Unofficial Visual Prompt Tuning implementation
- Paper: Visual Prompt Tuning. (ECCV 2022)
- Link: https://arxiv.org/abs/2203.12119
- Github(official): https://github.com/KMnP/vpt
The code I used in my experiments only references VPT-shallow and VPT-deep, which are the main methods in the official code.

- docker image: nvcr.io/nvidia/pytorch:22.12-py3
python main.py --default_setting default_configs.yaml \
--dataname $dataname \
--modelname $modelname \
--prompt_type $prompt_type \
--prompt_tokens $prompt_tokens \
--img_resize 224from models import VPT
model = VPT(
modelname = 'vit_base_patch16_224',
num_classes = 10,
pretrained = True,
prompt_tokens = 5,
prompt_dropout = 0.0,
prompt_type = 'shallow'
)Table 1. Learning parameters.
| Model | #Learnable Params |
|---|---|
| ViT-S/16 | 21,669,514 |
| ViT-S/16 - shallow | 5,770 |
| ViT-S/16 - deep | 26,890 |
| ViT-B/16 | 85,806,346 |
| ViT-B/16 - shallow | 11,530 |
| ViT-B/16 - deep | 53,770 |
| Number of prompt tokens: 5 |
Models
- ViT-S/16 (in1k and in21k)
- ViT-B/16 (in1k and in21k)
Datasets
The training data is sampled by class and used as a total of 1000.
- CIFAR10-1k
- CIFAR100-1k
Training setting
./default_configs.yaml
SEED: 223
DATASET:
datadir: /datasets
OPTIMIZER:
opt_name: SGD
params:
lr: 0.01
weight_decay: 0.0001
TRAINING:
batch_size: 128
test_batch_size: 256
epochs: 100
log_interval: 1
use_scheduler: true
use_wandb: true
RESULT:
savedir: './saved_model'I run run.sh for experiments
model_list="vit_small_patch16_224 vit_base_patch16_224 vit_small_patch16_224_in21k vit_base_patch16_224_in21k"
type_list="shallow deep"
datasets="CIFAR10 CIFAR100"
for d in $datasets
do
for m in $model_list
do
echo "modelname: $m, dataset: $d"
python main.py \
--default_setting default_configs.yaml \
--dataname $d \
--modelname $m \
--img_resize 224
for t in $type_list
do
echo "modelname: $m-$t, dataset: $d"
python main.py \
--default_setting default_configs.yaml \
--dataname $d \
--modelname $m \
--prompt_type $t \
--img_resize 224
done
done
done
# ablation number of prompt tokens
model="vit_base_patch16_224"
datasets="CIFAR10 CIFAR100"
type_list="shallow deep"
tokens="1 5 10 50 100"
for d in $datasets
do
for t in $type_list
do
for token in $tokens
do
echo "modelname: $model-$t, dataset: $d, prompt tokens: $token"
python main.py \
--default_setting default_configs.yaml \
--dataname $d \
--modelname $model \
--prompt_type $t \
--prompt_tokens $token \
--img_resize 224
done
done
done- Number of prompt tokens: 5
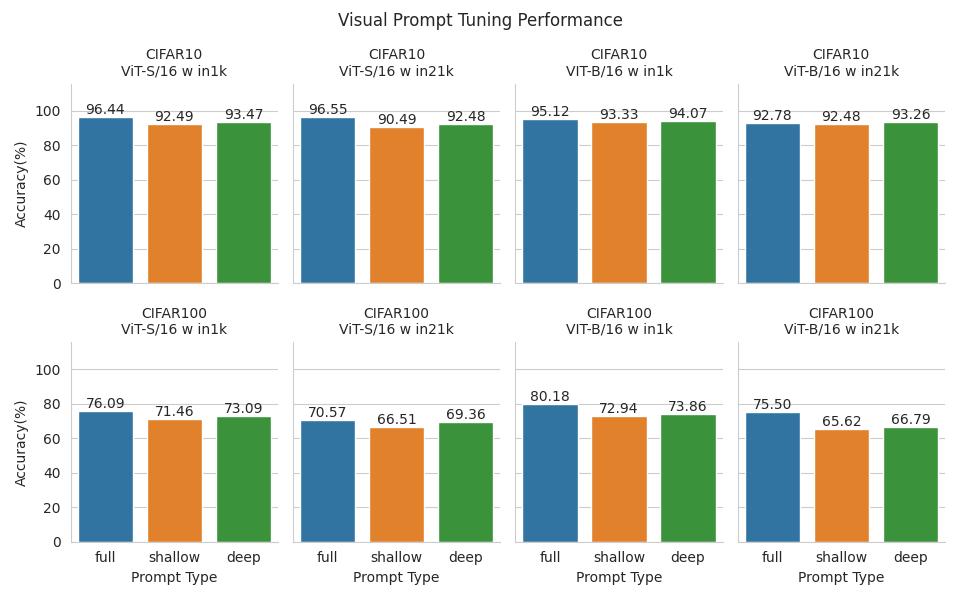
Figure 1. Model performance.

Figure 2. Ablation on prompt length.
Table 2. Model Performance.
| DATASET | MODEL | Pretrained | Prompt Type | Accuracy(%) |
|---|---|---|---|---|
| CIFAR10 | ViT-S/16 | in1k | full | 96.44 |
| shallow | 92.49 | |||
| deep | 93.47 | |||
| in21k | full | 96.55 | ||
| shallow | 90.49 | |||
| deep | 92.48 | |||
| VIT-B/16 | in1k | full | 95.12 | |
| shallow | 93.33 | |||
| deep | 94.07 | |||
| in21k | full | 92.78 | ||
| shallow | 92.48 | |||
| deep | 93.26 | |||
| CIFAR100 | ViT-S/16 | in1k | full | 76.09 |
| shallow | 71.46 | |||
| deep | 73.09 | |||
| in21k | full | 70.57 | ||
| shallow | 66.51 | |||
| deep | 69.36 | |||
| VIT-B/16 | in1k | full | 80.18 | |
| shallow | 72.94 | |||
| deep | 73.86 | |||
| in21k | full | 75.50 | ||
| shallow | 65.62 | |||
| deep | 66.79 |
Table 3. Ablation on prompt length.
| MODEL | DATASET | Prompt Type | # Prompt Tokens | Accuracy(%) |
|---|---|---|---|---|
| VIT-B/16 w in1k | CIFAR10 | shallow | 1 | 92.53 |
| 5 | 93.33 | |||
| 10 | 92.97 | |||
| 50 | 93.55 | |||
| 100 | 93.26 | |||
| deep | 1 | 93.11 | ||
| 5 | 94.07 | |||
| 10 | 94.12 | |||
| 50 | 92.86 | |||
| 100 | 91.81 | |||
| CIFAR100 | shallow | 1 | 70.45 | |
| 5 | 72.94 | |||
| 10 | 72.64 | |||
| 50 | 71.52 | |||
| 100 | 69.74 | |||
| deep | 1 | 71.95 | ||
| 5 | 73.86 | |||
| 10 | 73.23 | |||
| 50 | 67.97 | |||
| 100 | 62.85 |