This report is about building classifier and judging its performance for pedestrian detection with Caltech Pedestrian dataset. Logistic Regression with L2 regularization and ensemble of Logistic Regression with adaboost is used. Models are selected by 2-fold cross validation on train data. The result on test data obtained by Logistic Regerssion is 0.790 for precision and 0.751 for recall, while the result obtained by adaboost of Logistic Regression is 0.704 for precision and 0.829 for recall.The left parts are presented in the following orders, first we will talk about preprocessing of data, then we will talk about how to train the model of Logistic Regression and adaboost of Logistic Regression. Finally, we will test the models selected by cross validation on the test data to show their performance.
The training data set provided has 3605 positive samples and 10055 negative samples whlie the test data set has 2043 positive samples and 4832 negative samples.
Firstly, we will format the data, which means to store all train data in a file and all test data in another file. Each line of the file represents a sample, their features are seperated by space and the first field is the label of the sample while the 2330 fields are features of the sample.
Then we will split train data into 2 parts for cross validation, each part has half of positive samples and half of negative samples.
The above operations are implemented within the file Preprocessing.py. You can put the file Preprocessing.py and the folder of the data in the same path like this, data in folder PR_dataset need to be unzipped
|-- Preprocessing.py
|-- PR_dataset
|-- train
|-- test
Excuting the command python Preprocessing.py, and four new files will be generated in the folder PR_dataset
all_train_data: all the train datatrain_data_1: half of the train data with half positive and half negativetrain_data_2: the other half of the train datatest_data: all the test data
The reasons to choose Logistic Regression are as follow:
- Linear models should be applied firstly to see if it is linear seperable, if so, we can just use linear models. If not, then consider non-linear models
- This is a two-category classification problem, and Logistic Regression is suitable for this problem
- Logistic Regression is easier to implement and faster compared to those non-linear models
With maximum likelihood, we can infer the objective function of Logistic Regression, which is a unconstrained optimization problem, and here we solve this problem with stochastic gradient descent(SGD) or batch gradient descent(BGD).
SGD and BGD are both iterational algorithms, but SGD update all the parameters for each sample, while BGD update all the parameters only when it iterates all samples.
For SGD, its update rule is like this

In the above equation,
But for BGD, its update rule is like this(denotations has same meanings as metioned above)

Usually it is regarded that SGD is faster than BGD, however , the result of experiment show that BGD actually converges faster than SGD in terms of number of iterations.
Here is the result of the experiment, pay attention the experiment are taken on train_data_1 and train_data_2 with cross validation.
Firstly, let's have a look at the result of precision of both algorithms, the step size is set 0.01 here
| iterations | 200 | 500 | 800 | 1000 | 1500 | 2000 |
|---|---|---|---|---|---|---|
| SGD-precision | 0.895 | 0.868 | 0.857 | 0.853 | 0.846 | 0.847 |
| BGD-precision | 0.696 | 0.769 | 0.762 | 0.773 | 0.832 | 0.699 |
and the corresponding graph is
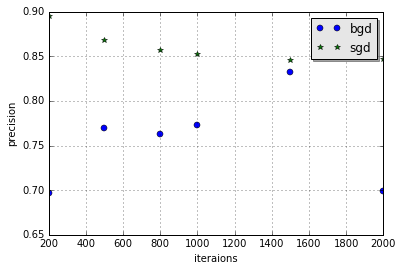
It seems that SGD is better than BGD in terms of precision . However, the result of recall shows the opposite trend, and is listed in the following table, still the step size is set 0.01 here
| iterations | 200 | 500 | 800 | 1000 | 1500 | 2000 |
|---|---|---|---|---|---|---|
| SGD-recall | 0.077 | 0.135 | 0.194 | 0.208 | 0.252 | 0.278 |
| BGD-recall | 0.692 | 0.511 | 0.837 | 0.808 | 0.606 | 0.856 |
and the corresponding graph is

So it's a litter hard to judge which is better with two criterions, to select the model, here we will use F1 socre obtained by precsion and recall with the formula$$F1 = 2*\frac{precision*recall}{precision+recall}$$
and the graph of F1 score based on the above result is
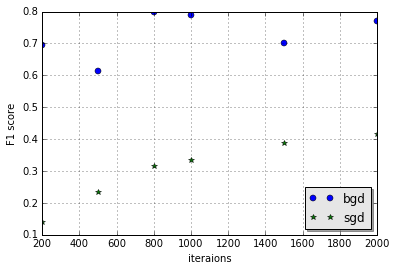
We can see that BGD with 800 iterations has the best result, however we don't know which step size is best, so we test on three kinds of step size(0.01, 0.05, 0.1) on BGD with 200 iterations, but the results show no difference, so we just set the step size as 0.01.
The Logistic Regression model is implemented in the file LogisticRegression.py, there are three parameters can be customized: step size, number of iterations and training method(BGD or SGD). Pay attention that the training algorithms has no regularization in the above experiment, since regularization is added later, and we will talk about it whether it works in the next part.
Regularazation is import for generalization performance, and here we will use L2 regularization.In the above part, we know that BGD outperforms SGD, so here we just test the effectiveness of regularization on BGD.
Here is the result of precision of BGD with and without regularization
| iterations | 200 | 500 | 800 | 1000 | 1500 | 2000 |
|---|---|---|---|---|---|---|
| precision without regularization | 0.696 | 0.769 | 0.762 | 0.773 | 0.832 | 0.699 |
| precision with regularization | 0.642 | 0.795 | 0.785 | 0.771 | 0.768 | 0.767 |
the corresponding graph is

And the following is the result of recall of BGD with and without regularization
| iterations | 200 | 500 | 800 | 1000 | 1500 | 2000 |
|---|---|---|---|---|---|---|
| recall without regularization | 0.692 | 0.511 | 0.837 | 0.808 | 0.606 | 0.856 |
| recall with regularization | 0.853 | 0.770 | 0.799 | 0.814 | 0.816 | 0.818 |
the corresponding graph is

Also we will compare them in terms of their F1 score as shown below
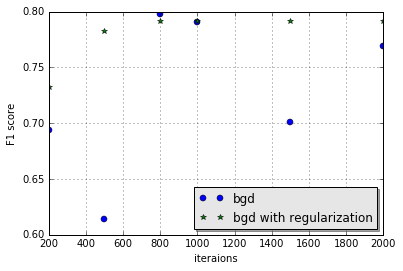
We can see from the above graph that even the best result is obtained by BGD without regularization when the number of iteration is 800. But BGD with regularization do much better in other cases, so it's more robust, and that is the reason that regularization is applied in the model.
With regularization, one more parameter that can be customized is added in the file LogisticRegression.py, that is lambda_, which is the parameter before the regularization term.
AdaBoost is an ensemble algorithm for constructing a "strong" classifier as linear combination of "simple" classifiers.
As Logistic Regreession is a linear classifier, it will work well if the data is linear seperable, but when the data is non-linear seperable, it may not work well.But applying adaboot with Logistic Regression, we can construct a non-linear classifer.
Applying adaboost to Logistic Regression requires recording the weight of each sample at each iteration, and this is exactly what the parameter sample_weights does in function logistic_regression in the file LogisticRegression.py. Also, the update rule need to be changed too. With adaboost, the gradient of the sample need to multiply its corresponding sample weight, then to update the parameters of the model.
One of the drawbacks of this method is that it is much more time comsuming than single Logistic Regression model, so we just have experiments with four differnt kinds of iteration.
Before comparing the result, pay attention that in the following result, single lr means there is only one model trained with BGD with regularization, and iterations is the number of iterations of BGD, adaboost of lr is the adaboost version of the corresponding Logistic Regression model, and the iteration of adaboost is set to 10, but when the error rate of the model is larger than 0.5, it will just quit even when there are less than 10 models.
Comparasion of precision of the models are listed below
| iterations | 200 | 500 | 800 | 1000 |
|---|---|---|---|---|
| single lr | 0.642 | 0.795 | 0.785 | 0.771 |
| adaboost of lr | 0.605 | 0.560 | 0.752 | 0.543 |
and the corresponding graph is

From the above result, single lr works much better than adaboost lr on precision,but evaluating on recall, the result is opposite as listed below
| iterations | 200 | 500 | 800 | 1000 |
|---|---|---|---|---|
| single lr | 0.853 | 0.770 | 0.799 | 0.814 |
| adaboost of lr | 0.901 | 0.951 | 0.838 | 0.957 |
and the corresponding graph is

so we judge them with F1 score as shown below

From the criterion of F1 score, we can see that adaboost lr is better or as well as single lr when number of iterations is less than or equal to 800, the reason is probably when the number of iterations is larger, the model suffers from overfitting.
And the best model selected from the above graph is the one when the number of iterations is 800.
The implementation of adaboost of Logistic Regression is in the file Adaboost.py, and there are three parameters that can be customized: iterations, gd_iteration and train_method, their properties are described below.
iterations is the number of models of adaboost, we test on 10,15 and 20 on this parameter, yet the results show that it doesn't improve a lot ,but it cost much more time, so 10 is a good choice. gd_iteration is the number of iteration of train_method, which can be SGD or BGD.
With cross validation on train data as described above, we can choose two best models and test it on the test data.
One is single Logistic Regression model trained with BGD, whose number of iterations is 800 with regularization; the other is adaboost of Logistic Regerssion, which is the linear combination of 10 Logistic Regression models, each model is also trained with BGD plus regularization, and iterations is set 800, too.
The result of these two models are listed below
| model | precision | recall |
|---|---|---|
| single Logistic Regression | 0.790 | 0.751 |
| adaboost | 0.704 | 0.829 |
The above report describes how to use the classical Logistic Regression to deal with the two-caterory classification problem.
Firstly, we compare BGD and SGD, which are two commonly used methods to train the model, and BGD works better on this problem.
Then we add L2 regularization to the model and find that it makes the result more robust, which proves that regularization can actually improve the generalization ability of the model.
Finally, in order to get a non-linear classifer, we use an ensemble method: adaboost, which generates linear combination of basic Logistic Regression model.However, the overall performance doesn't improve significantly, cause the model has the trend of increasing performance of recall but decreasing performance of precision compared to single Logistic Regression model. .And the reason is not very clear yet, perhaps this is the property of the model.