{kind=link}
- O prazo padrão para entrega da solução é de 7 dias corridos, contados a partir da data de recebimento do desafio. Caso você precise de mais tempo, entre em contato conosco e fechamos uma nova data para a entrega. Não se preocupe, somos super flexíveis ;)
- Quando estiver tudo pronto, você deve mandar um e-mail para codesubmissions@vagas.com.br com o assunto
Engenheiro(a) de Dados VAGAS.com - <%SEU_NOME%>e o link para o seu repositório.
- Não se preocupe em responder todos os pontos do desafio. Queremos ver até que ponto você consegue se aprofundar :)
Engenheiros de dados são responsáveis por compilar e instalar sistemas de banco de dados, escrever consultas complexas, dimensionar dados para várias máquinas e implementar sistemas de recuperação de desastres. O engenheiro de dados deve ter um bom entendimento de dados estruturados e não estruturados e deve ser capaz de construir pipelines que movam dados por toda a empresa.
”Um cientista de dados não pode criar algoritmos ou métricas sem ter os dados na granularidade correta ”
- Desenvolver, construir, testar e dar manutenção em arquiteturas BigData, como bancos de dados distribuídos e sistemas de processamento em larga escala (ex. Hadoop, Spark). Isso inclui também as fontes de dados da empresa, como o Data Warehouse, Data Lake etc.
- A manutenção é dividida com os analistas de infraestrutura.
- Prover os dados que o cientista de dados precisa para efetuar suas análises e construir seus modelos.
- Isso inclui uma primeira rodada de massagem dos dados, para normalizar seus tipos e remover dados inválidos.
- Exemplo: um dado bruto pode conter a informação de um cargo e cidade, "Garçom - São Paulo". O engenheiro vai separar esse campo em dois campos: "Cargo: Garçom" e "Cidade: São Paulo". Caso o campo "Cargo" tenha registros como "Garçom" e "Garssom", "Garsson", "garçon", essa preocupação não é do engenheiro. É mais provável que o cientista que fará esse tratamento e normalizar todos os cargos para "Garçom" pois isso é uma informação de domínio.
- Isso inclui uma primeira rodada de massagem dos dados, para normalizar seus tipos e remover dados inválidos.
- Extrair dados de outros sistemas, através de integração, geralmente usando linguagens de scripting.
- Encontrar oportunidades para aquisição de dados externos (ex. coleta de dados em outros websites, scraping).
- Programar APIs simples que exponham o modelo gerado pelo cientista de dados com uma interface de simples utilização.
- Em casos que a API seja complexa por qualquer motivo, talvez seja necessário o trabalho consultivo de um desenvolvedor backend.
- Construir um pipeline de produção de ponta-a-ponta, que colete os dados necessários onde quer que eles estejam, gere o modelo e exponha-o através de um API.
Temos um projeto onde iremos construir uma rede social para amantes de vinhos, onde nossos usuários poderão se cadastrar e compartilhar fotos, gostos, experiências, etc... e com base nessas interações iremos recomendar novos vinhos e onde comprá-los. Para deixar nosso sistema mais inteligente iremos coletar dinamicamente as informações dos vinhos em e-commerces e demais sites na internet através de web crawlers que irão indexar estes dados em um DataLake. E Você como engenheiro de dados recebeu esta missão de montar a arquitetura deste DataLake
Para te ajudar, disponibilizamos os datasets abaixo representando o RAWDATA que nossos crawlers montam:
- Campos
- Id
- Country
- County
- Designation
- Points
- Price
- Province
- Title
- Imagem
- Variety
- Winer
- Campos:
- Id
- Gender
- Age
- Country
- City
- GeoLocation
- Like Sports
- Like Games
- Like Netflix
- Favorite Wine
Com base nos datasets acima, proponha um desenho arquitetural descritivo, cobrindo os seguintes cenários:
- Um Cientista de Dados solicitou uma base no qual quer saber se existe relação entre o preço de um vinho e país. Ele prefere que seja um arquivo csv com 100 amostras aleatoriamente. Como você faria essa operação na arquitetura proposta?
- No final do ano, um outro Cientista de Dados solicitou melhorar o modelo que foi gerado entre preço e pais, e precisa exatamente o mesmo dataset disponibilizado para a primeira versão. Como na arquitetura proposta isso poderá ocorrer?
- Um Cientista de Dados solicitou uma forma de verificar se existe a característica de "doçura" (sweetness) do vinho. Como a sua arquitetura disponibiliza a busca de existência e significado de cada informação?
- Novas APIs complementares foram desenvolvidas para fornecer dados dos fabricantes de Vinhos: ano da safra, tipo de uva e nossos Crawlers já estão prontos para concatenar essas informações para os novos itens à coletar, porém os antigos precisam desta informação também. Como você propõe a adição destes dados na Arquitetura Proposta?
- O excesso de requisições ao data lake está perdendo desempenho gradativamente, aumentando o tempo de resposta. Como você propõe analisar o desempenho? Existe alguma estratégia para escalar?
- Um requisito primordial é a integridade de todas as informações salvas no data lake. Como você trabalharia com backup e redundância?
- Temos um apreço muito grande pela qualidade e disponibilidade. Para isso, contamos com algumas métricas para ajudar a nos prevenir e/ou nos alertar sobre problemas. Como metrificar e monitorar as atividades na Arquitetura Proposta?
- Temos um limite financeiro para investir mensalmente. Considerando Clouds Públicas e utilizando a arquitetura proposta, como poderíamos explorar este cenário financeiramente?
- Fomos questionados, por uma ação judicial, sobre dados que foram vazados. Como na sua arquitetura vamos proteger a confidencialidade de dados?
- Nosso negócio está expandindo e agora temos informações atualizadas dos vinhos vindos direto dos produtores. Alguns deles enviam por excel e outros por APIs. Como a arquitetura comporta esse tipo de entrada de dados?
- Uma nova feature no nosso sistema agora permite que o usuário tire foto de um rótulo no mercado e nos envie, via API, para que nosso time de Ciência de dados possa construir uma funcionalidade de sugestões de vinhos semelhantes. Como os meta dados e a imagem do rótulo podem ser armazenados e associados ao usuário nessa estrutura?
- Os dados de recomendação de vinhos, baseados na foto do rótulo enviado, trouxe um interesse bem grande para tomadas de decisões. Na criação de um dashboard: Como sua arquitetura pode mostrar as nuances periódicas (ex. início vs fim de ano)? Como sua arquitetura pode deixar aparente que hoje houve um aumento bem grande pela procura de vinhos?
- Os dados de Preço precisam ser convertidos para Real e também preservando seu valor original em dólar. Como você estruturaria essa transformação?
Neste repositório você terá disponivel uma amostra de dados para auxiliar montagem da arquitetura deste desafio:
Nas respostas, esperamos um mapa arquitetural:
- Esquemas de fluxo de dados
- Descrições de funcionamento
- Nomes das tecnologias (softwares, serviços, conectores, bibliotecas, módulos de programas que - você teria que desenvolver e etc)
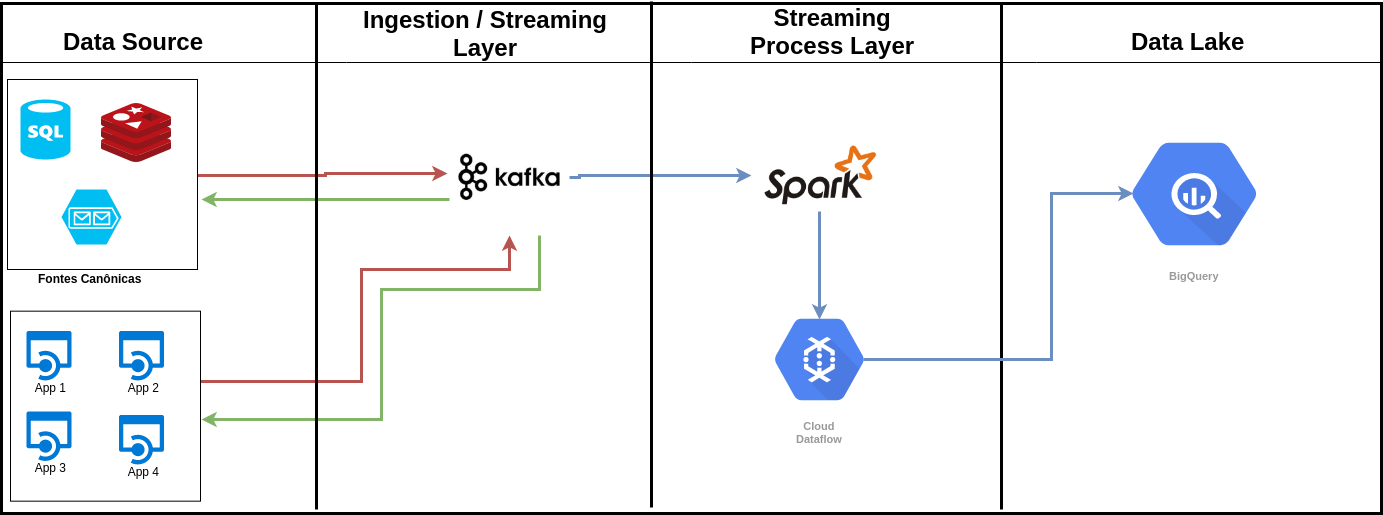
-
cenário: “Um Cientista de Dados solicitou uma base no qual quer saber se existe relação entre o preço de um vinho e país. Ele prefere que seja um arquivo csv com 100 amostras aleatoriamente. Como você faria essa operação na arquitetura proposta?”
- R: No modelo proposto com o Z esse dataset seria persistido de maneira XYZ e uma aplicação externa poderia se conectar a essa base para executar uma query extraindo a amostra de 100 itens e salva-lo em CSV...
-
cenário: “No final do ano, um outro Cientista de Dados solicitou melhorar o modelo que foi gerado entre preço e pais, e precisa exatamente o mesmo dataset disponibilizado para a primeira versão. Como na arquitetura proposta isso poderá ocorrer?”
- R: No modelo proposto com o Z o dado bruto ficaria disponível de forma XPTO de forma permanente e incremental, sendo assim possibilita a criação de novos modelos aproveitando...
Esperamos que você se divirta codificando essa solução. Estamos aqui (codesubmissions@vagas.com.br) caso surjam dúvidas durante o desenvolvimento.
Boa sorte :)