June 2020
tl;dr: Self supervised estimation of depth and 3D scene flow (and as a side product, 2D optical flow).
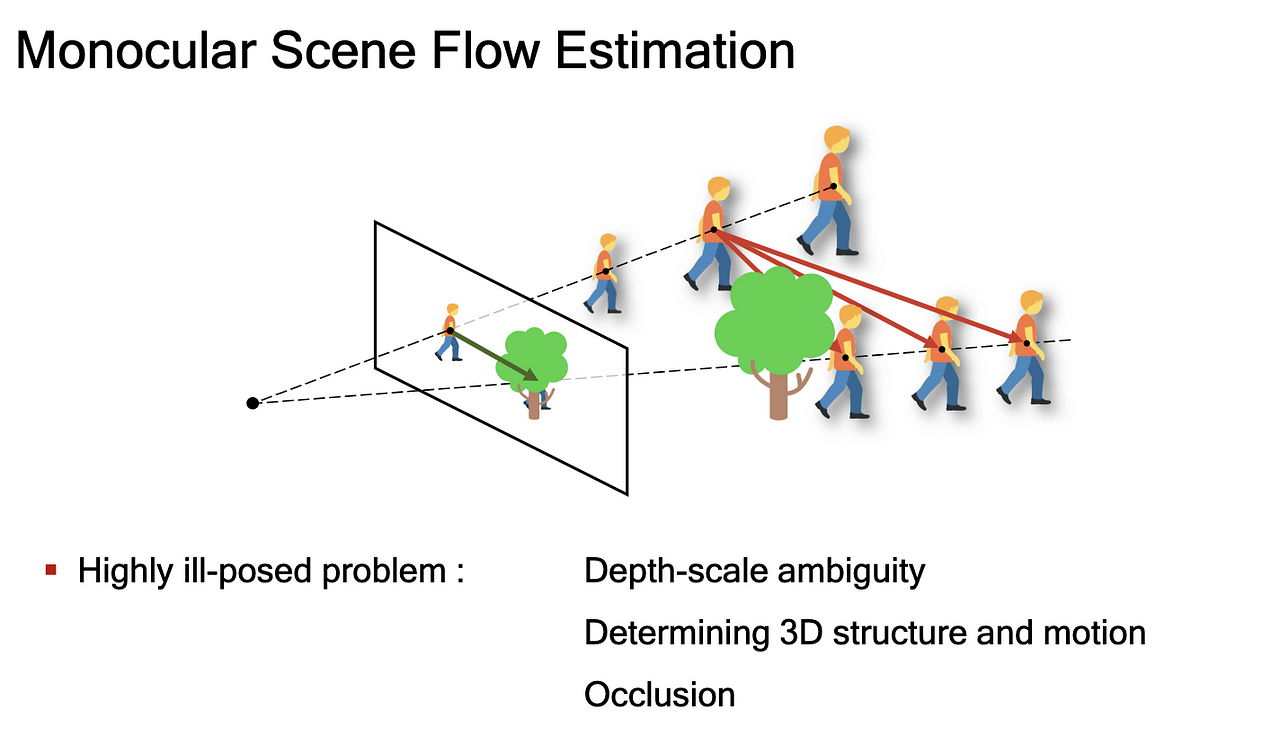
Scene flow estimation is the 3D version of optical flow. It requires depth estimation as well. It is a natural idea to extend the monocular prediction of optical flow and depth to scene flow.
Optical flow is the 2D projection of a 3D point and its 3D scene flow. The scene flow is defined as 3D motion wrt the camera.
The architecture is heavily based on PWC Net for optical flow estimation.
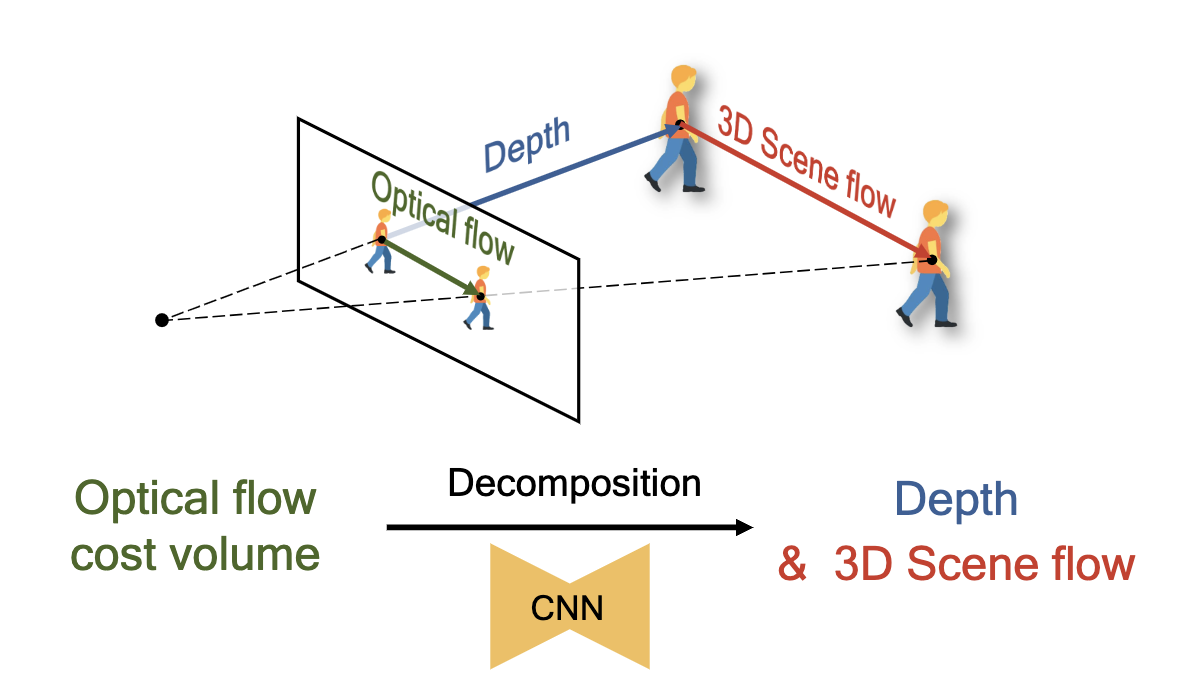
- The main idea is the introduction of the 3D point loss, which penalizes the inconsistency between depth and scene flow estimation.
- Data augmentation with cam conv is better for depth prediction, but does not help with the performance degradation after data aug.
- Change output channel from 2D in PWC Net (2D optical flow) to 4D (depth + 3D scene flow).
- Loss
- Disparity loss: the same as self-supervised stereo system.
- Scene flow loss:
- photometric loss: target image --> lift to 3D --> add scene flow vector --> project to source --> compare with source
- point loss: src and target both project to 3d --> compare distance with scene flow vector
- edge aware scene flow loss
- Unified decoder for both depth and scene flow. Separating decoder leads to collapse in training.
- The performance for 2D optical flow is suboptimal but for 3D scene flow the best, as the loss regularizer is in 3D domain. Having a regularizer in the target domain is the best.
- Self supervised, then finetune on 200 annotated images boosted the performance dramatically. --> This means self-supervised approach can boost the performance of data efficiency.
- This seems to learn a metric scale scene flow nicely.
- video
- github repo
- It requires stereo for training and only need monocular at inference time. --> This can be extended to use a mono video only, by changing depth loss from using stereo to using sequence with the help of PoseNet.