4.71 | 7.32 |
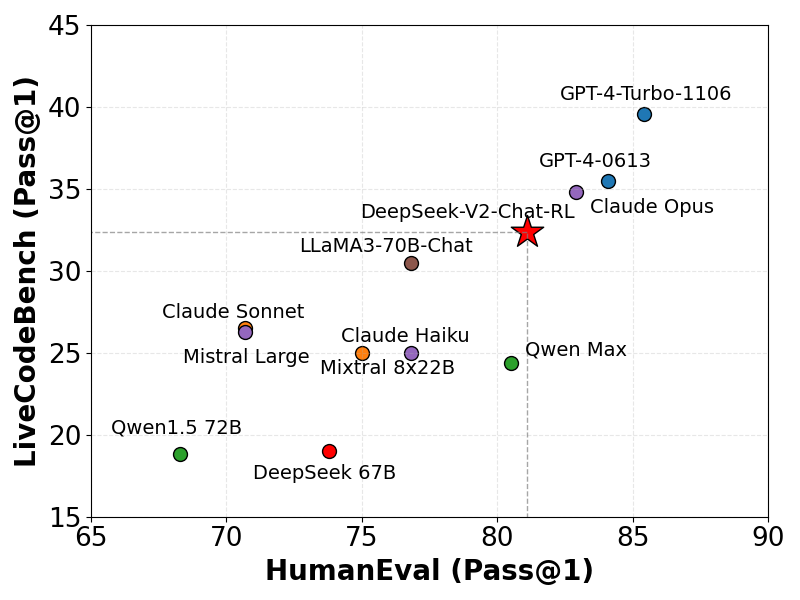
We evaluate our model on LiveCodeBench (0901-0401), a benchmark designed for live coding challenges. As illustrated, DeepSeek-V2 demonstrates considerable proficiency in LiveCodeBench, achieving a Pass@1 score that surpasses several other sophisticated models. This performance highlights the model's effectiveness in tackling live coding tasks.
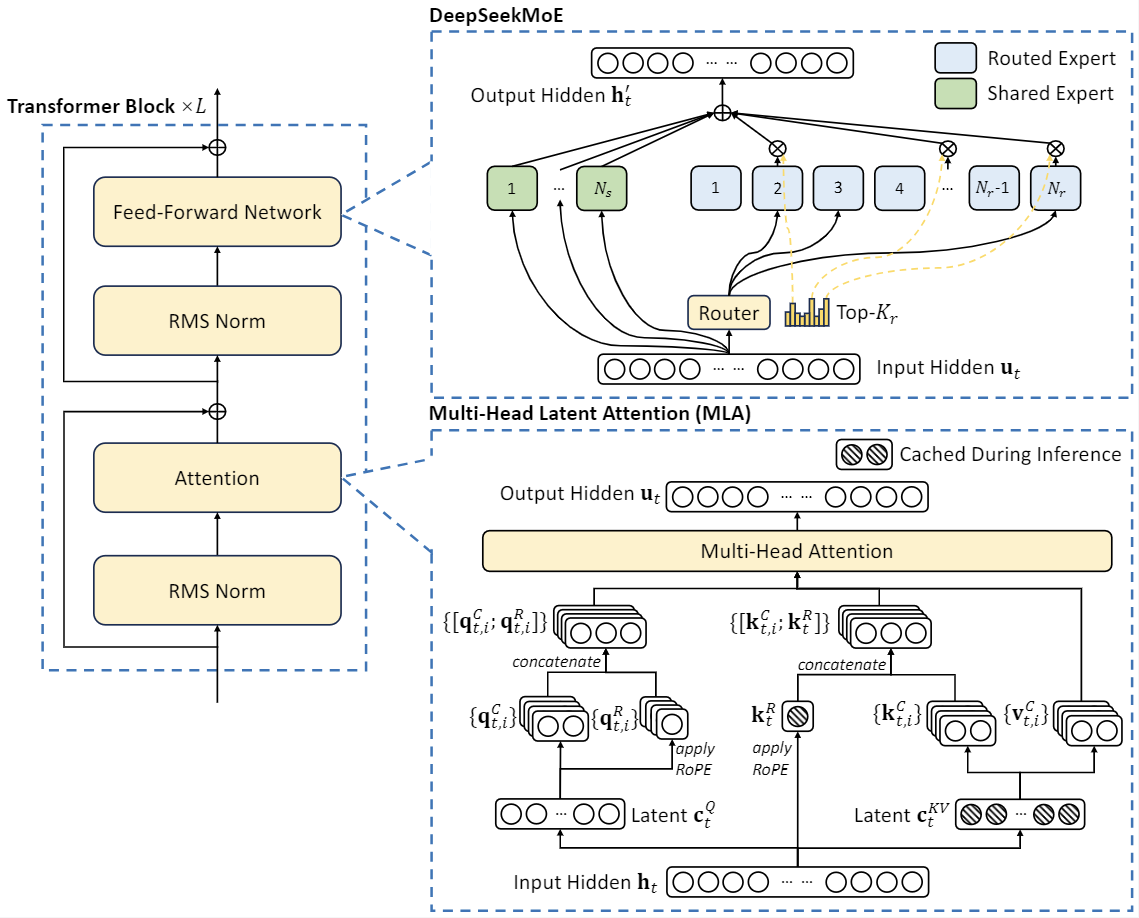
DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference:
- For attention, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eliminate the bottleneck of inference-time key-value cache, thus supporting efficient inference.
- For Feed-Forward Networks (FFNs), we adopt DeepSeekMoE architecture, a high-performance MoE architecture that enables training stronger models at lower costs.
You can chat with the DeepSeek-V2 on DeepSeek's official website: chat.deepseek.com
Your contributions are welcome! Please refer to our CONTRIBUTING.md for contribution guidelines.
This project is licensed under the MIT License. Full license text is available in the LICENSE file.
For inquiries or assistance, please open an issue or reach out through our social channels:
We appreciate your interest in DeepSeek-API-Unofficial