{kind=link}
{kind=link}
Cuda Matrix Implementation using Global and Shared memory.
The input follows this pattern:
- The number of lines of Matrix A
- The number of columns of Matrix A
- The number of lines of Matrix B
- The number of columns of Matrix B
- The values of Matrix A
- The values of Matrix B
The Shared method was implemented by dividing the Matrices into blocks.
Here is a few tests with a GeForce GTX 960M. The times are in milliseconds.
I ran the test 7 times for each line number and then averaged it.
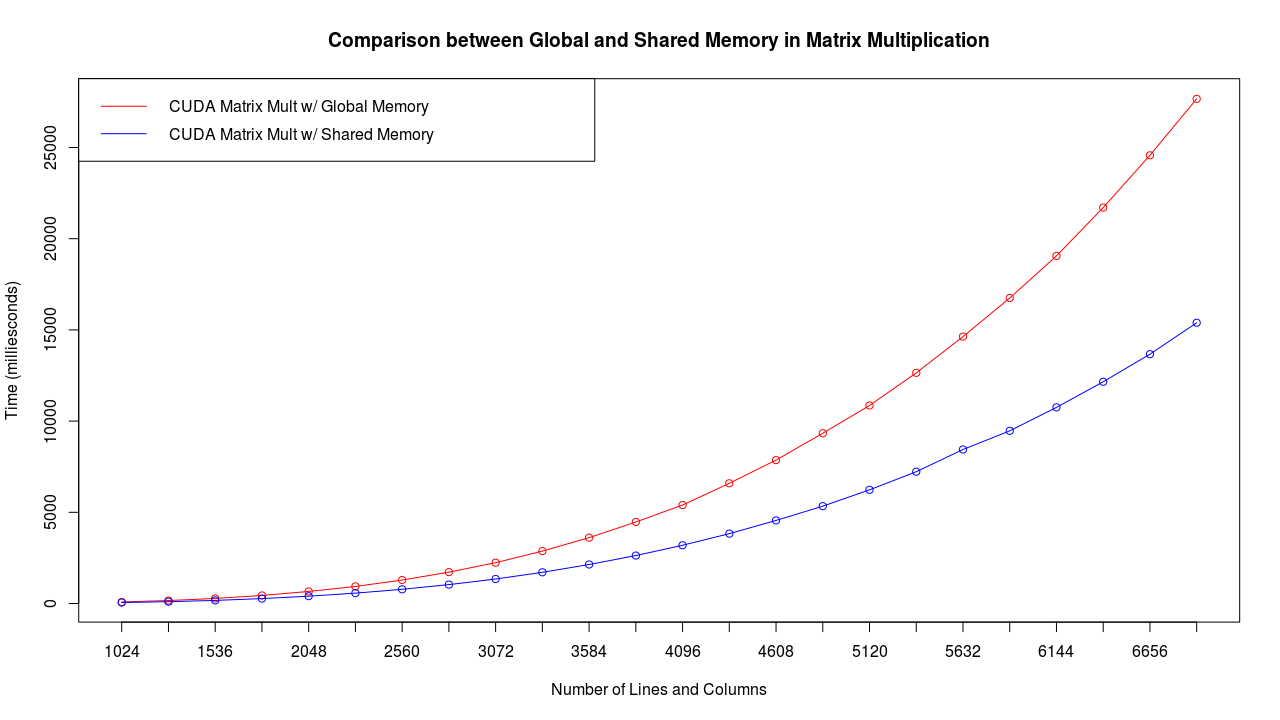
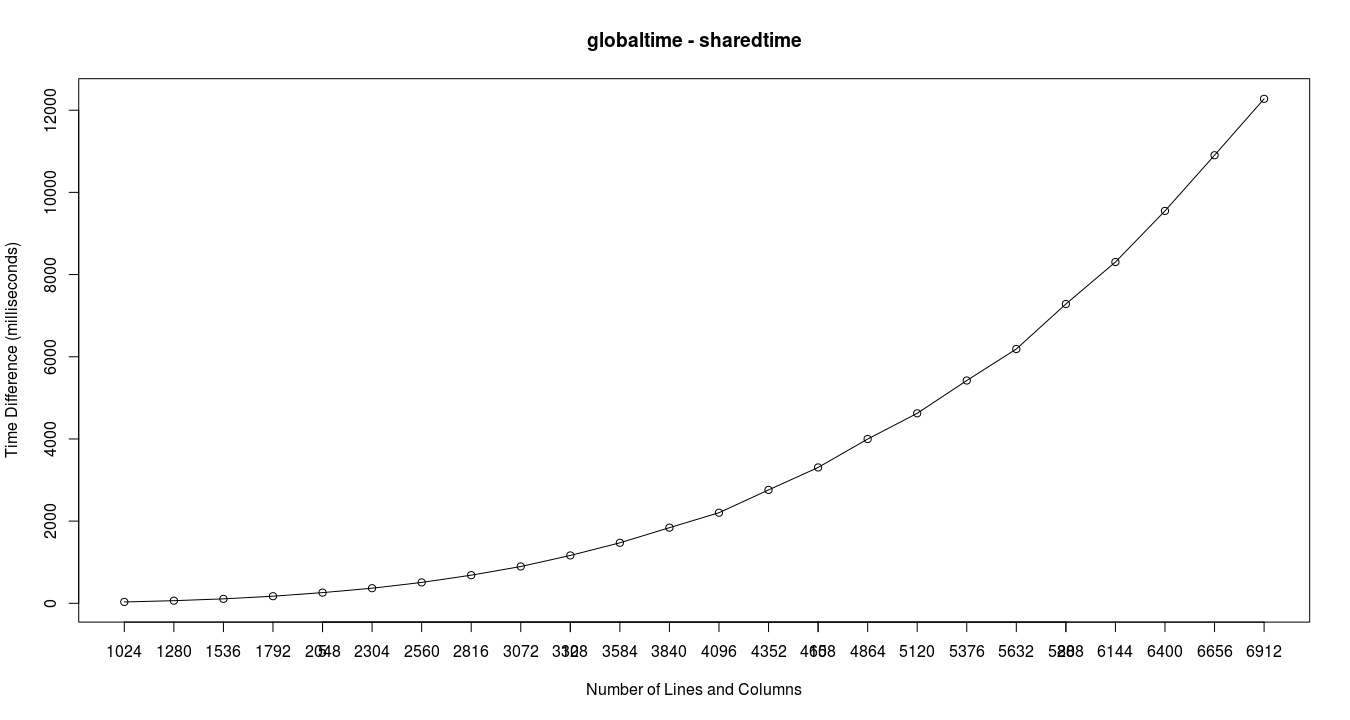
And the difference in time between global and shared memory.
- (optional) Use the script generate_input.py to generate a random Matrix
- Compile it & Run it