
Domain yang akan dibahas pada project machine learning (predictive analytics) ini adalah di bidang Kesehatan.
Perubahan gaya hidup dan sosial ekonomi akibat urbanisasi dan modernisasi terutama di masyarakat kota-kota besar di Indonesia menjadi penyebab terjadinya peningkatan prevalensi penyakit degeneratif. Beberapa jenis penyakit yang masuk dalam kelompok penyakit degeneratif seperti Diabetes Mellitus (DM), jantung koroner, hipertensi, hiperlipidemia dan sebagainya.[4]
Diabetes Melitus atau sering juga disebut sebagai penyakit kencing manis merupakan penyakit menahun yang dapat diderita oleh seseorang selama seumur hidup.[3] Diabetes dibagi menjadi 2 tipe, yaitu diabetes melitus tipe 1 dan diabetes melitus tipe 2. Diabetes melitus tipe 1 merupakan diabetes yang ditunjukkan dengan insulin yang dihasilkan oleh tubuh sedikit (dibawah kondisi normal) atau bahkan tidak menghasilkan insulin sama sekali.[2] Hal tersebut dikarenakan sel penghasil insulin telah hancur oleh sistem kekebalan tubuh dan diabetes tipe 1 termasuk pada penyakit autoimun (kondisi ketika sistem kekebalan tubuh seseorang menyerang tubuhnya sendiri). Sedangkan pada diabetes melitus tipe 2, tubuh dapat menghasilkan insulin yang cukup pada awal penyakit, namun tidak meresponnya secara efektif. Sehingga pankreas secara bertahap kehilangan kemampuan untuk memproduksi insulin yang cukup.
Penyakit diabetes berkaitan dengan berbagai faktor, seperti faktor keturunan, pola makan yang buruk, aktivitas fisik yang kurang, dan gaya hidup yang tidak baik (sehingga bisa memicu terjadinya kelebihan berat badan atau obesitas).
Diabetes Mellitus menjadi salah satu penyakit umum yang terjadi di berbagai negara, termasuk di Indonesia. Menurut International Diabetes Federation (IDF) status Indonesia terhadap penyakit Diabetes ini adalah waspada karena Indonesia menepati urutan ke-7 dari 10 negara dengan jumlah pasien Diabetes tertinggi. Tercatat per tahun 2020 jumlah pasien Diabetes Mellitus di Indonesia mencapai 6,2 persen atau setara dengan 10,8 juta jiwa dan akan terus meningkat setiap tahunnya. Pola makan yang tidak teratur, diet ketat yang dijalani beberapa orang, serta mengkonsumsi makanan-makanan yang tidak sehat juga menjadi penyebab timbulnya penyakit Diabetes Mellitus ini.[1]
Diabetes yang tidak terkendali serta tidak diobati dengan benar akan menjadi kronis dan berakibat pada munculnya komplikasi, seperti gagal ginjal, penyakit kardiovaskular, gangguan pada mata, dan juga saraf.[1] Meskipun demikian, penyakit diabetes sebenarnya 80% masih dapat dicegah agar jumlah penderita penyakit ini semakit meningkat tiap tahunnya. Cara pencegahan yang dapat dilakukan yaitu dengan tidak melakukan hal-hal yang dapat meningkatkan risiko diabetes melitus sejak dini, sehingga tidak mempengaruhi tingkat kesehatan di masa tua nanti. Misalnya tidak mengkonsumsi fast food, makan makanan yang mengandung lemat tinggi, dan menerapkan pola hidup sehat seperti makan buah-buahan dan aktif berolahraga.[3]
Berdasarkan urian latar belakang permasalahan yang telah dijabarkan, pada proyek ini dibuat untuk membantu mengidentifikasi individu yang berisiko tinggi menderita diabaetes. Pada proyek ini dilakukan penerapan analisis prediktif (predictive analytics) dengan menganalisis berbagai faktor risiko yang menjadi faktor terjadinya diabetes melitus. Sehingga diharapkan dengan adanya proyek ini dapat membantu memberikan informasi dalam pencegahan diabetes di Indonesia.
Berdasarkan latar belakang permasalahan yang telah diuraikan sebelumnya, maka pada proyek ini dapat diambil rumusan masalah (problem statements) sebagai berikut :
- Bagaimana memprediksi penyakit diabetes melitus dengan menggunakan algoritma machine learning?
- Bagaimana mengembangkan model machine learning yang dapat digunakan untuk memprediksi penyakit diabetes?
- Bagaimana performa atau evaluasi dari model machine learning yang telah dikembangkan untuk memprediksi penyakit diabetes?
Berdasarkan rumusan masalah (problems statement) yang telah dirumuskan sebelumnya, maka berikut adalah tujuan (goals) dari proyek machine learning ini :
- Mengetahui penerapan algoritma machine learning dalam memprediksi penyakit diabetes melitus.
- Mengetahui rangkaian proses pengembangan model machine learning dari awal hingga selesai dalam memprediksi penyakit diabetes melitus.
- Mengetahui performa atau evaluasi dari model machine learning yang telah dikembangkan untuk memprediksi penyakit diabetes.
Berdasarkan problem statements dan goals yang telah disebutkan sebelumnya, maka berikut adalah solution statements pada proyek machine learning ini :
- Melakukan proses pengembangan model machine learning dari awal hingga selesai, meliputi data wrangling, Exploratory Data Analysis (EDA), modelling, dan evaluation.
- Pengembangan model machine learning (modelling) menggunakan algoritma yang sesuai dengan permasalahan, yaitu algoritma klasifikasi untuk memprediksi kelas (diabetes / non-diabetes) dengan menggunakan dataset yang telah ditentukan. Algoritma machine learning yang digunakan pada proyek ini diantaranya yaitu :
- Random Forest Classification : algoritma ensemble (group) learning, yang terdiri dari banyak pohon keputusan (decision tree) yang bekerja bersama untuk meningkatkan kinerja dan akurasi prediksi.
- Hyperparameter Tuning dengan Search Grid : untuk memperoleh konfigurasi yang paling optimal untuk melatih model machine learning.
- Melakukan evaluation model untuk mengetahui performa model dengan menggunakan metriks evaluasi yang sudah ditentukan. Evaluation model dilakukan untuk mengetahui performa dari model yang telah dikembangkan dalam memprediksi penyakit diabetes. Sehingga dapat diketahui model machine learning yang terbaik untuk digunakan dalam memprediksi penyakit diabetes.
Dataset yang digunakan pada proyek machine learning ini adalah Diabetes dataset yang bersumber dari Kaggle. Dataset tersebut berformat csv (comma-separated values) dengan ukuran 23.3 kB. Dataset tersebut terdiri dari 768 data records dengan 9 feature column.
Berikut adalah detail dari features dataset yang digunakan dalam pengembangan model machine learning proyek ini :
| Feature | Description |
|---|---|
| Pregnancies | Number of times pregnant |
| Glucose | Plasma glucose concentration a 2 hours in an oral glucose tolerance test |
| BloodPressure | Diastolic blood pressure (mm Hg) |
| SkinThickness | Triceps skin fold thickness (mm) |
| Insulin | 2-Hour serum insulin (mu U/ml) |
| BMI | Body mass index (weight in kg/(height in m)^2) |
| DiabetesPedigreeFunction | Diabetes pedigree function |
| Age | Age in years |
| Outcome | Class variable (0 or 1) |
- Univariate Analysis

Gambar 1. Pie-Chart Diabetes & Non-Diabetes
Berdasarkan visualisasi grafik *pie-chart* pada gambar 1 di atas menunjukkan bahwa jumlah penderita penyakit diabetes yaitu 268 orang (34,9 %). Sedangkan jumlah orang yang non-diabetes yaitu 500 orang (65,1%) dari total keseluruhan jumlah orang dalam dataset (768 orang).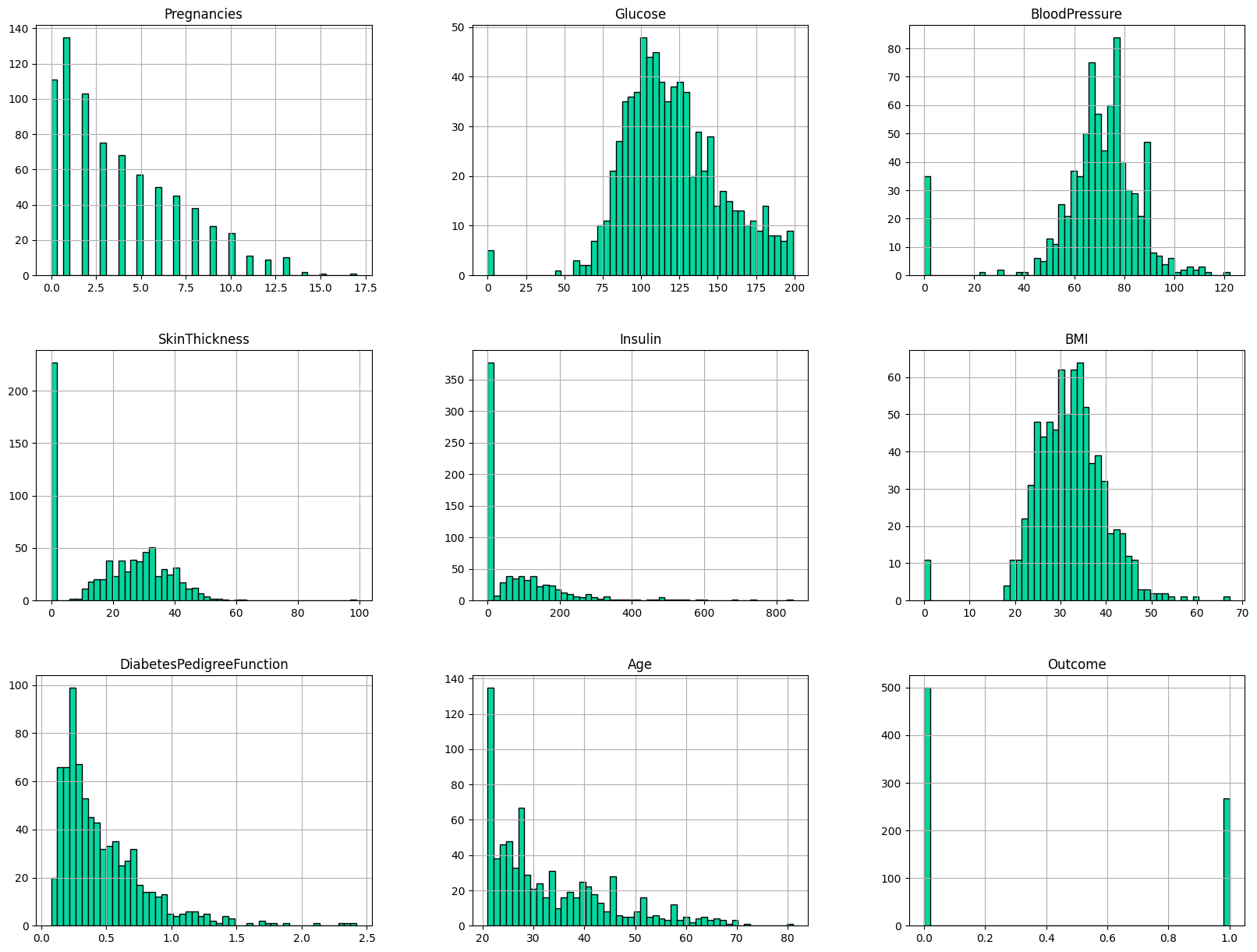
Gambar 2. Visualisasi feature numerik
Berdasarkan visualisasi untuk *feature* numerik pada dataset yang dapat dilihat pada histogram di atas, dapat diketahui beberapa informasi, yaitu : sebagaian besar orang memiliki glukosa dengan tingkat 100-150; sebagian besar orang memiliki *BloodPressure* pada tingkat 60-90; sebagian besar orang memiliki BMI berkisar dari 25-40; sebagian besar orang memiliki *DiabetesPedigreeFunction* berkisar dari 0.0 hingga 0.75; dan sebagian besar orang berumur 20-30 tahun.
- Multivariate Analysis
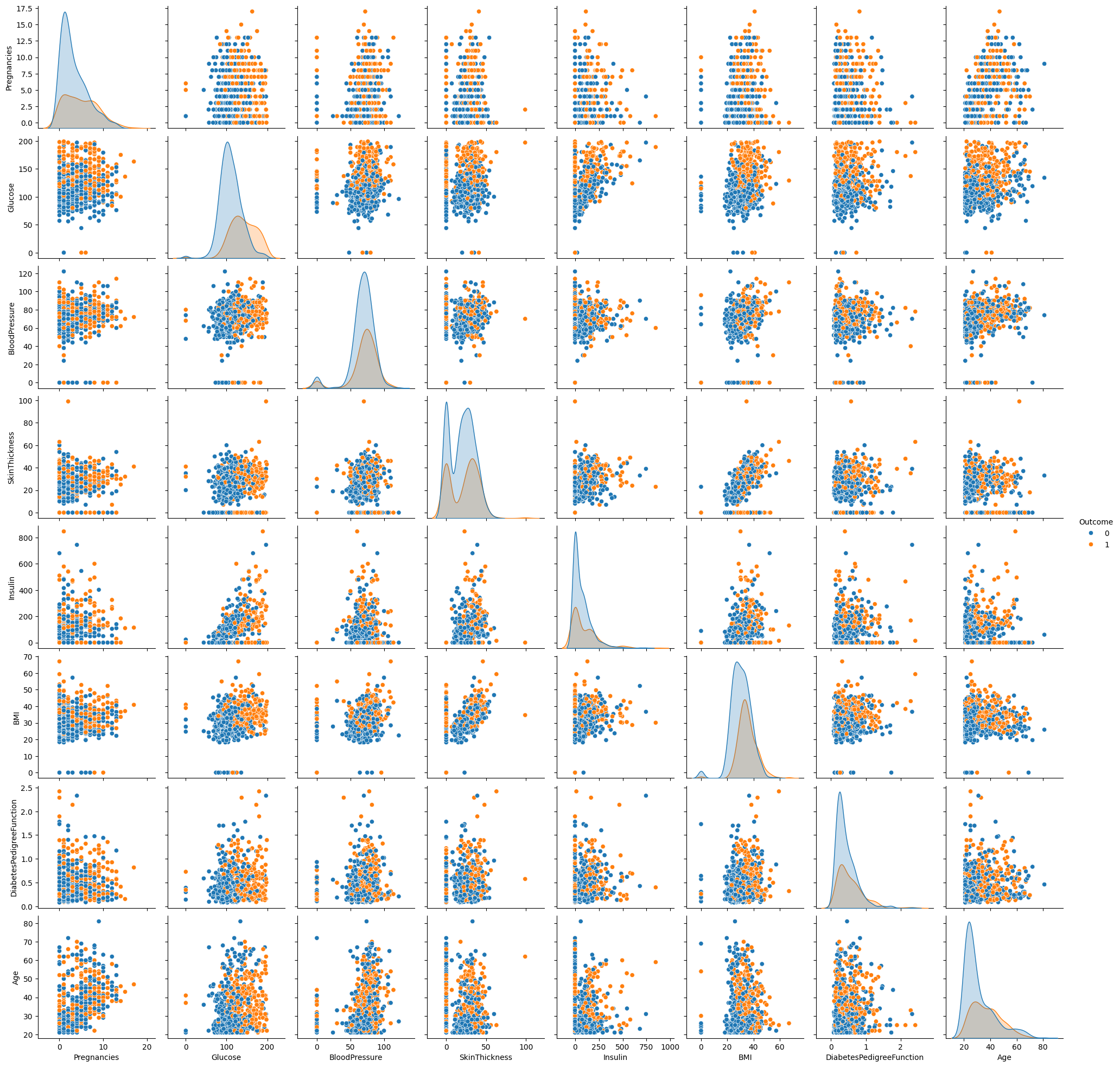
Berdasarkan visualisasi pada gambar 3 di bawah menunjukkan relasi antar feature pada dataset. Apabila diperhatikan korelasi antar feature pada dataset beragam, terdapat korelasi yang lemah (atau tidak ada korelasi sama sekali) dan beberapa feature yang berkorelasi meskipun tidak terlalu kuat.
Gambar 3. Visualisasi multivariate analysis
- Outliers Visualisasi boxplot di atas dilakukan untuk mengidentifikasi apakah terdapat pencilan (outliers) pada dataset yang digunakan pada proyek machine learning. Karena apabila terdapat outliers pada dataset dapat menyebabkan bias atau ketidakakuratan model dalam memprediksi.
Gambar 4. Mengecek outliers

Data preparation adalah proses mempersiapkan data mentah menjadi format yang sesuai untuk analisis atau pemrosesan lebih lanjut. Berikut adalah beberapa teknik atau metode yang digunakan dalam persiapan data pada proyek ini:
-
Handling missing value
- Missing value merupakan salah satu masalah yang paling sering dijumpai dalam proyek analisis data di industri. Masalah ini muncul karena adanya nilai yang hilang dari sebuah data dan biasanya direpresentasikan sebagai nilai NaN dalam library pandas. Hal ini biasanya terjadi karena adanya human error, masalah privasi, proses merging/join, dll.
- Tujuan dari langkah ini adalah untuk memastikan keakuratan dan keandalan data yang digunakan untuk analisis atau pemodelan. Missing value dapat menyebabkan bias dan kesalahan dalam analisis data, sehingga penting untuk mengidentifikasi dan mengatasi nilai yang hilang ini agar hasil analisis menjadi lebih akurat dan dapat diandalkan.
- Terdapat beberapa cara atau metode yang dapat digunakan untuk menangani missing value, yaitu Dropping, Imputation, Interpolation, dan lainnya.
-
Handling duplicated data
- Duplicated data adalah masalah lain yang umum dijumpai di industri. Ia terjadi ketika terdapat sebuah observasi (semua nilai dalam satu unit baris) yang memiliki nilai yang sama persis pada setiap kolomnya.
- Tujuan dari langkah ini adalah untuk memastikan integritas data. Duplicated data dapat mempengaruhi analisis data dan membuat hasil yang tidak akurat. Oleh karena itu, dengan mengidentifikasi dan menghapus data yang terduplikat, dapat memastikan bahwa data yang digunakan untuk analisis atau pemodelan adalah data yang valid dan representatif.
- Salah satu teknik yang dapat digunakan dalam mengatasi duplicated data adalah dengan menghapus data yang terduplikat (dropping).
-
Handling outliers
- Outliers adalah nilai yang jauh berbeda dari nilai lainnya dalam kumpulan data. Nilai ini muncul sebagai pengecualian dalam pola data yang ada. Nilai yang ada di outlier bisa jauh lebih tinggi maupun lebih rendah dibandingkan dengan nilai-nilai lain dalam dataset. Outlier bisa terjadi karena berbagai alasan, termasuk kesalahan pengukuran, kejadian langka, atau karena faktor lain yang tidak terduga.
- Tujuan dari langkah ini adalah untuk memastikan bahwa outlier tidak mempengaruhi analisis statistik yang dilakukan atau model machine learning yang dibangun. Outliers memiliki potensi untuk memberikan informasi yang salah atau mengganggu hasil analisis, sehingga penting untuk mengatasi mereka agar hasil analisis menjadi lebih akurat dan dapat dipercaya.
- Terdapat beberapa cara atau langkah yang dapat diterapkan dalam menangani outliers, yaitu meliputi identifikasi outliers, transformasi data, menghapus outliers, dan imputation. Pada proyek ini penanganan outliers dilakukan dengan menggunakan metode imputation, dengan menggunakan IQR method. Hasil dari metode imputation pada proyek ini dapat dilihat pada gambar 5 berikut :
Gambar 5. Handling outliers

-
Standardization
- Standardisasi adalah proses mengubah data sehingga memiliki rata-rata (mean) nol dan varians (variance) satu.
- Tujuan dari standardisasi adalah untuk membuat distribusi data lebih terpusat di sekitar nilai nol dengan variabilitas yang seragam, yang dapat membantu algoritma machine learning memahami dan memproses data dengan lebih baik.
- Teknik yang digunakan adalah dengan mengurangi nilai setiap fitur dengan rerata dari fitur tersebut, dan kemudian membaginya dengan standar deviasi dari fitur tersebut. Dalam kasus ini, StandardScaler scikit-learn digunakan untuk menstandarisasi skor z.
-
Handling imbalanced data
- Imbalanced data merupakan sebuah kondisi di mana distribusi dari kelas yang terdapat pada dataset tidak seimbang jumlahnya.
- Tujuan dari menangani imbalanced data adalah untuk meningkatkan performa model dalam memprediksi kelas minoritas.
- Terdapat beberapa cara atau metode yang dapat digunakan untuk menangani imbalanced data. Pertama, oversampling yaitu memperbanyak sampel dari kelas minoritas sehingga jumlahnya seimbang dengan kelas mayoritas. Ini dapat dilakukan dengan menggandakan sampel yang ada atau dengan membuat sampel sintetis baru. Cara lainnya, undersampling yaitu mengurangi jumlah sampel dari kelas mayoritas sehingga jumlahnya seimbang dengan kelas minoritas. Ini dapat dilakukan dengan menghapus sebagian sampel dari kelas mayoritas. Pada proyek ini penanganan imbalanced data dilakukan dengan metode SMOTE (Synthetic Minority Over-sampling Technique): SMOTE digunakan untuk membuat sampel sintetis dari kelas minoritas (dalam hal ini, kelas "1" dari kolom 'Outcome') sehingga jumlahnya seimbang dengan kelas mayoritas. Hal ini membantu mencegah bias pada model machine learning ke kelas mayoritas dan meningkatkan kinerja model untuk kelas minoritas.
Gambar 6. Imbalanced data

- Data Splitting
- Data Splitting adalah proses membagi dataset menjadi dua atau lebih bagian yang berbeda untuk digunakan dalam tahapan tertentu dari proses analisis data, seperti pelatihan model, validasi model, dan pengujian model.
- Tujuan dari langkah ini adalah pembagian data menjadi menjadi dua bagian: satu untuk melatih model (set pelatihan) dan yang lainnya untuk menguji model (set pengujian).
- Teknik yang digunakan adalah dengan menggunakan metode Train-test split.
Pada proyek ini algoritma machine learning yang digunakan di antaranya yaitu Random forest classification dan Hyperparameter Tuning Grid Search.
Random Forest Classification termasuk algoritma supervised learning yang dapat digunakan untuk permasalahan classification. Random forest termasuk dalam salah satu kategori ensemble (group) learning, yang terdiri dari banyak pohon keputusan (decision tree) yang bekerja bersama untuk meningkatkan kinerja dan akurasi prediksi. Pada model machine learning ensemble, setiap model harus membuat prediksi secara independen. Kemudian, prediksi dari setiap model ensemble ini digabungkan untuk membuat prediksi akhir. Algoritma Random Forest mengkombinasikan hasil prediksi dari berbagai model decision tree yang dibuat secara acak.

Kelebihan :
- Random forest merupakan algoritma yang sering digunakan karena cukup sederhana tetapi memiliki stabilitas yang mumpuni.
- Random forest dapat mencegah terjadinya overfitting apabila dibandingkan dengan algoritma Decision Tree. Selain itu, algoritma ini dapat menangani dataset besar dengan banyak fitur.
Kekurangan :
- Random Forest memerlukan waktu pelatihan yang lebih lama dibanding Decision Tree karena kompleksitas modelnya
Proses modelling menggunakan algoritma Random Forest pada proyek ini (permasalahan klasifikasi) menggunakan RandomForestClassifier() yang telah disediakan oleh scikit learn. Pada proyek ini parameter yang digunakan yaitu n_estimators=50, max_depth=5, dan max_features='auto. n_estimators adalah hyperparameter yang menentukan jumlah pohon (trees) yang digunakan dalam random forest, pada proyek ini n_estimators yang digunakan yaitu 50. Parameter selanjutnya adalah max_depth, yang merupakan kedalaman atau panjang pohon. Parameter ini merupakan ukuran seberapa banyak pohon dapat membelah (splitting) untuk membagi setiap node ke dalam jumlah pengamatan yang diinginkan. Pada proyeki ini max_depth yang digunakan adalah 5. Parameter selanjutnya adalah max_features, yaitu hyperparameter yang mengatur jumlah maksimum feature yang digunakan untuk mencari percabangan terbaik. Pada proyek ini, max_features yang digunakan adalah auto.
Hyperparameters digunakan untuk meng-custom model dan mengontrol proses training sesuai dengan dataset atau permasalahan yang ingin diselesaikan. Sementara hyperparameter tuning dilakukan dengan tujuan untuk memperoleh konfigurasi yang paling optimal untuk melatih model machine learning. Pada praktiknya, proses hyperparameter tuning ini dapat dijalankan secara manual dengan mencoba berbagai konfigurasi hyperparameter yang ada hingga diperoleh konfigurasi yang paling optimal. Cara lainnya yaitu dengan melakukan hyperparameter tuning secara otomatis dengan bantuan beberapa algoritma salah satunya adalah grid search.
Grid search merupakan algoritma yang dapat digunakan untuk melakukan proses hyperparameter tuning secara otomatis. Pada prosesnya, algoritma ini akan membuat sebuah n-dimensional search space yang terbentuk dari n hyperparameter dari sebuah model. Setiap titik yang terdapat pada search space mewakili satu konfigurasi atau perpaduan dari n hyperparameter. Algoritma ini bekerja dengan mengevaluasi setiap titik yang terdapat dalam search space untuk memperoleh konfigurasi hyperparameter yang paling optimal.
Pada proyek ini akan dilakukan Hyperparameter Tuning dengan Grid Search untuk meningkatkan performa dari model Random Forest yang telah dikembangkan sebelumnya. Parameter yang digunakan pada Hyperparamter Tuning adalah sebagai berikut :
- random_state: digunakan untuk mengontrol random number generator yang digunakan oleh model.
- max_depth: hyperparameter yang mengatur kedalaman atau panjang pohon keputusan.
- max_features: hyperparameter yang mengatur jumlah maksimum feature yang digunakan untuk mencari percabangan terbaik.
- criterion: metrik yang digunakan untuk mengukur kualitas dari sebuah percabangan.
- n_estimators: hyperparameter yang menentukan jumlah trees (pohon) yang digunakan dalam algoritma random forest.
Berdasarkan Hyperparameters Tuning dengan Grid Search yang telah dilakukan, maka dapat diketahui best parameter yang dapat digunakan pada model Random Forest untuk meningkatkan performa model. Paramter yang digunakan tersebut di antaranya criterion : gini; max_depth : 8; max_features : auto; dan n_estimators : 50.
Berdasarkan eksperimen yang telah dilakukan pada tahapan pengembangan model, diperoleh model machine learning terbaik yaitu Random Forest Classification dengan Hyperparameter Tuning Grid Search. Hal ini berdasarkan hasil dari confussion matrix dan classification report yang menunjukkan bahwa hasil dari model ini lebih baik dari hasil model Random Forest Classification yang tidak menerapkan hyperparameter tuning. Sehingga hasil dari model machine learing yang dikembangkan telah memenuhi tujuan dari solution statements yang telah ditentukan sebelumnya.
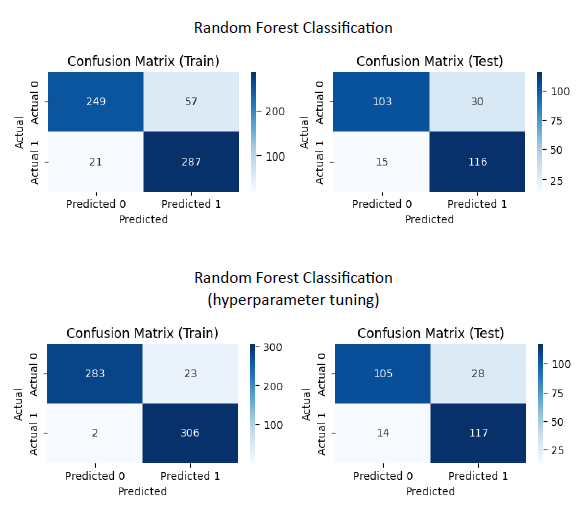
Pada proyek machine learning ini evaluasi model akan menggunakan confussion matrix. Confussion matrix memberi gambaran bagaimana performa model pada berbagai kelas. Ia menunjukkan berapa banyak jumlah prediksi yang benar (True) dan salah (False) untuk setiap label.
Dengan menggunakan confussion matrix, maka dapat diketahui seberapa baik performa dari model machine learning yang dikembangkan. Hasil dari confussion matrix ini akan digunakan untuk menghitung berbagai metrik lainnya, seperti accuracy, precision, recall, dan F-1 score.
- Accuracy — metrik evaluasi yang mengukur seberapa baik model membuat prediksi yang benar dari total prediksi yang dilakukan.
- Precision — metrik evaluasi yang digunakan untuk mengukur berapa banyak model menghasilkan prediksi yang benar untuk suatu kelas tertentu. Precision didefinisikan sebagai perbandingan antara jumlah hasil prediksi yang benar untuk kelas tertentu dengan jumlah total prediksi untuk kelas tersebut.
- Recall — metrik yang digunakan untuk mengukur seberapa baik model dalam memprediksi suatu kelas tertentu. Recall didefinisikan sebagai perbandingan antara jumlah hasil prediksi yang benar untuk kelas tertentu dengan jumlah total sampel pada kelas tersebut.
- F1-score — merupakan kombinasi antara nilai precision dan recall dari suatu kelas tertentu.
Berdasarkan dengan konteks data, problem statement, dan solusi yang diimplementasikan, metrik evaluasi yang akan digunakan pada proyek machine learning ini adalah Recall. Recall adalah metrik yang digunakan untuk mengukur seberapa baik model dalam memprediksi suatu kelas tertentu. Recall dipilih dengan alasan bahwa algoritma machine learning / model memprediksi seseorang mengalami diabetes tetapi sebenarnya non-diabetes, daripada model salah memprediksi bahwa seseorang non-diabetes padahal sebenarnya dia adalah penderita diabetes.
Tabel 1. Classification Report (train dataset)
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.99 | 0.92 | 0.96 | 306 |
| 1 | 0.93 | 0.99 | 0.96 | 308 |
| accuracy | 0.96 | 614 | ||
| macro avg | 0.96 | 0.96 | 0.96 | 614 |
| weight avg | 0.96 | 0.96 | 0.96 | 614 |
Tabel 2. Classification Report (test dataset)
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.88 | 0.79 | 0.83 | 133 |
| 1 | 0.81 | 0.89 | 0.85 | 131 |
| accuracy | 0.84 | 264 | ||
| macro avg | 0.84 | 0.84 | 0.84 | 264 |
| weight avg | 0.84 | 0.84 | 0.84 | 264 |
Berdasarkan tahapan evaluasi pada proyek machine learning ini, model terbaik yang dikembangkan adalah model Random Forest Classification dengan Hyperparameter Tuning Grid Search, dengan Recall yang diperoleh yaitu 0.96 (train dataset) dan 0.84 (test dataset). Model machine learning yang dikembangkan dengan metode hyperparameter ini dinilai mampu menjawab problem statements dan mencapai goals dari proyek yang sudah ditentukan sebelumnya. Sehingga diharapkan dengan adanya model machine learning ini dapat membantu memprediksi seseorang yang menderita diabetes.
[1] Y. Yusransyah, S. N. Stiani, and A. N. Sabilla, “Hubungan Antara Kepatuhan Minum Obat Pasien Diabetes Mellitus dan Support yang Diberikan Keluarga,” J. Ilm. Kesehat. Delima, vol. 4, no. 2, pp. 74–77, 2022, doi: 10.60010/jikd.v4i2.79
[2] F. Nuraisyah, “Faktor Risiko Diabetes Mellitus Tipe 2,” J. Kebidanan dan Keperawatan Aisyiyah, vol. 13, no. 2, pp. 120–127, 2018, doi: 10.31101/jkk.395
[3] Lestari, Zulkarnain, and S. A. Sijid, “Diabetes Melitus: Review Etiologi, Patofisiologi, Gejala, Penyebab, Cara Pemeriksaan, Cara Pengobatan dan Cara Pencegahan,” UIN Alauddin Makassar, no. November, pp. 237–241, 2021.
[4] M. Rejeki, “Analisis Komparatif Penyembuhan Penyakit Diabetes Melitus dengan Kombinasi Penggunaan Obat Herbal dan Konsumsi Nutrisi yang Tepat,” Proceeding of The URECOL, pp. 353–360, 2019.
If you have any feedback, please reach out at syarifulm007@gmail.com