{kind=link}
[Environment]
I created a virtual environment with Anaconda and installed the following packages.
GPU:Quadro RTX 6000
・python 3.7.11
・pytorch 1.6.0
・torchvision 0.7.0
・cuda tool kit 10.1
・numpy 1.21.5
・matplotlib 3.5.0
・scikit-learn 1.0.2
・pillow 8.4.0
・tqdm 4.62.3
I installed the latest versions of everything except python, pytorch, torchvision, and cuda toolkit. ※Only tqdm was installed by pip.
※Supported cuda tool kit, pytorch, and torch vision versions differ depending on the GPU used.
Please install the appropriate versions of the cuda tool kit, pytorch, and torch vision, see here.
[Data]
・CelebA
・about CelebA

↑There are nearly 300,000 images of men and women laughing.
[Network]
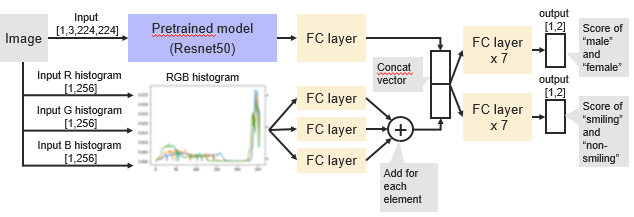
Original information of this network
・In the learning process, we tried to determine whether the image was male or female (first label), and whether it was smiling or non-smiling (second label).
・The parameters of the entire model were updated by learning.
・6000 images were obtained from the dataset for each of male, female/smiling, and non-smiling, for a total of 24000 images. (We did not use all the images to save memory and training time.)
・number of training data:number of test data = 9:1
・epoch:3
・learning rate:0.0001
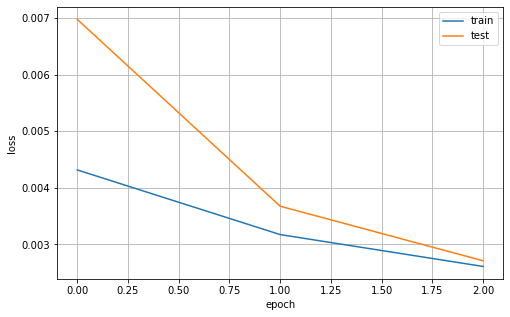
[Training loss・accuracy]
・loss
・accuracy
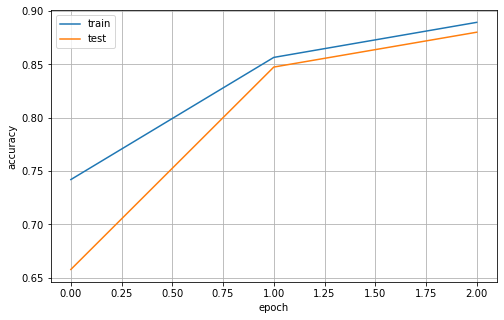
-
git clone
Link:git@github.com:YsYusaito/Multi-in-out-model.git or https://github.com/YsYusaito/Multi-in-out-model.git -
down load data
- access to homepage of CelebA
- click Google Drive

- click img
- download img_align_celeba.zip
- click Anno
- download list_attr_celeba.txt
-
In the folder where this readme is located, extract img_align_celeba.zip. Then you will find the img_align_celeba folder.
-
Create a folder "CelebA_dataset" in the folder where this readme is located.
-
Place list_attr_celeba.txt directly under the folder "CelebA_dataset".
-
Execute preprare_dataset.py The execution of this script creates folders "00_male_smiling", "01_male_Nonsmiling", "10_female_smiling", and "11_female_Nonsmiling" in the folder "CelebA_dataset", which contains images for each class.
-
Execute train_multi_inout_model.py
- model will be output in the folder "model".
※multi_inout_weight.pth → torch.save(model.state_dict(), 'Destination path and save name')
multi_inout_model.pth → torch.save(model, 'Destination path and save name')
about saving models by pytorch
・CelebA_dataset
00_male_smiling
01_male_Nonsmiling
10_female_smiling
11_female_Nonsmiling・img_align_celeba
・model
Execute test_inference.py
If the following log is displayed, success.
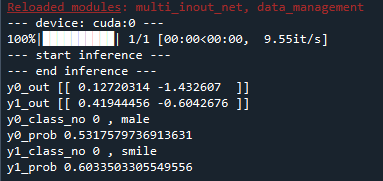
First element of y0_out: score of male
Second element of y0_out: score of femaleFirst element of y1_out: score of smiling
Second element of y1_out: score of non-smiling - model will be output in the folder "model".