This repository has been archived by the owner on Apr 18, 2019. It is now read-only.
Indexing
###Building the jar for Hadoop First you need to build an 'uber jar' with Maven of the classes needed to build indexes in Hadoop.
In the root directory of Glimmer run:
mvn compile (or mvn test)
mvn assembly:single
This will produce the jar Glimmer-?.?.?-SNAPSHOT-jar-for-hadoop.jar in the directory ./target. This jar contains the Glimmer classes and all dependencies needed for Hadoop zipped into one file.
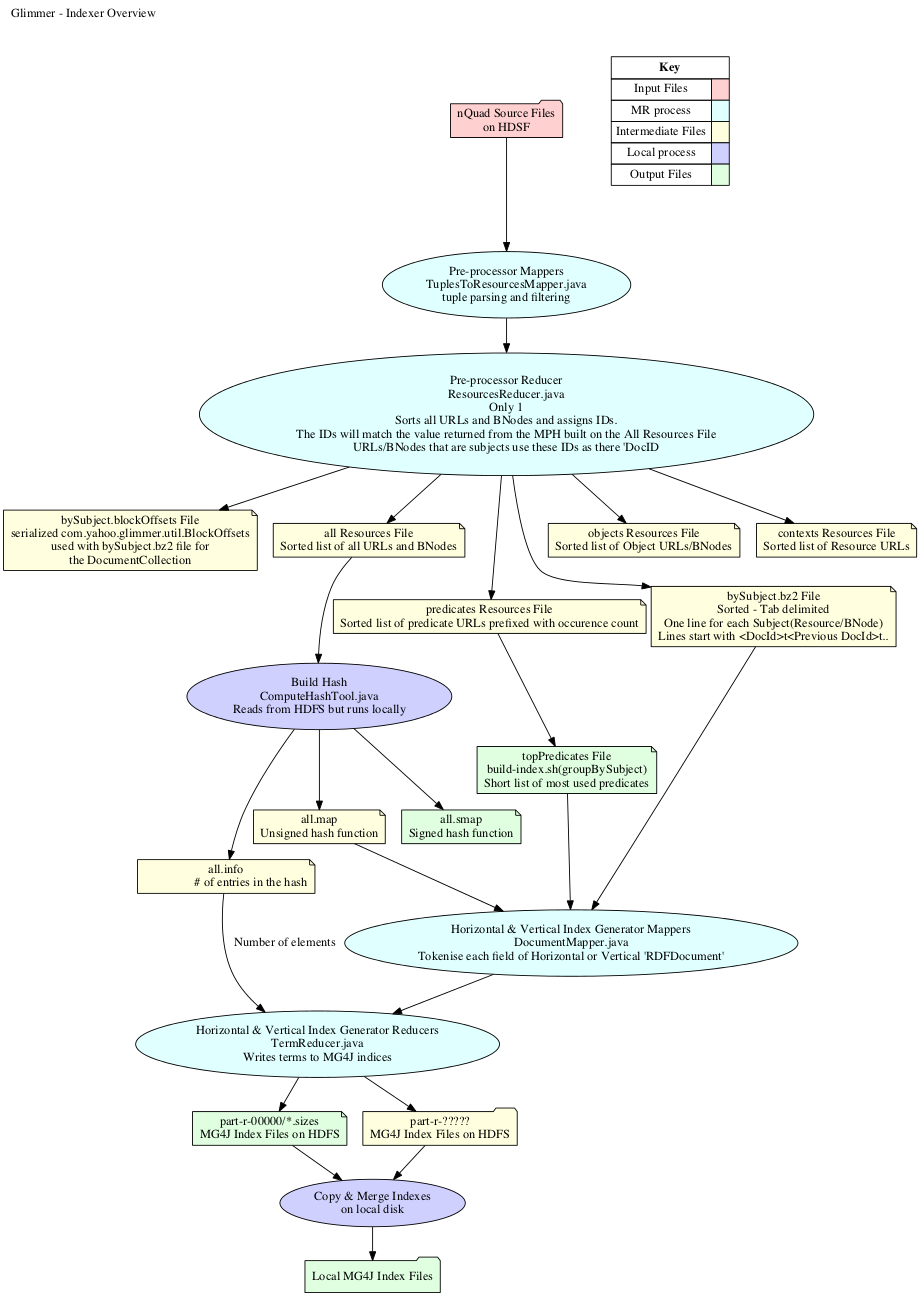
###The Index Building Process The steps of building MG4J indexes and collections for a given NQuads file or set of NQuads files is outlined below. Please see the build-index.sh shell script in the code base for exact details.
- Preprocess the NQuad tuples file to get:
- A sorted unique list of subjects with the subject's associated predicates, objects and contexts(.bz2).
- A serialized classes mapping between BZip2 block start offsets and the first document ID in the block.
- A sorted unique list of subject resources.
- A sorted unique list of predicate resources prefixed with there occurrence counts.
- A sorted unique list of all resources(Subject, Predicate, Object & Context).
- Build minimal perfect hash functions over the unique sorted lists of all resources. This function is a mapping of a given resource to its position in the unique sorted list.
- Get top N predicates by occurrence from the list of predicate resources. Defines for which predicates vertical indexes will be built.
- Build the 'horizontal' and 'vertical' (See the paper..) MG4J indexes.
- Compute the Document sizes.
- Copy all the generated files to the desired location.
Below is a diagram showing an overview of the processes and intermediate files used during index building.