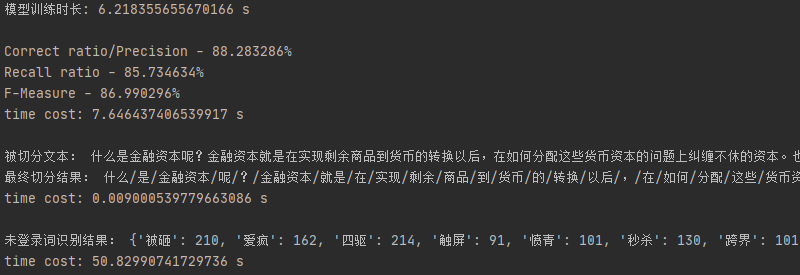
| 评价标准 | 结果 |
|---|---|
| 准确率 | 88.283286% |
| 召回率 | 85.734634% |
| F-测度值 | 86.990296% |
使用方法:
# 训练模型
dictname = '30wChinsesSeqDic.txt' # 词典资源
train = 'train.txt' # 训练集
with open(os.getcwd() + '/' + dictname, encoding='UTF-8-sig') as fp:
with open(os.getcwd() + '/' + train, encoding='UTF-8-sig') as f:
model = _NGramModel(cdict=fp, train=f, smooth=1)
# 分词演示
text = model.split('什么是金融资本呢?金融资本就是在实现剩余商品到货币的转换以后,在如何分配这些货币资本的问题上纠缠不休的资本。也就是说,金融资本是在工业资本完成了由货币到商品(即购买生产资料和雇工)和再由商品到货币(即产品市场出卖)的两个转换以后,在蛋糕造好了以后,就如何分蛋糕的抢夺中,通过贷款利息、股权和期货交易等等手段大显身手的资本。金融资本本身和商品价值的创造毫无关系,因而它是寄生性的。')
print(text)被切分文本:
什么是金融资本呢?金融资本就是在实现剩余商品到货币的转换以后,在如何分配这些货币资本的问题上纠缠不休的资本。也就是说,金融资本是在工业资本完成了由货币到商品(即购买生产资料和雇工)和再由商品到货币(即产品市场出卖)的两个转换以后,在蛋糕造好了以后,就如何分蛋糕的抢夺中,通过贷款利息、股权和期货交易等等手段大显身手的资本。金融资本本身和商品价值的创造毫无关系,因而它是寄生性的。
切分结果:
什么/是/金融资本/呢/?/金融资本/就是/在/实现/剩余/商品/到/货币/的/转换/以后/,/在/如何/分配/这些/货币资本/的/问题/上/纠缠/不休/的/资本/。/也就是说/,/金融资本/是在/工业/资本/完成/了/由/货币/到/商品/(/即/购买/生产资料/和/雇工/)/和/再/由/商品/到/货币/(/即/产品市场/出卖/)/的/两个/转换/以后/,/在/蛋糕/造/好/了/以后/,/就/如何/分/蛋糕/的/抢夺/中/,/通过/贷款/利息/、/股权/和/期货/交易/等等/手段/大显身手/的/资本/。/金融资本/本身/和/商品/价值/的/创造/毫/无/关系/,/因而/它/是/寄生性/的/。
使用方法:
# 未登录词识别
with open(os.getcwd() + '/COAE2015微博观点句识别语料.txt', encoding='UTF-8-sig') as fp:
words = model.findwords(fp)
print('未登录词识别结果:', words)未登录词识别结果:
{'被砸': 210, '爱疯': 162, '四驱': 214, '触屏': 91, '愤青': 101, '秒杀': 130, '跨界': 101, '迈腾': 698, '傻逼': 93, '刘翔': 183, '吐槽': 152, '尊享': 130, '双节': 217, '谷歌': 349, '抱着': 59, '前脸': 217, '爸妈': 71, '脑残': 134, '魅族': 708, '微博': 1538, '杨幂': 117, '触控': 107, '四核': 464, '干嘛': 125, '官网': 227}
- 运行环境
- PyCharm Community Edition 2020.1 x64
2020/5/21 -完成了基本的分词功能。
2020/5/25 -对原有代码进行了小幅度的性能优化;
完成了基本的未登录词识别功能。(会尝试在后续的更新中继续对其性能优化)