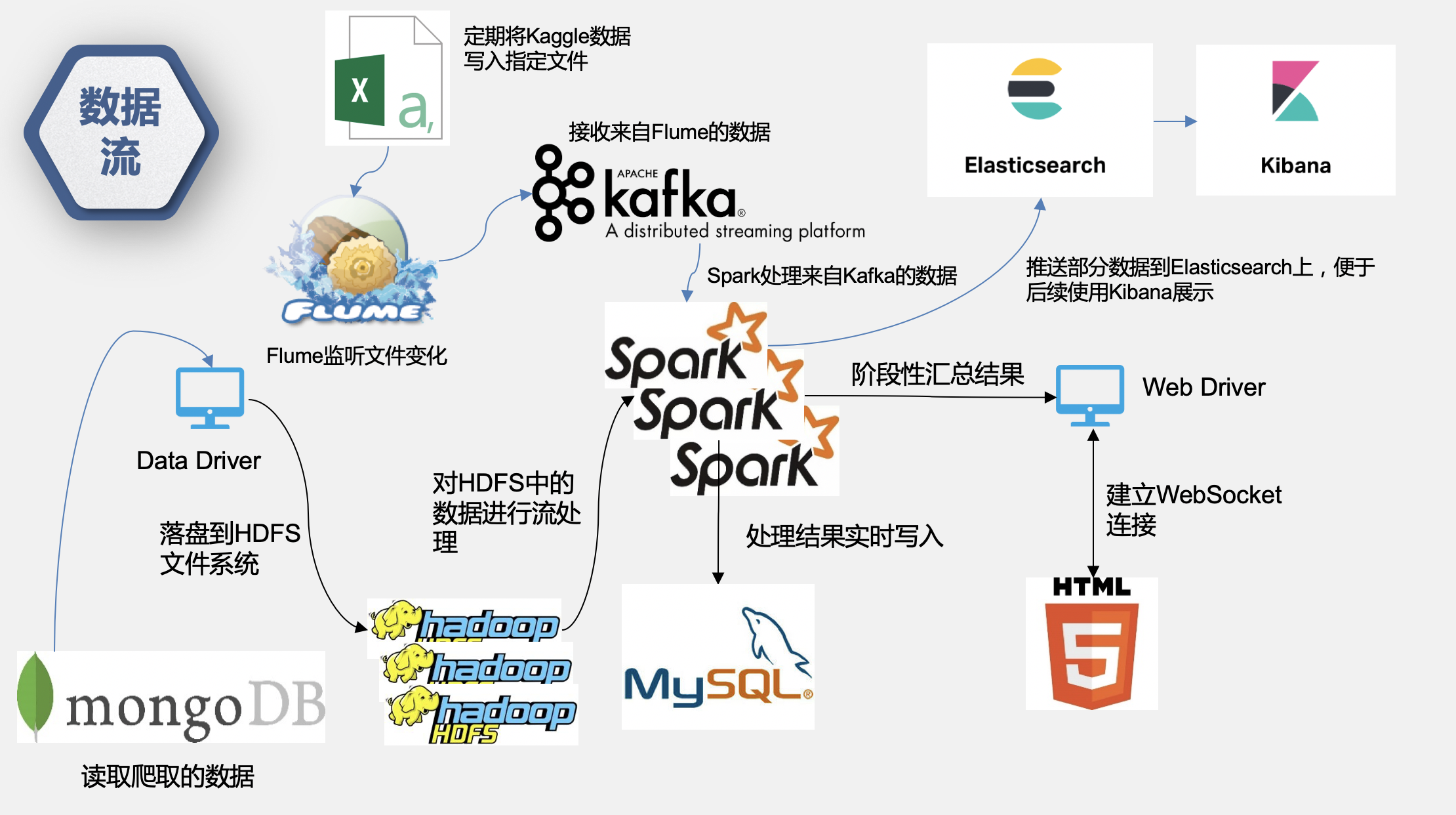
- 本人只负责逻辑层面的业务处理,所以代码大部分只负责到处理数据后落地,前端展示基本使用ECharts
- 详细流程参考PPT文件下三次汇报PPT
- 单机业务流程就可以跑通,集群搭建步骤请参考:集群搭建
- 实践作业分为三个部分:Spark Streaming 计算模拟、Spark GraphX 计算和基于 Spark MLlib 的计算
- Spark Streaming
- 要求针对DStream数据开展的计算中至少使用到5个Transformation操作,可以 是多个业务问题;必须使用到至少1个全局统计的量;结果展示不少于2类图示。Streaming 程序监听的必须是HDFS文件夹。原始数据存储在MongoDB中,模拟数据流时,从MongoDB 中读取数据,写入HDFS中
- Spark GraphX
- 要求必须使用边和点的RDD构造图;用于业务计算的图中不少于1 万个点和1万条边;对于图的计算使用不少于6个GraphX的API调用,可以是解决多个业务问题; 至少使用1次聚合操作或者关联操作;结果展示不少于2类图示。从MongoDB中读取图数据,结果存回 MongoDB中
- Spark MLlib
- 展示不仅包括实验结果,还需包括数据的相关分析
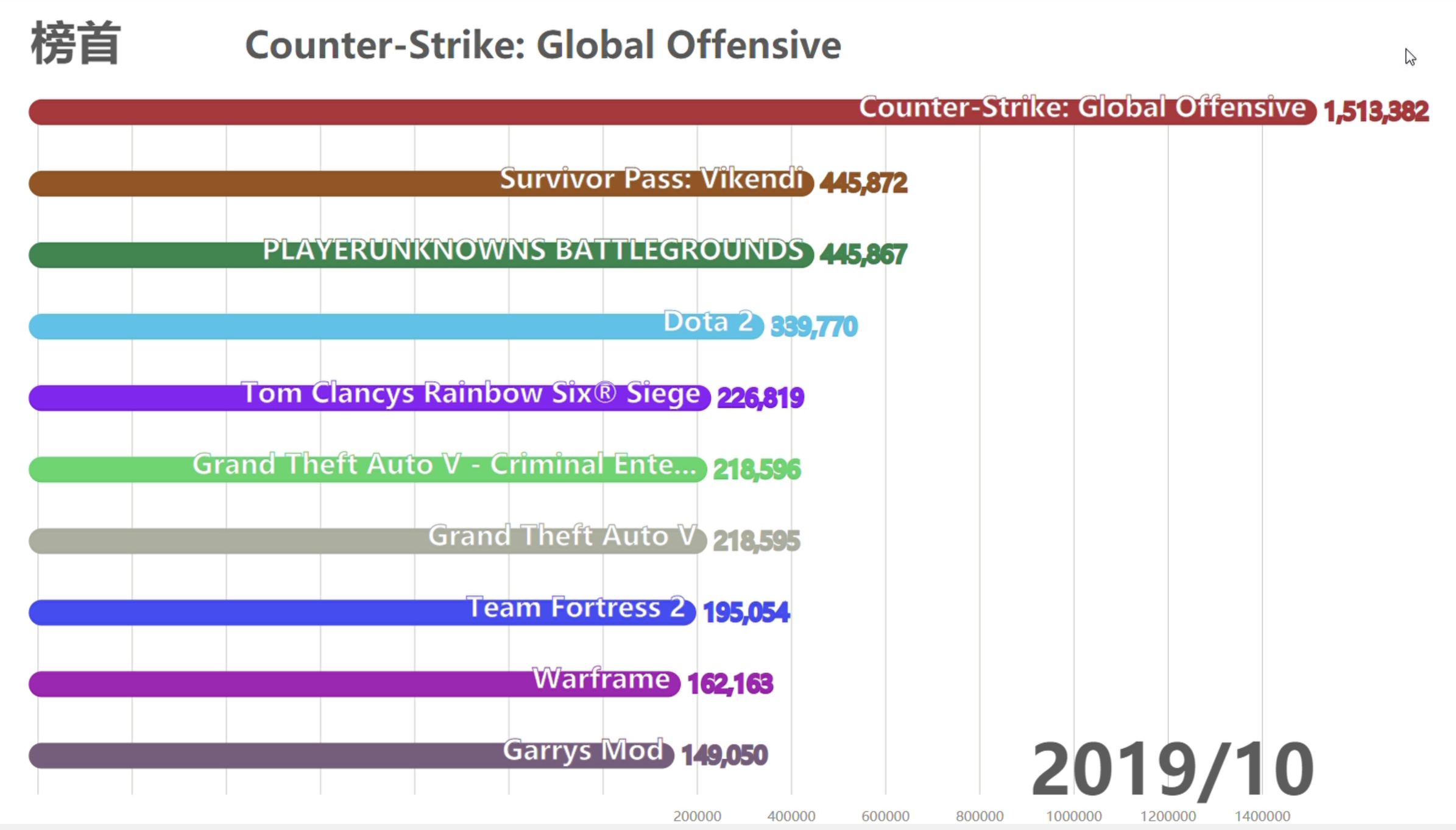
- 截至目前那些游戏最火爆
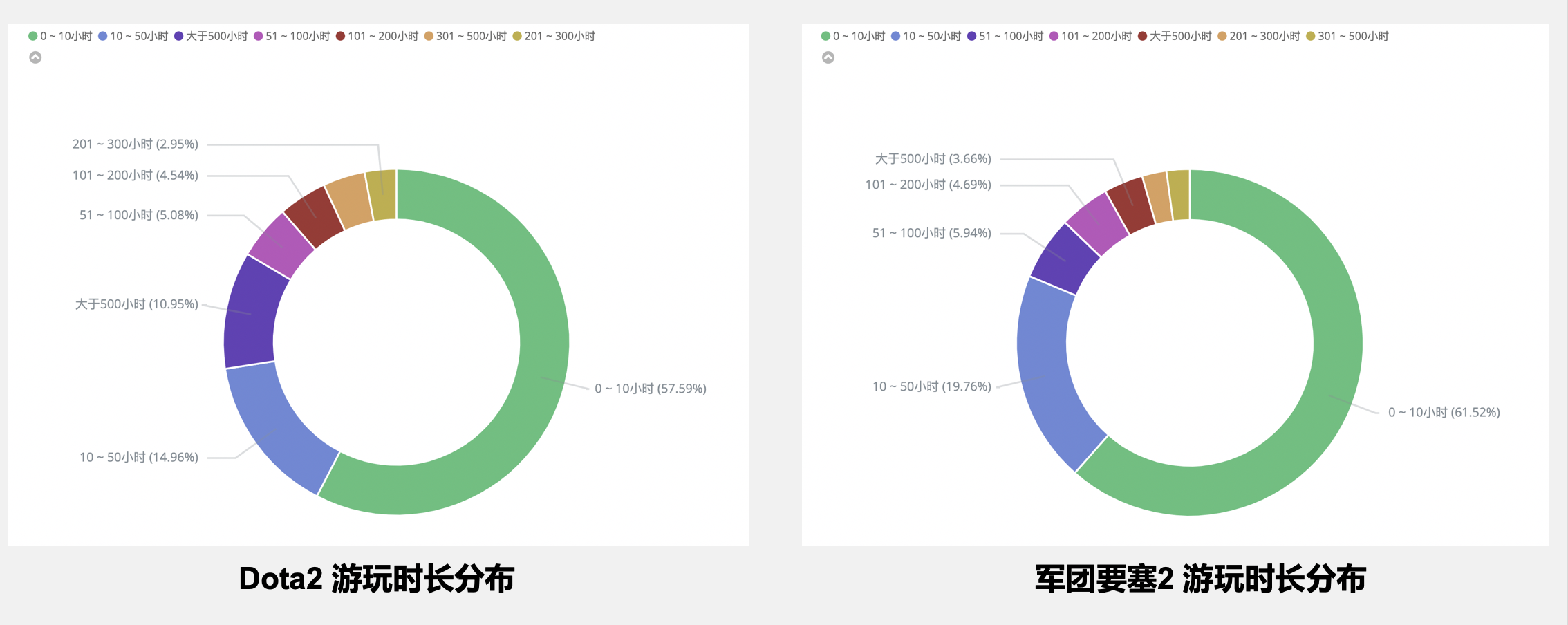
- 玩家游戏时长的分布
- 哪些类型的游戏最受欢迎
- /data/China.games.json

-
/data/steam.csv
userId,gameName,behavior,duration,none 151603712,"The Elder Scrolls V Skyrim",purchase,1.0,0 151603712,"The Elder Scrolls V Skyrim",play,273.0,0 151603712,"Fallout 4",purchase,1.0,0 151603712,"Fallout 4",play,87.0,0 151603712,"Spore",purchase,1.0,0 151603712,"Spore",play,14.9,0 151603712,"Fallout New Vegas",purchase,1.0,0 151603712,"Fallout New Vegas",play,12.1,0 151603712,"Left 4 Dead 2",purchase,1.0,0 151603712,"Left 4 Dead 2",play,8.9,0
- 游戏销量动态排名图
- 动态词云图

- 游玩时长分布图
- 游戏的口碑和热度
- 用户社群
- 游戏对市场的占有力和用户粘性
- 游戏间的竞争关系
相关指标
- 游戏评论
- 玩家评论游戏数
- 游戏所受评论数
- 玩家游戏时长
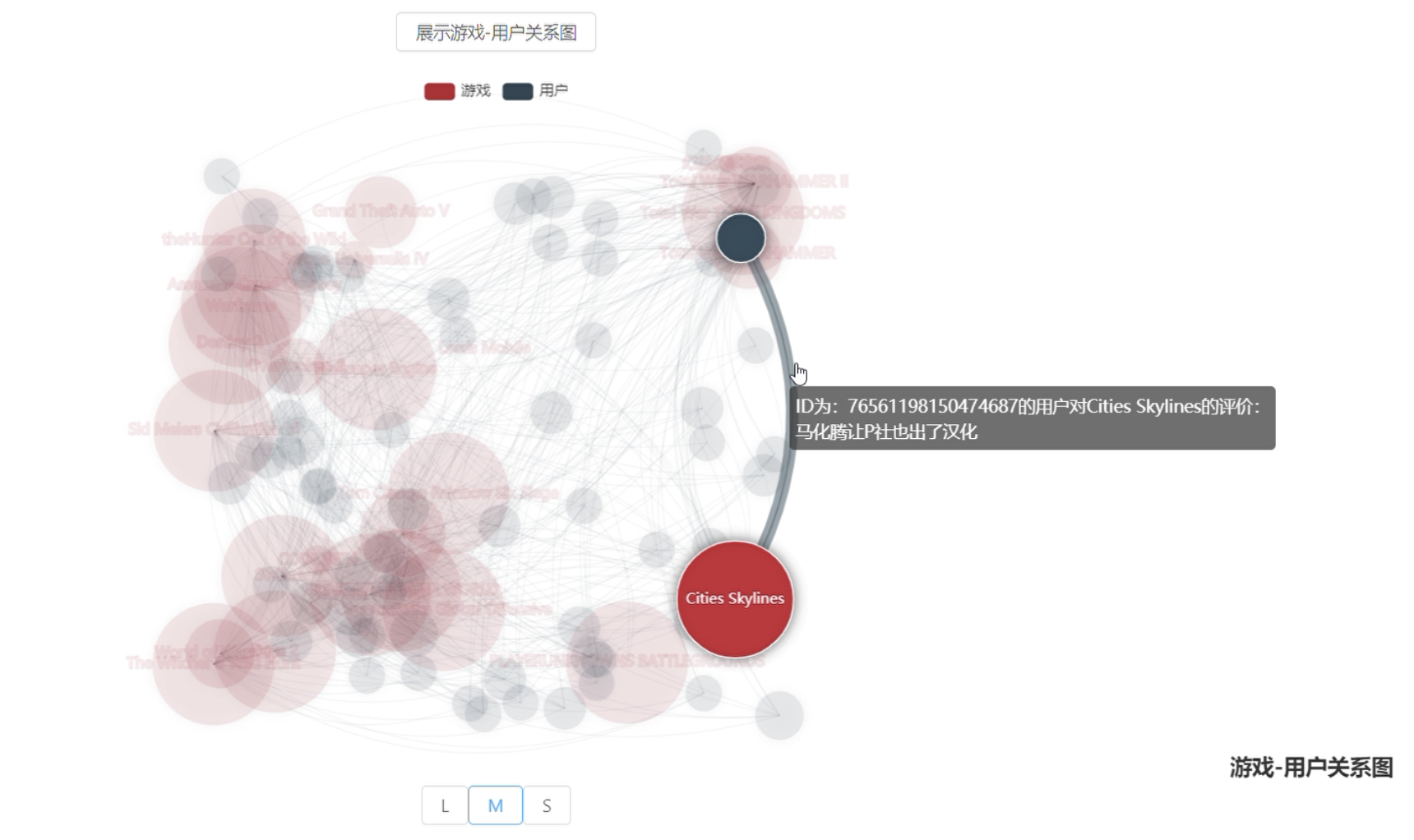
- 游戏用户关系图
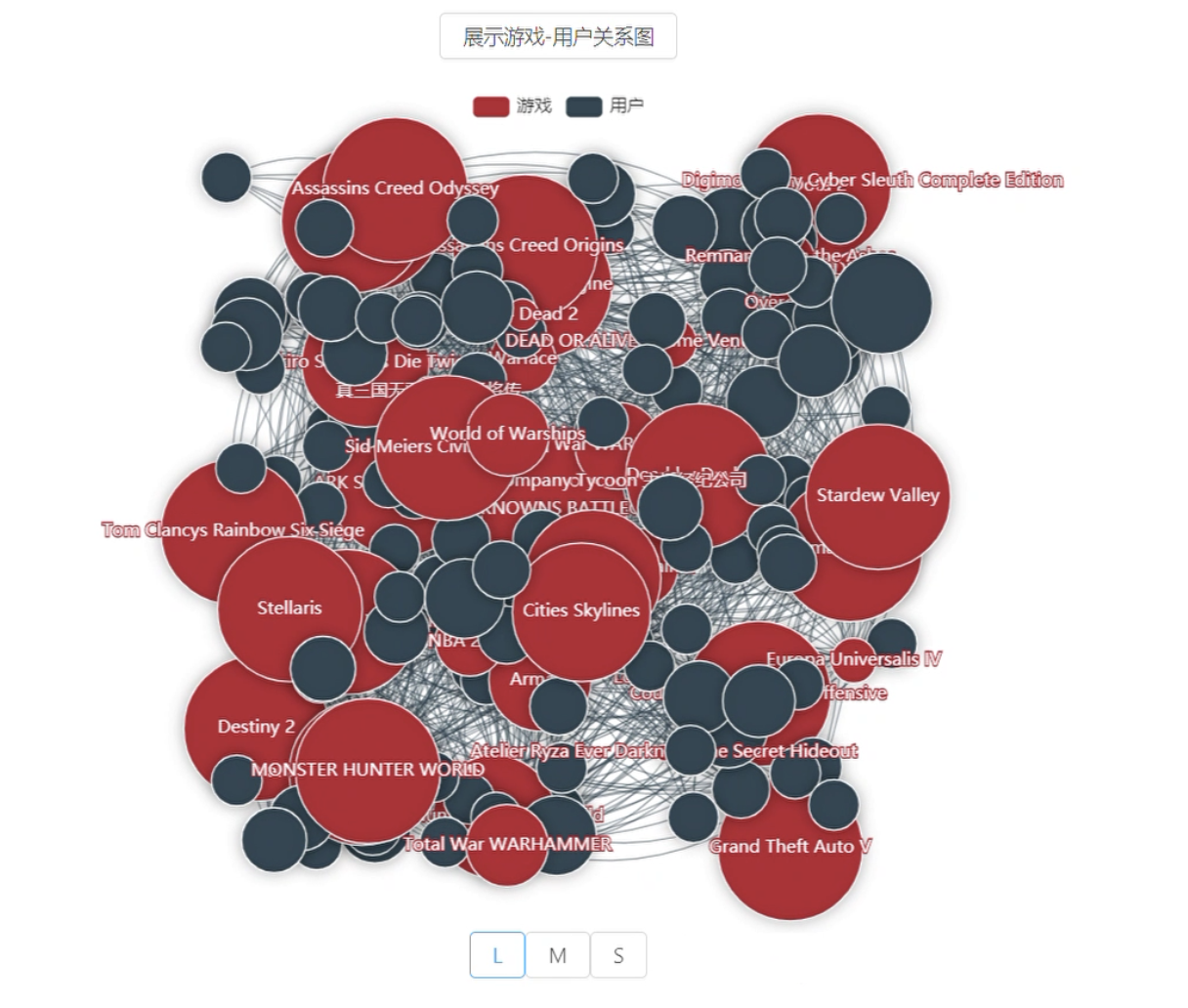
- 用户社群聚合图
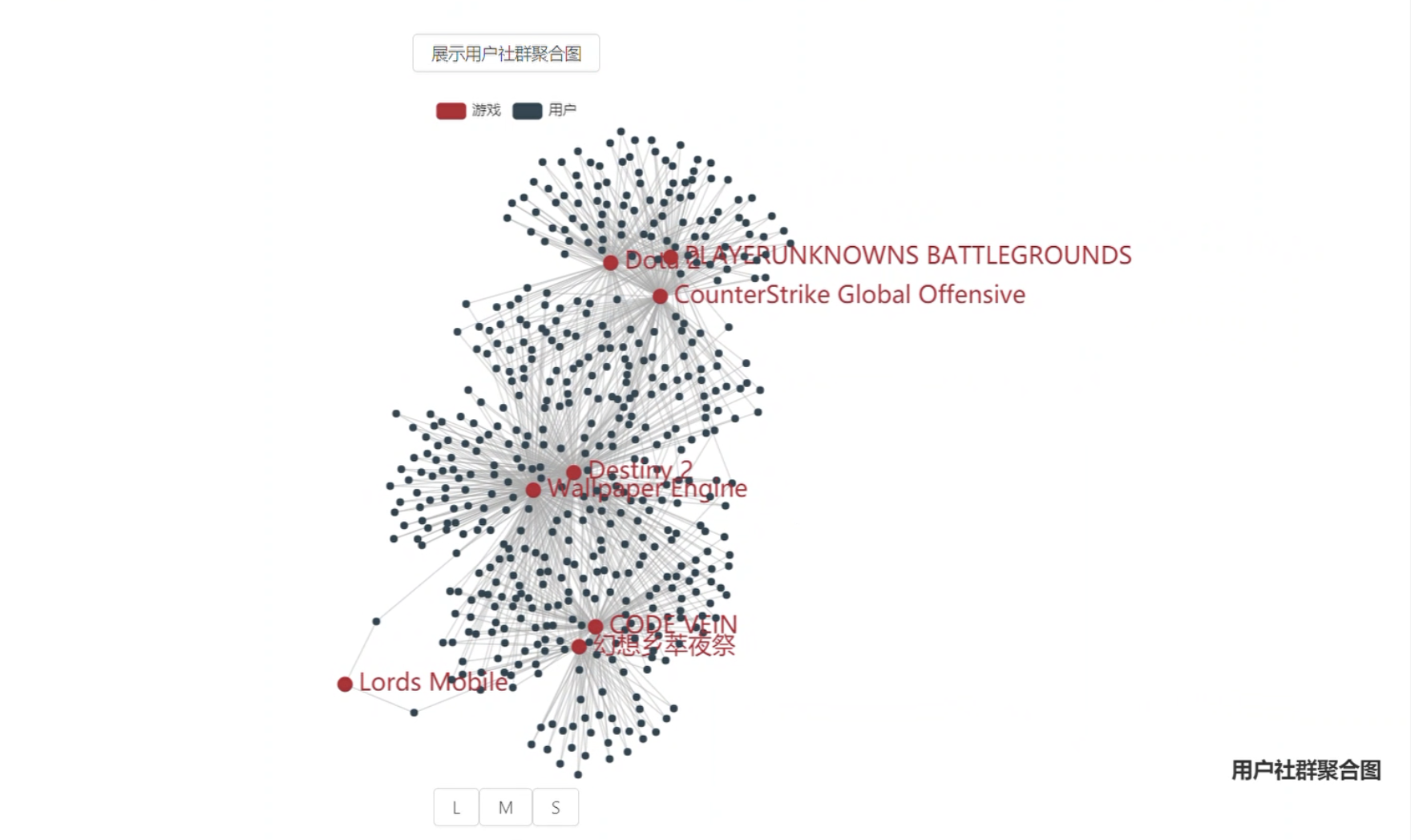
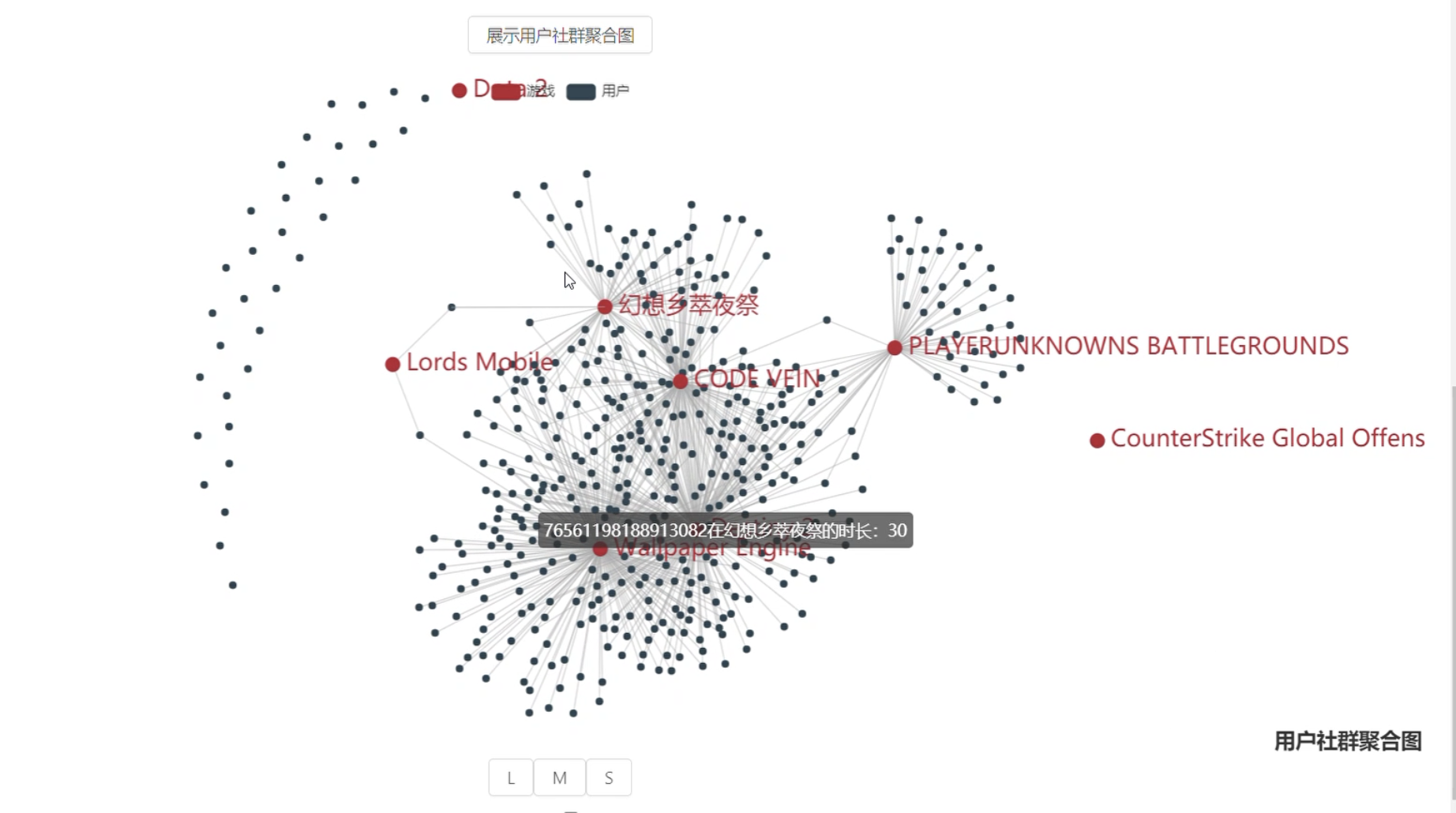
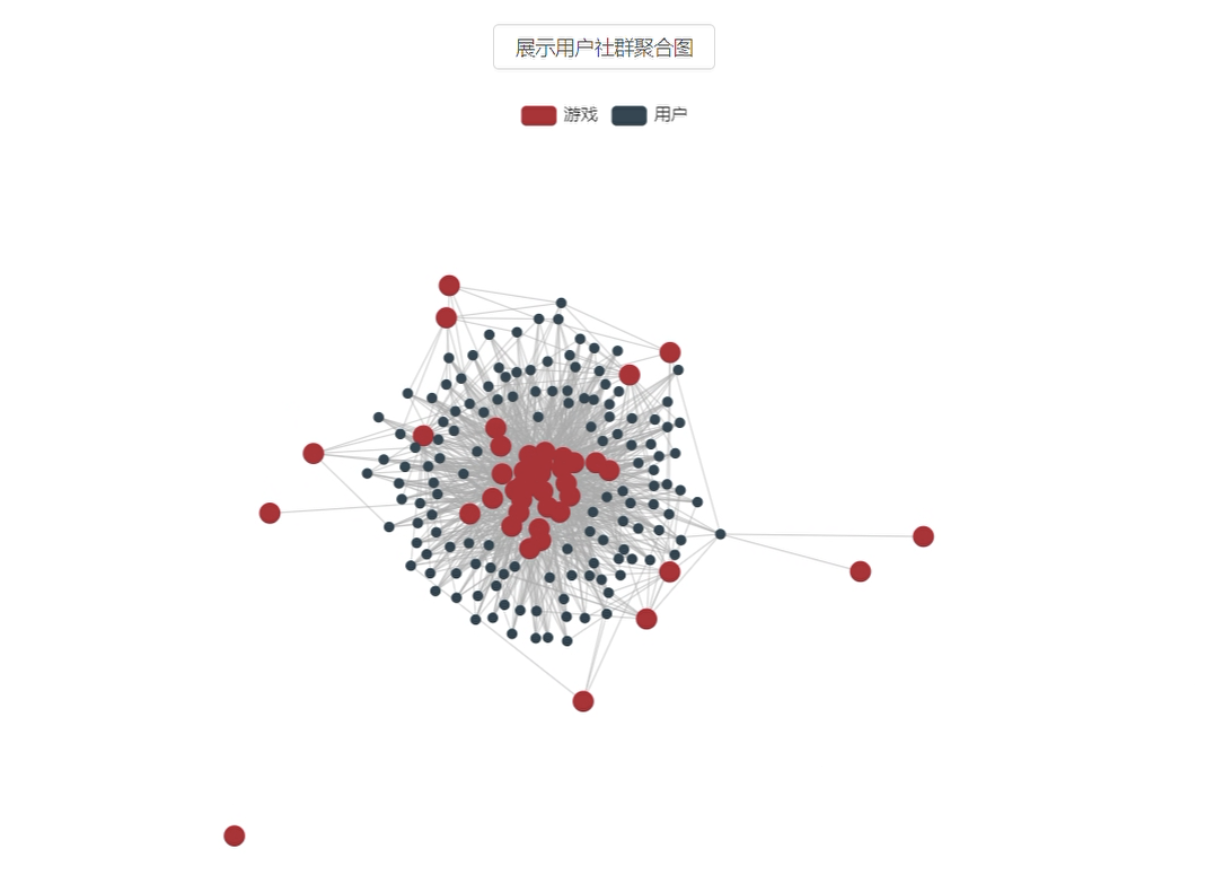
- 玩家间有哪些社群?
- 各社群特点?
- 可能感兴趣的游戏?
- 我们想利用某个兴趣相投、拥有共同经验群体的喜好来推荐感兴趣的游戏给玩家
- 协同过滤技术旨在补充用户 - 商品关联矩阵中所缺失的部分
- 我们并没有直观的用户对游戏的评分,于是用户的游玩时长代替用户对游戏的评价,为了消除游戏本身游玩时长的影响,我们将每款游戏的游玩时长映射到0 – 10之间代替用户对该游戏的评分

- 用户对游戏的评论通常有一个标签:推荐/不推荐
- 我们想通过对评论的情感分析,判断一条评论是推荐这个游戏还是不推荐

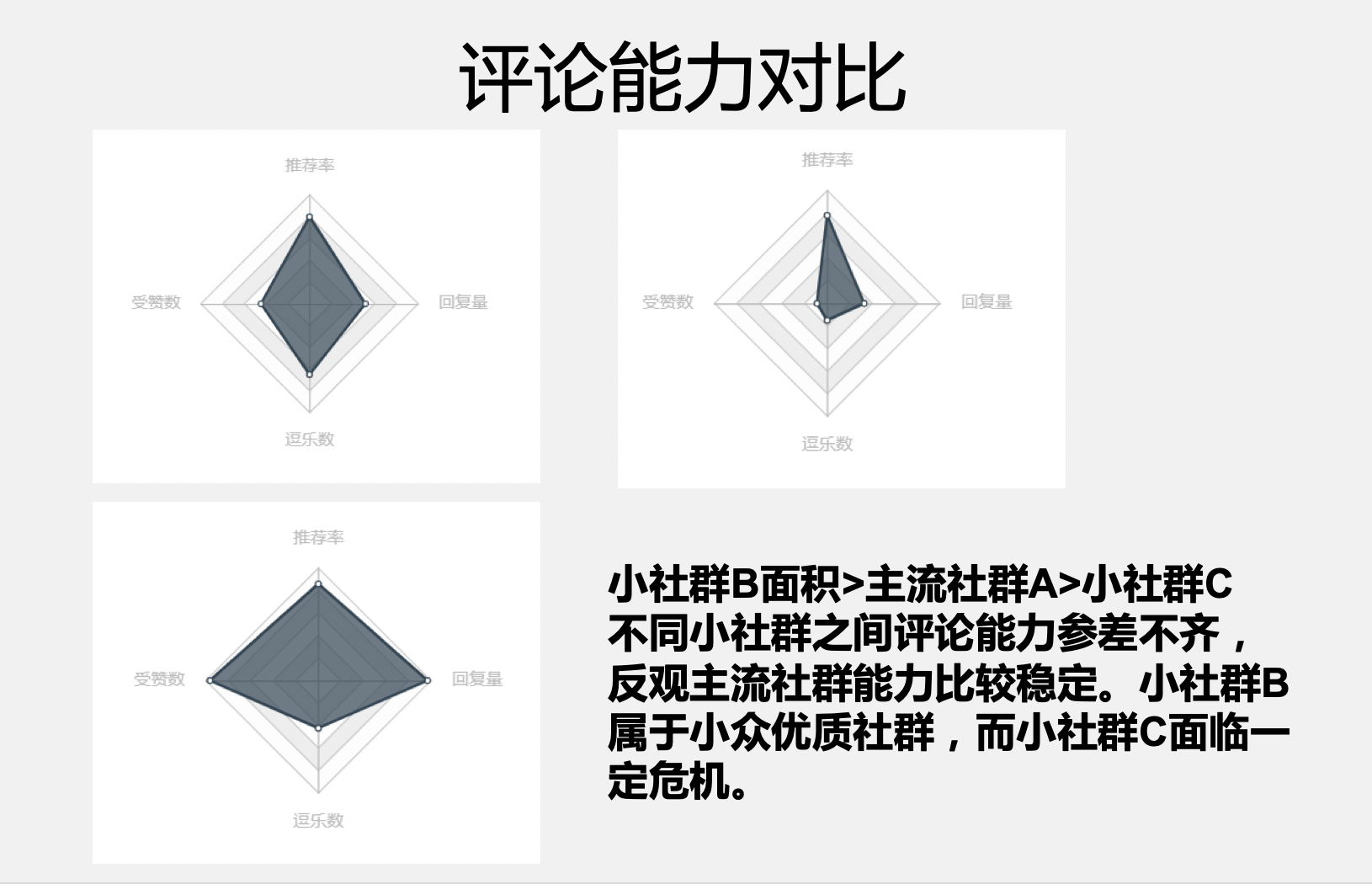
- 聚类特征
- 玩家拥有游戏数
- 玩家总评论数
- 游玩时长
- 是否推荐游戏
- 被认为评论有用
- 被认为评论欢乐数
- 被回复数

- 由于本人只负责Spark计算的过程,所以每部分代码可能都不是完整的业务流程,主要记录学习Spark过程