




| Cherry | Windson |
|---|---|
| Download | https://pypi.python.org/pypi/cherry |
| Source | https://github.com/Windsooon/cherry |
| Keywords | machine learning, text classification |
Even though you had never learned about machine learning. You can use Cherry to train your text classification model in 5 minutes with over 80% accuracy. Cherry also provides extra features for users who want to improve their model.
Cherry provide performence() and display() api to help you debug and improve your model.
- Python (above 3.6)
Install using pip
pip install cherry
# Cherry use nltk for text tokenizer
pip install nltk
# After install nltk, You need to download punkt for tokenizer
>>> import nltk
>>> nltk.download('punkt')
Cherry has three built in text classification models: newsgroups, review and email:
-
These datasets contain 11,315 news. they were organized into 20 different newsgroups, each corresponding to one of the below topic:
- alt.atheism, comp.graphics, comp.os.ms-windows.misc, comp.sys.ibm.pc.hardware
- comp.sys.mac.hardware, comp.windows.x, misc.forsale, rec.autos
- rec.motorcycles, rec.sport.baseball, rec.sport.hockey, sci.crypt
- sci.electronics, sci.med, sci.space, soc.religion.christian
- talk.politics.guns, talk.politics.mideast, talk.politics.misc, talk.religion.misc
-
These datasets contain 108,463 reviews from the Goodreads book review website, Every book review also has rating from 0 point to 5 points.
-
These datasets contain 5,578 SMS messages manually extracted from the Grumbletext Web site and randomly chosen ham messages of the NUS SMS Corpus (NSC).
In the Comics & Graphic book review datasets, each review has a corresponding rating from 1 to 5. For example, if you want to predict the rating based on this book review:
This is an extremely entertaining and often insightful collection by Nobel physicist Richard Feynman drawn from slices of his life experiences. Some might believe that the telling of a physicist’s life would be droll fare for anyone other than a fellow scientist, but in this instance, nothing could be further from the truth.
Train the model in your Python environment.
Python3
>>> cherry.train('review')
This line of code will:
- Download
reviewdatasets from remote server (User in China may need use VPN) - Train datasets using default settings (Countvectorizer and MultinomialNB)
You only need to train the model once, and subsequent classification tasks do not need to be retrained
You can use classify() to predict the rating now.
>>> res = cherry.classify('review', text='This is an extremely entertaining and often
insightful collection by Nobel physicist Richard Feynman drawn from slices of his life
experiences. Some might believe that the telling of a physicist’s life would be droll
fare for anyone other than a fellow scientist, but in this instance, nothing could be
further from the truth.')
The return res is a Classify object has two built-in method. get_probability() will return an array contains the probability of each category. The order of the return array depend on category name, in this case would be 0, 1, 2, 3, 4. We can see that there is 99.63% (9.96313288e-01) this review is rated 4 point.
# The probability of this review had been rating as 4 points is 99.6%
>>> res.get_probability()
array([[6.99908424e-11, 2.48677319e-11, 6.17978214e-06, 3.39472694e-03,
9.96313288e-01, 2.85805135e-04]])
Another method get_word_list() return a list that contains words that Cherry use for classifying.
>>> res.get_word_list()
[[(2, 'physicist'), (2, 'life'), (1, 'truth'), (1, 'telling'), (1, 'slices'), (1, 'scientist'), (1, 'richard'), (1, 'nobel'), (1, 'instance'), (1, 'insightful'), (1, 'feynman'), (1, 'fellow'), (1, 'fare'), (1, 'extremely'), (1, 'experiences'), (1, 'entertaining'), (1, 'droll'), (1, 'drawn'), (1, 'collection'), (1, 'believe')]]
Some of the words in the review didin't show up here. There are two reasons for this 1) The training data didn't contain that word. For instance, The word Backend and Engineer never show up in training data. So the model don't know how to classify these words. 2) the word is a stop word.
In the cherry folder, you can find a new folder named datasets. The five folders inside correspond to 1 to 5 points respectively. cherry uses the word frequency inside different folders to determine which word belongs to which score. When performing a classification task, cherry will calculate the probability of all words in the review to determine which category it belongs to.
Create a folder your_model_name under datasets in project path like this:
├── project path
│ ├── datasets
| │ ├── your_model_name
| │ │ ├── category1
| | │ ├── file_1
| | │ ├── file_2
| | │ ├── …
| │ │ ├── category2
| | │ ├── file_10
| | │ ├── file_11
| | │ ├── …
Train you dataset:
# By default, encoding will be utf-8,
# You only need to run `train` at the first time
>>> cherry.train('your_model_name', encoding='your_encoding')
# Classify text, `text` can be a list of text too.
>>> res = cherry.classify('your_model_name', text='text to be classified')
Let's build an email classifier from sketch, cherry will use this model to predict an email is spam or not.
mkdir tutorial
cd tutorial
# Create a virtual environment to isolate our package dependencies locally
python3 -m venv env
source env/bin/activate # On Windows use `env\Scripts\activate`
# Install cherry and nltk
pip install cherry
pip install nltk
>>> import nltk
>>> nltk.download('punkt')
# Create a new folder for email dataset
mkdir -p datasets/email_tutorial
-
Download the datasets from SMS Spam Collection v. 1 then unzip it and put it inside
tutorial/datasets/email_tutorialfolder, now you got a file namedSMSSpamCollection.txtwhich contains lots of emails. -
Create a folder name
hamandspaminsideemail_tutorialdir. -
Create a script
email.pyin the same folder using code below to extract the email content and group them by category. every file would only contain text.import os import json ham_counter = 0 spam_counter = 0 with open('SMSSpamCollection.txt', 'r') as f: for line in f.readlines(): if line.startswith('ham'): ham_counter += 1 with open(os.path.join('ham', str(ham_counter)), 'w') as nf: _, text = line.split('ham', 1) nf.write(text.strip()) else: spam_counter += 1 with open(os.path.join('spam', str(spam_counter)), 'w') as nf: _, text = line.split('spam', 1) nf.write(text.strip()) -
Now your folder structure should look like this:
tutorial ├── dataset │ ├── email_tutorial | | ├── email.py | | ├── SMSSpamCollection.txt │ │ ├── ham │ │ ├── spam -
Run
python email.py -
Delete
SMSSpamCollection.txtandemail.py -
Back to the path of
tutorial, Likecd path_to/tutorial -
Train the email model:
>>> import cherry >>> cherry.train('email_tutorial', encoding='latin1') -
Inside
email_tutorialfolder you can findclf.pkz,ve.pkz,email_tutorial.pkzwhich Cherry will use them for classify later.>>> res = cherry.classify('email_tutorial', 'Thank you for your interest in cherry! We wanted to let you' 'know we received your application for Backend Engineer, and we are delighted that you' 'would consider joining our team.') # 99.9% is a ham email >>> res.get_probability() array([[9.99985571e-01, 1.44288379e-05]]) >>> res.get_word_list() [[(1, 'wanted'), (1, 'thank'), (1, 'team'), (1, 'received'), (1, 'let'), (1, 'joining'), (1, 'consider'), (1, 'application')]] -
If you want to know good your model did, you can use performance() which will use k-fold cross validation (By default, K equals to 10):
>>> res = cherry.performance('email_tutorial', encoding='latin1', output='files') >>> res.get_score()The report will be save in
reportfiles, you can find the precision, recall, and f1-score.precision recall f1-score support 0 0.99 1.00 0.99 485 1 0.97 0.95 0.96 73 accuracy 0.99 558 macro avg 0.98 0.97 0.98 558weighted avg 0.99 0.99 0.99 558
If you want to know which text had been clasiify wrong:
>>> res = cherry.performance('email_tutorial', encoding='latin1') >>> res.get_score() Text: Dhoni have luck to win some big title.so we will win:) has been classified as: 1 should be: 0 Text: Back 2 work 2morro half term over! Can U C me 2nite 4 some sexy passion B4 I have 2 go back? Chat NOW 09099726481 Luv DENA Calls £1/minMobsmoreLKPOBOX177HP51FL has been classified as: 0 should be: 1 Text: Latest News! Police station toilet stolen, cops have nothing to go on! has been classified as: 0 should be: 1 ... -
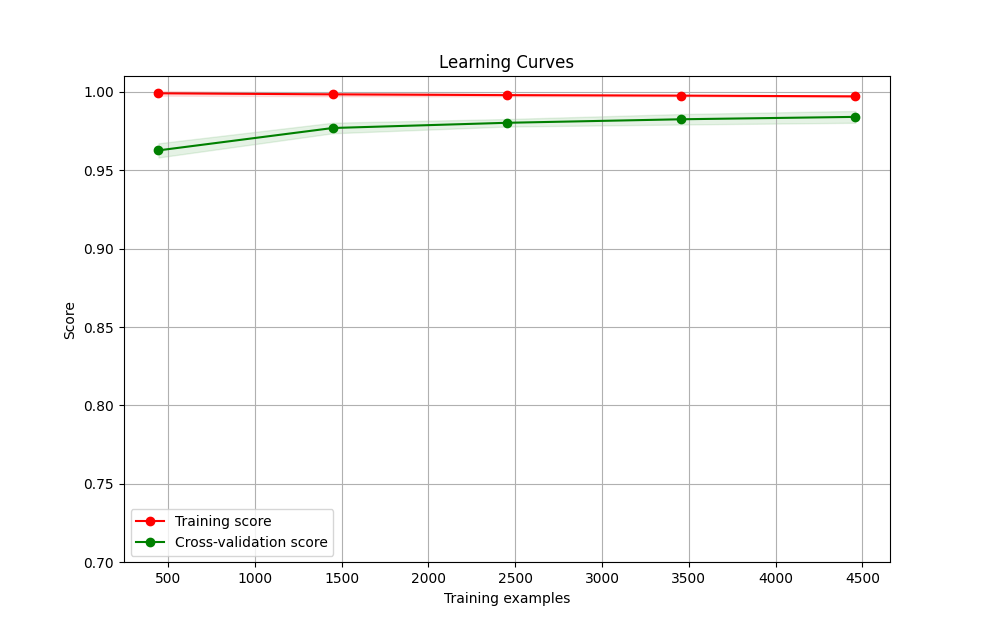
To display the graph, you can use
>>> res.display('email_tutorial', encoding='latin1')
-
If you want to improve your model, you can use search method.
>>> parameters = {'clf__alpha': [0.1, 0.5, 1],'clf__fit_prior': [True, False]} >>> cherry.search('email_tutorial', parameters)
def train(model, language='English', preprocessing=None, categories=None, encoding='utf-8', vectorizer=None, vectorizer_method='Count', clf=None, clf_method='MNB', x_data=None, y_data=None)
-
model (String)
The name of the model, you can use build-in models
email,reviewandnewsgroups, or pass the folder name of your dataset. -
language (String)
The language of the training dataset. Cherry supports
EnglishandChinese. -
preprocessing (function)
The function will be called once for every input data before training.
-
categories (List)
Specify the training directory, for instance ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc'].
-
encoding (String)
The encoding of the dataset.
-
vectorizer (Sklearn object)
Feature extraction function use to convert the data into vertcor,by default is
CountVectorizer(). you can pass different feature extraction function from Sklearn.For some long texts you can use
TfidfVectorizer(),If you need to save memory you can useHashingVectorizer(), (get_word_list() function wouldn't work at this case) -
vectorizer_method (String)
Cherry supports shortcut to set up feature extraction function when
vectorizerisNone.Countcorresponds toCountVectorizer(tokenizer=tokenizer, stop_words=get_stop_words(model)),Tfidfcorresponds toTfidfVectorizerandHashingcorresponds toHashingVectorizer. -
clf (Sklearn object)
Classify function, by default is
MultinomialNB(). You can pass classify function from Sklearn. -
clf_method (String)
Cherry supports shortcut to set up classify function when
clfisNone,MNBcorresponds toMultinomialNB(alpha=0.1),SGDcorresponds toSGDClassifier,RandomForestcorresponds toRandomForestClassifier,AdaBoostcorresponds toAdaBoostClassifier. -
x_data (numpy array)
training text data, if
x_dataandy_datais None, cherry will try to find the text files data inmodel -
y_data (numpy array)
correspond labels data, if
x_dataandy_datais None, cherry will try to find the text files data inmodel
-
model (String)
The name of the model, you can use build-in models
email,reviewandnewsgroups, or pass the folder name of your dataset. -
text (List / String)
the text to be classify.
def performance(model, language='English', preprocessing=None, categories=None, encoding='utf-8', vectorizer=None, vectorizer_method='Count', clf=None, clf_method='MNB', x_data=None, y_data=None, n_splits=10, output='Stdout')
Just as same as train() API
-
n_splits (Integer)
number of folds. Must be at least 2.
-
output ('Stdout' or 'Files')
'Stdout' will print the scores to standerd output and 'Files' will store the scores into a local file named 'report'.
def search(model, parameters, language='English', preprocessing=None, categories=None, encoding='utf-8', vectorizer=None, vectorizer_method='Count', clf=None, clf_method='MNB', x_data=None, y_data=None, method='RandomizedSearchCV', cv=3, n_jobs=-1):
def display(model, language='English', preprocessing=None, categories=None, encoding='utf-8', vectorizer=None, vectorizer_method='Count', clf=None, clf_method='MNB', x_data=None, y_data=None)
Just as same as train() API
>>> python runtests.py