Методика за изчисление на R

[4 октомври 2020]
От тази седмица ползвам нова методология за R, адресираща проблема със седмичния шум и отчитаща най-новите данни за разпределението на генерационните интервали. Изчислението все още е по дата на регистрация на случаите (вместо поява на симптоми), което внася грешка (макар и намалена донякъде заради разглеждането в 7-дневни прозорци). Това не може да се поправи, докато българските власти не публикуват използваем набор от обобщени епидемиологични данни (вкл. данни за поява на симптоми/symptom onset data). Тук обяснявам промените.
- Инкубационен период = времето от зараза до поява на симптоми (липсва, ако заразеният е асимптоматичен, т.е. без симптоми за целия период на инфекция)
- Сериен интервал = времето от поява на симптоми при заразителя до поява на симптоми при заразения (липсва, ако единият от тях е асимптоматичен)
- Генерационен интервал = времето от заразяване на заразителя до заразяване на заразения (винаги наличен, но трудно се определя; не може да е негативен, за разлика от серийния)
От 4-дневни плъзгащи се прозорци по [1] се преминава на 7-дневни прозорци. Това е методологично коректният подход за редуциране на седмичния шум и елиминира нуждата от допълнителна усредняваща крива (която внасяше грешка). Тази промяна е еквивалентна на преминаването от 4-дневна стойност (4TW) към 7-дневна стойност (7TW) по методиката на института Роберт Кох (RKI) [2,3], която ползвах до сега (в 4-дневния вариант).
Методиките за извеждане на R (без техниките за изглаждане/напасване към емпирични данни и отчитане на грешка) се различават единствено в допусканията си за разпределението на генерационните интервали[4]. Ползваната до сега методика на RKI приема константен генерационен интервал, т.е. делта разпределение. Това е екстремен вариант и води до надценяване при силни промени в прираста, и изведената стойност всъщност е теоретична граница за даден среден генерационен интервал[пак там]. (Конкретните стойности по 4TW и 7TW не са теоретични граници заради намалената чувствителност вследствие разглеждането в плъзгащи се прозорци.)
Вече обаче разполагаме с достатъчно добри предварителни данни за формата на разпределението на генерационните интервали[5]. Новият метод взима това разпределение като отправна точка за изчислението на R.
Забележка: В случая на COVID-19 е важно да се отбележи, че разпределението на серийните интервали не може да се ползва директно като апроксимация на генерационните интервали, най-вече заради високата вариация в инкубационните периоди, за което свидетелстват и наблюдаваните негативни серийни интервали (теоретичен преглед в [6]).
RKI работят с генерационен интервал 4 в двете си методики (4TW и 7TW), което се базира на средната стойност от проучвания за серийния интервал (цитирани в т.н. Steckbrief[7]). Заимстването принципно е коректно (въпреки разликите във формата, разпределенията на генерационни и серийни интервали са с еднаква средна стойност[6]), но не е ясно дали такава средна стойност 4 не е прекалено ниска, особено за България. Наблюдаваните по-къси серийни интервали по време на пикови проучвания в засегнати региони изглежда са силно повлияни от мерките за проследяване и изолиране, и евентуално други промени в обществото/поведението, които намалят по-късните предавания (след поява на симптоми), и с това—средната стойност на серийните интервали с хода на епидемията[8]. Не са ми известни данни за това доколко разхлабването на мерките на свой ред връща разпределението към по-ранни (по-високи) стойности, но заради обществените нагласи и по-слабите ресурси на здравните власти, може да се предположи, че средните стойности в България винаги са били по-високи. По-висок среден генерационен интервал (5.5) се изчислява и в [5] (най-прецизното изследване, което съм виждал). Има обаче и противоречащи данни, като екстремният пример е Бразилия, откъдето докладват най-късия досега среден сериен интервал (под 3)[9], въпреки че не тестват много повече от България (на гл. от нас.) и нямат кохерентна национална стратегия за проследяване на контакти (въпреки различни усилия на местно ниво [10]). Както посочват авторите, възможно е данните да съдържат систематична отрицателна грешка заради грешно обхващане на двойки заразител-заразен в клъстери, където реалното заразяване всъщност е по-рано от трето лице.
В крайна сметка съществува несигурност в средната стойност на генерационните интервали (и по-малка несигурност в дисперсията, за която можем да предположим, че трябва да е по-ниска от тази на серийните интервали, които варират до негативност и на практика винаги повече от генерационните[6]). Новият метод за изчисление на R се базира на разпределението на генерационните интервали в [5], вкл. средната стойност 5.5, но отчита несигурността в тази стойност и точната форма на разпределението по метода описан в Web Appendix 4 на [1], позволявайки на средната стойност μᴳ и стандартното отклонение σᴳ да варират в зададени скъсени нормални разпределения, разширявайки достоверните интервали в бейсовата рамка на [1]. За целта се образуват 1000 двойки (μᴳ, σᴳ)ₖ, с изтеглени μᴳₖ > σᴳₖ от скъсените нормални разпределения, като за всеки прозорец и всяка двойка k се тегли извадка с размер 1000 от апостериорното разпределение на R за описаното от k гама разпределение на генерационните интервали (гама параметрите за форма и мащаб се получават чрез трансформация на μᴳ и σᴳ). От получената извадка на съвместното апостериорно разпределение, с размер 1 милион, се изчисляват медиана и квантили за 95% CrI.
Избраните параметри за скъсените нормални разпределения, от които се теглят μᴳ и σᴳ, са съответно:
- N(5.509073, 25) | 4.009073 < μᴳ < 7.009073
- N(2.112571, 0.25) | 1.112571 < σᴳ < 3.112571
За изчисление е ползван пакетът EpiEstim 2.2, представен в [1]. Разпределението на генерационните интервали по [5] е избрано във варианта на гама разпределение, за да може да се използва директно в имплементацията на метод uncertain_si на EpiEstim. Разликата (ΔAIC) с малко по-добре пасващото Вейбул разпределение по [5] е минимална. Медианата на изчисленото R по Вейбул разпредлението много рядко се отмества повече от няколко пиксела: виж графиката за сравнение.
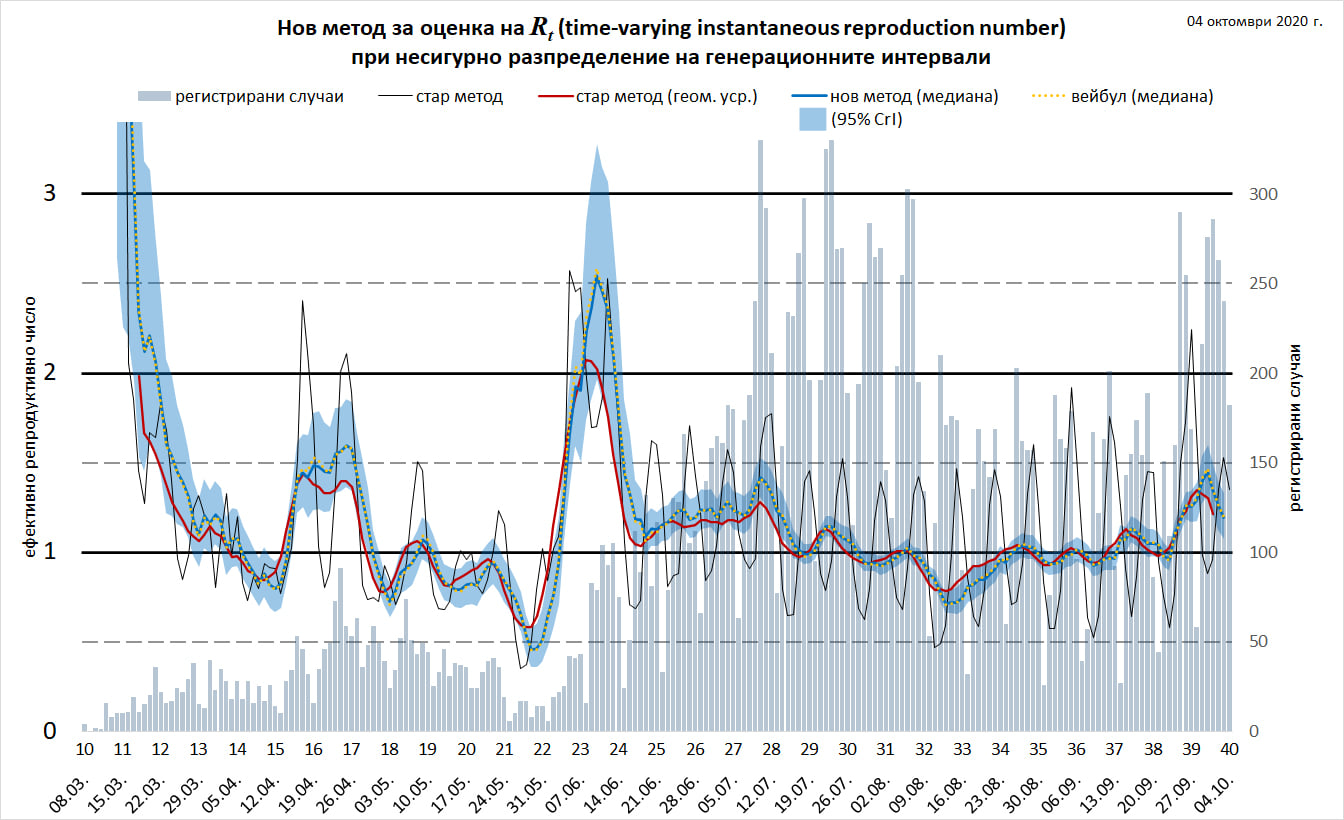
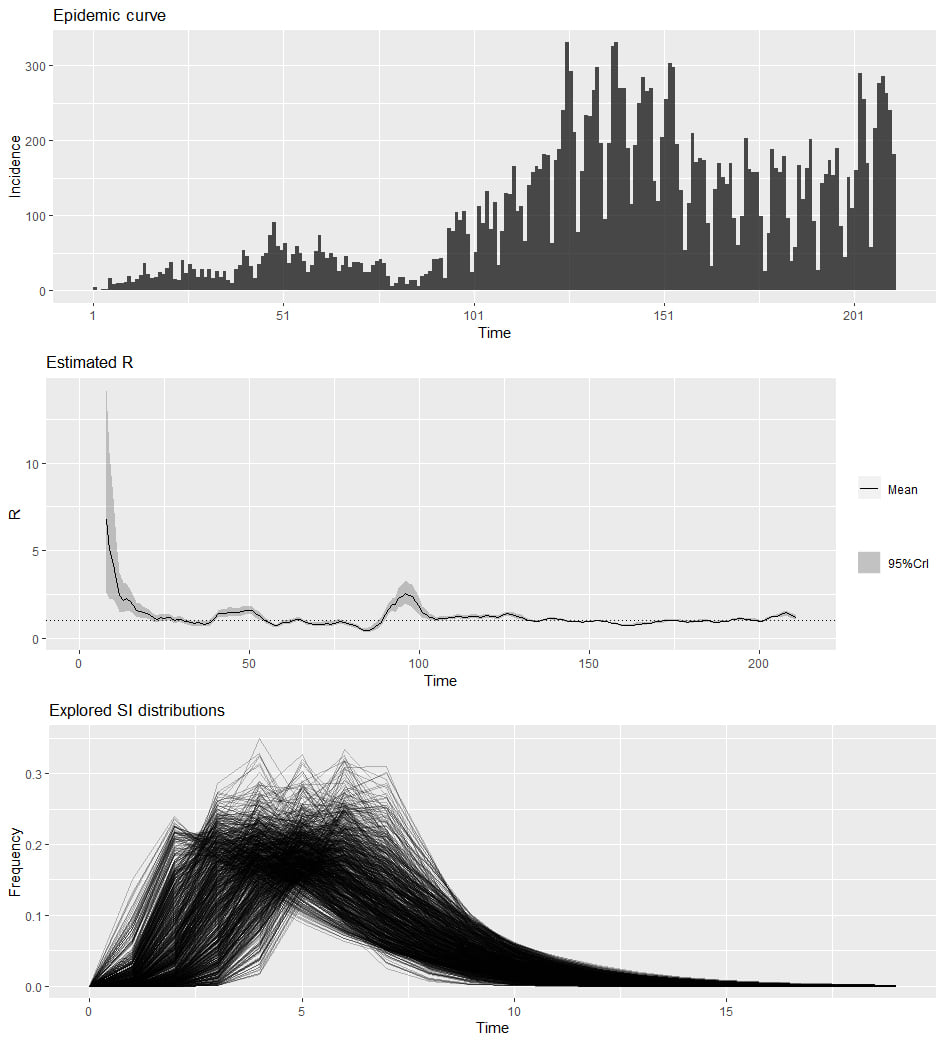
Най-важните ограничения на приложения подход (непреодолими при липса на публикувани епидемиологични данни):
- Случаите се разглеждат по дата на регистрация (вместо поява на симптоми), което внася неизвестна грешка, намалена до някаква степен от разглеждането в плъзгащи се 7-дневни прозорци.
- Не се разглежда промяната на генерационния интервал във времето (виж [8]).
- Внесените от чужбина случаи не се третират специално, което може да води до голяма, неотчетена грешка в ранния етап. (При наличие на данни, има метод за отчитане, надграждащ зададения модел в EpiEstim[11].)
виж файл c19_estimate_r.R
- [1] Cori А et al., “A New Framework and Software to Estimate Time-Varying Reproduction Numbers During Epidemics,” Am J Epidemiol, vol. 178, no. 9, pp. 1505–1512, Nov. 2013, https://doi.org/10.1093/aje/kwt133.
- [2] Robert Koch-Institut, “Erläuterung der Schätzung der zeitlich variierenden Reproduktionszahl R,” https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Projekte_RKI/R-Wert-Erlaeuterung.pdf?__blob=publicationFile'
- [3] Robert Koch-Institut, “Epidemiologisches Bulletin 17/2020,” https://www.rki.de/DE/Content/Infekt/EpidBull/Archiv/2020/Ausgaben/17_20.pdf?__blob=publicationFile
- [4] Wallinga J, Lipsitch M, “How generation intervals shape the relationship between growth rates and reproductive numbers,” Proc. R. Soc. B., vol. 274, no. 1609, pp. 599–604, Feb. 2007, https://doi.org/10.1098/rspb.2006.3754.
- [5] Ferretti L et al., “The timing of COVID-19 transmission,” medRxiv preprint, Sep. 2020. https://doi.org/10.1101/2020.09.04.20188516.
- [6] Lehtinen S et al., “On the relationship between serial interval, infectiousness profile and generation time,” medRxiv preprint, Sep. 2020. https://doi.org/10.1101/2020.09.18.20197210. [Now published: Lehtinen S et al., “On the relationship between serial interval, infectiousness profile and generation time,” J. R. Soc. Interface 18, Jan. 2021, https://doi.org/10.1098/rsif.2020.0756.]
- [7] Robert Koch-Institut, “SARS-CoV-2 Steckbrief zur Coronavirus-Krankheit-2019 (COVID-19).” https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Steckbrief.html
- [8] Ali ST et al., “Serial interval of SARS-CoV-2 was shortened over time by nonpharmaceutical interventions,” Science, vol. 369, no. 6507, pp. 1106–1109, Aug. 2020, https://doi.org/10.1126/science.abc9004.
- [9] Prete CA et al., “Serial interval distribution of SARS-CoV-2 infection in Brazil,” Journal of Travel Medicine, taaa115, Jul. 2020, https://doi.org/10.1093/jtm/taaa115.
- [10] Ponce D, “The impact of coronavirus in Brazil: politics and the pandemic,” Nature Reviews Nephrology, vol. 16, no. 9, Art. no. 9, Sep. 2020, https://doi.org/10.1038/s41581-020-0327-0.
- [11] Thompson RN et al., “Improved inference of time-varying reproduction numbers during infectious disease outbreaks,” Epidemics, vol. 29, p. 100356, Dec. 2019, https://doi.org/10.1016/j.epidem.2019.100356.