
TiledArray is a scalable, block-sparse tensor framework for rapid composition of high-performance tensor arithmetic, appearing for example in many-body quantum mechanics. It allows users to compose tensor expressions of arbitrary complexity in native C++ code that closely resembles the standard mathematical notation. The framework is designed to scale from a single multicore computer to a massive distributed-memory multiprocessor.
TiledArray is built on top of MADNESS parallel runtime (MADWorld), part of MADNESS numerical calculus framework.
TiledArray is a work in progress. Its development has been possible thanks to generous support from the U.S. National Science Foundation, the Alfred P. Sloan Foundation, the Camille and Henry Dreyfus Foundation, and the Department of Energy.
- General-purpose arithmetic on dense and block-sparse tensors;
- High-level (math-like) composition as well as full access to low-level data and algorithms, both from C++
- Massive shared- and distributed-memory parallelism
- Deeply-reusable framework: everything can be customized, from tile types (e.g. to support on-disk or compute-on-the-fly tensors) to how the structure of sparse tensors is described.
The following example expressions are written in C++ with TiledArray. TiledArray use the Einstein summation convention when evaluating tensor expressions.
-
Matrix-matrix multiplication
C("m,n") = 2.0 * A("m,k") * B("k,n");
-
Matrix-vector multiplication
C("n") = A("k") * B("k,n");
-
A more complex tensor expression
E("m,n") = 2.0 * A("m,k") * B("k,n") + C("k,n") * D("k,m");
The following application is a minimal example of a distributed-memory matrix multiplcation.
#include <tiledarray.h>
int main(int argc, char** argv) {
// Initialize the parallel runtime
TA::World& world = TA::initialize(argc, argv);
// Construct a 2D tiled range structure that defines
// the tiling of an array. Each dimension contains
// 10 tiles.
auto trange = TA::TiledRange{
TA::TiledRange1{0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100},
TA::TiledRange1{0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100}};
// Construct and fill the argument arrays with data
TA::TArrayD A(world, trange);
TA::TArrayD B(world, trange);
A.fill_local(3.0);
B.fill_local(2.0);
// Construct the (empty) result array.
TA::TArrayD C;
// Perform a distributed matrix multiplication
C("i,j") = A("i,k") * B("k,j");
// Tear down the parallel runtime.
TA::finalize();
return 0;
}Parallel performance of TiledArray for multiplication of dense square matrices on Mira, an IBM BlueGene/Q supercomputer at Argonne National Laboratory, compared with that of Cyclops Tensor Framework and ScaLAPACK:
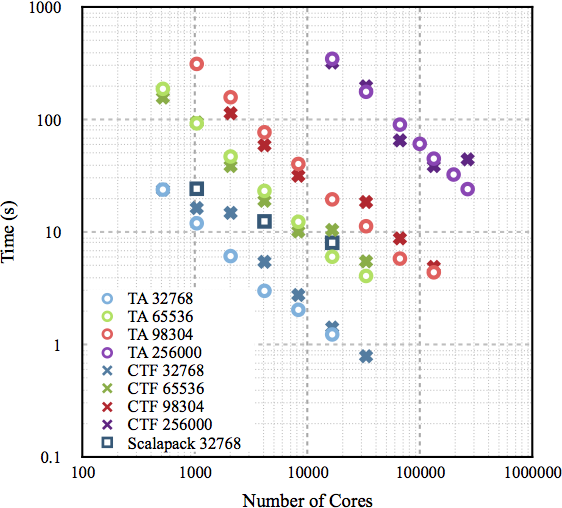
This figure was obtained with the help of an award from the Department of Energy INCITE program.
Excellent parallel scalability is also possible for much more complicated expressions than just a single GEMM, as demonstrated below for the coupled-cluster singles and doubles (CCSD) wave function solver. Parallel speed-up of 1 iteration of CCSD solver for uracil trimer in 6-31G* AO basis was measured on "BlueRidge" cluster at Virginia Tech (wall time on one 16-core node = 1290 sec):
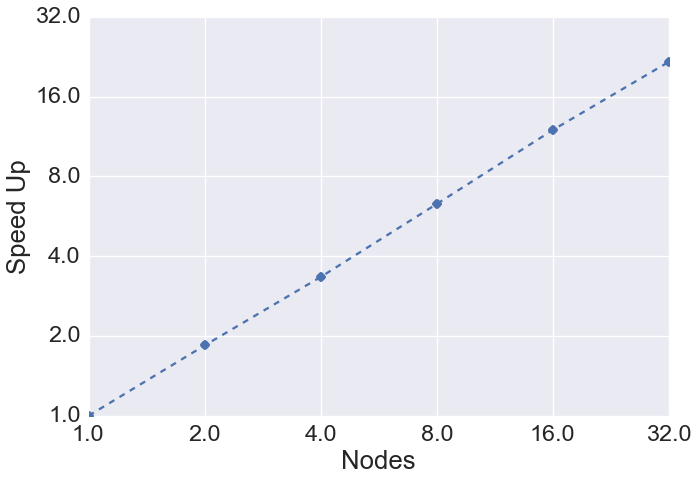
This figure was obtained with the help of an allocation from Advanced Research Computing at Virginia Tech.
The short version: assuming that MPI compiler wrappers are in your path, and this is a platform with BLAS/LAPACK installed system-wide in a standard location:
$ git clone https://github.com/ValeevGroup/TiledArray.git tiledarray
$ cd tiledarray
$ cmake -B build \
-D CMAKE_INSTALL_PREFIX=/path/to/tiledarray/install \
-D CMAKE_TOOLCHAIN_FILE=cmake/vg/toolchains/<toolchain-file-for-your-platform>.cmake \
.
$ cmake --build build
(optional) $ cmake --build build --target check
$ cmake --build build --target install
Here <toolchain-file-for-your-platform> is the appropriate toolchain file from the Valeev Group CMake kit; an alternative is
to provide your own toolchain file. On some standard platforms (e.g. MacOS) the toolchain file can be skipped.
The detailed instructions can be found in INSTALL.md.
TiledArray documentation is available for the following versions:
TiledArray is developed by the Valeev Group at Virginia Tech.
TiledArray is freely available under the terms of the GPL v3+ licence. See the the included LICENSE file for details. If you are interested in using TiledArray under different licensing terms, please contact us.
Cite TiledArray as
"TiledArray: A general-purpose scalable block-sparse tensor framework", Justus A. Calvin and Edward F. Valeev, https://github.com/valeevgroup/tiledarray .
Inner workings of TiledArray are partially described in the following publications:
- Justus A. Calvin, Cannada A. Lewis, and Edward F. Valeev, "Scalable Task-Based Algorithm for Multiplication of Block-Rank-Sparse Matrices.", Proceedings of the 5th Workshop on Irregular Applications: Architectures and Algorithms, http://dx.doi.org/10.1145/2833179.2833186.
- Justus A. Calvin and Edward F. Valeev, "Task-Based Algorithm for Matrix Multiplication: A Step Towards Block-Sparse Tensor Computing." http://arxiv.org/abs/1504.05046 .
The MADNESS parallel runtime is described in the following publication:
- Robert J. Harrison, Gregory Beylkin, Florian A. Bischoff, Justus A. Calvin, George I. Fann, Jacob Fosso-Tande, Diego Galindo, Jeff R. Hammond, Rebecca Hartman-Baker, Judith C. Hill, Jun Jia, Jakob S. Kottmann, M-J. Yvonne Ou, Junchen Pei, Laura E. Ratcliff, Matthew G. Reuter, Adam C. Richie-Halford, Nichols A. Romero, Hideo Sekino, William A. Shelton, Bryan E. Sundahl, W. Scott Thornton, Edward F. Valeev, Álvaro Vázquez-Mayagoitia, Nicholas Vence, Takeshi Yanai, and Yukina Yokoi, "madness: A Multiresolution, Adaptive Numerical Environment for Scientific Simulation.", SIAM J Sci Comput 38, S123-S142 (2016), http://dx.doi.org/10.1137/15M1026171 .
Development of TiledArray is made possible by past and present contributions from the National Science Foundation (awards CHE-0847295, CHE-0741927, OCI-1047696, CHE-1362655, ACI-1450262, ACI-1550456), the Alfred P. Sloan Foundation, the Camille and Henry Dreyfus Foundation, the Department of Energy Exascale Computing Project (NWChemEx subproject), and the Department of Energy INCITE Program.