In this machine learning project, I used the best method I think to process data. There is still much room to improve the accuracy of 76%. If you have any suggestions for this, please leave a message!
The competition is simple: use machine learning to create a model that predicts which passengers survived the Titanic shipwreck.
It is your job to predict if a passenger survived the sinking of the Titanic or not. For each in the test set, you must predict a 0 or 1 value for the variable.
 I achieved an accuracy rate of 0.7679 in the public ranking list, and ranked the top 20% of all Kagglers except for cheating. I am used to using colab for experiments, but because it is an ipynb standard file, you can also use jupyter notebook.
I achieved an accuracy rate of 0.7679 in the public ranking list, and ranked the top 20% of all Kagglers except for cheating. I am used to using colab for experiments, but because it is an ipynb standard file, you can also use jupyter notebook.
- Survived: if this passenage died or survived.
- Pclass: It divides passante into different levels from one to three.
- SibSp:SibSp is the number of siblings or spouses of a person onboard.
- Parch:It contained the number of parents or children each passenger was touring with.
- Fare: The cost of a ticket.
- Embarked:Southampton, Cherbourg, and Queenstown.
My data has gone through the following steps Exploratory data analysis with visualization function
- Data cleaning
- Feature engineering
- Modeling
- Test accuracy(Cross validation may be a good way to verify the accuracy of different models. Compared with the cross-validation model, I prefer to submit the answer directly at kaggle to compare the accuracy)
- K-NN
- Decision tree
- Random Forest
- Stochastic Gradient Descent
- Logistic Regression
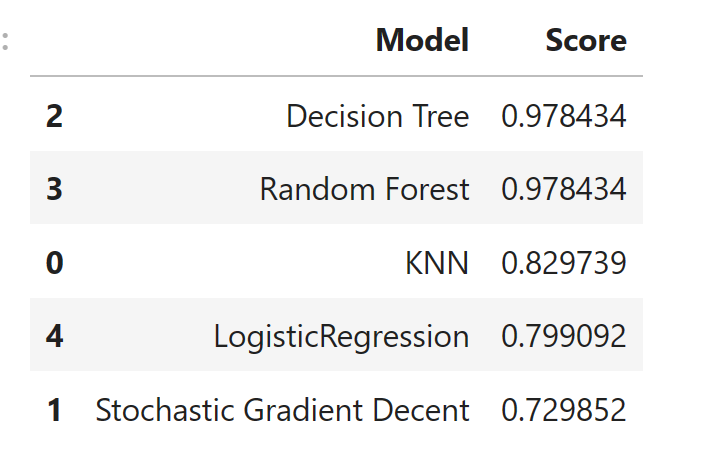
The random forest and the decision tree are overfitting. After comparing the accuracy of KNN, LogisticRegression and Stochastic Gradient Percent, the logistic regression model gives me the highest accuracy