Knowledge Distillation(KD) is a general purpose technique that at first glance is widely applicable and complements all other ways of compressing neural networks . The key idea is to use soft probabilities (or ‘logits’) of a larger “teacher network” to supervise a smaller “student” network, in addition to the available class labels. These soft probabilities reveal more information than the class labels alone, and can purportedly help the student network learn better.
| Content | LINK |
|---|---|
| Pretrained Model | Google Drive |
| Documents | Google Drive |
| Demo Video | Youtube |

For distilling the learned knowledge we use Logits (the inputs to the final softmax). Logits can be used for learning the small model and this can be done by minimizing the squared difference between the logits produced by the cumbersome model and the logits produced by the small model.
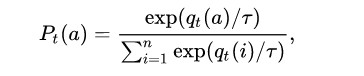

Different student architectures perform better on different distributions data. A teacher can’t effectively distill it’s knowledge to students for all the data distribution. To alleviate this shortcoming, we introduce multi-student knowledge distillation, which employs a multiple student model to bridge the gap between the data distribution and the student meta architecture. To the best of our knowledge we are the first group to attempt multi-student KD framework.
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.

Installing dependencies
pip install -r requirements.txtResNet, short for Residual Networks is a classic neural network used as a backbone for many computer vision tasks.The fundamental breakthrough with ResNet was it allowed us to train extremely deep neural networks with 150+layers successfully. Prior to ResNet training very deep neural networks was difficult due to the problem of vanishing gradients.This problem was addressed using the concept of skip connections.

Training the Teacher
python teacherTrain.py Student 1 - DenseNet121
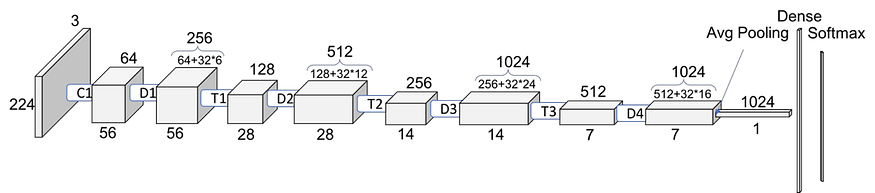
DenseNet (Dense Convolutional Network) is an architecture that focuses on making the deep learning networks go even deeper, but at the same time making them more efficient to train, by using shorter connections between the layers. DenseNet is a convolutional neural network where each layer is connected to all other layers that are deeper in the network, that is, the first layer is connected to the 2nd, 3rd, 4th and so on, the second layer is connected to the 3rd, 4th, 5th and so on
Student 2 - GoogleNet
The GoogleNet Architecture is 22 layers deep, with 27 pooling layers included. There are 9 inception modules stacked linearly in total. The ends of the inception modules are connected to the global average pooling layer.

- To train DenseNet using Knowledge Distilation
python StudentTrain.py --model 1or
- To train GoogleNet using Knowledge Distilation
python StudentTrain.py --model 2Model Selector plays a fudametal role in identifying which student model will give the best accuracy for a given image data. So, the role of the model selector is to extract the features from the input image data and select the corresponding student model which will provide the best estimation. We chose a 3 Layer CNN architecture for performing the model selection by carrying out empherical studies on the data distribution. The empherical studies carried out reveals that a signle or two layered CNN (with or without batch normalisation) perform poorly. We then experimented with a 3 and 4 layer CNN with and without batch normalisation and we observed that 3 Layer CNN without batch normalisation also performs poorly.
python trainSelector.py python inference.py The pre-trained weights for all the models can be obtained from the following link. Google Drive
| Model | Accuraccy |
|---|---|
| Teacher ResNet50 | 81% |
| Student 1 - DenseNet | 74.19% |
| Student 2 - GoogleNet | 73.21% |
| Model Selector with Students | 79.67% |


| Compression of individual student Models | No. of parameters | Space Consumed | MAC |
|---|---|---|---|
| DenseNet121 | 87.30% | 68.40% | 21% |
| GoogleNet | 76.30% | 74.49% | 68.1% |
| Compression with our proposed approach | No. of parameters | Space Consumed |
|---|---|---|
| DenseNet121+ Model Selector | 85.17% | 66% |
| GoogleNet+ Model Selector | 74.15% | 72.23% |
| Overall Compression (If the Model selector fails) | No. of parameters | Space Consumed |
|---|---|---|
| Teacher(ResNet-50)+DenseNet-121+GoogleNet+ Model Selector | 61.40% | 40.61% |