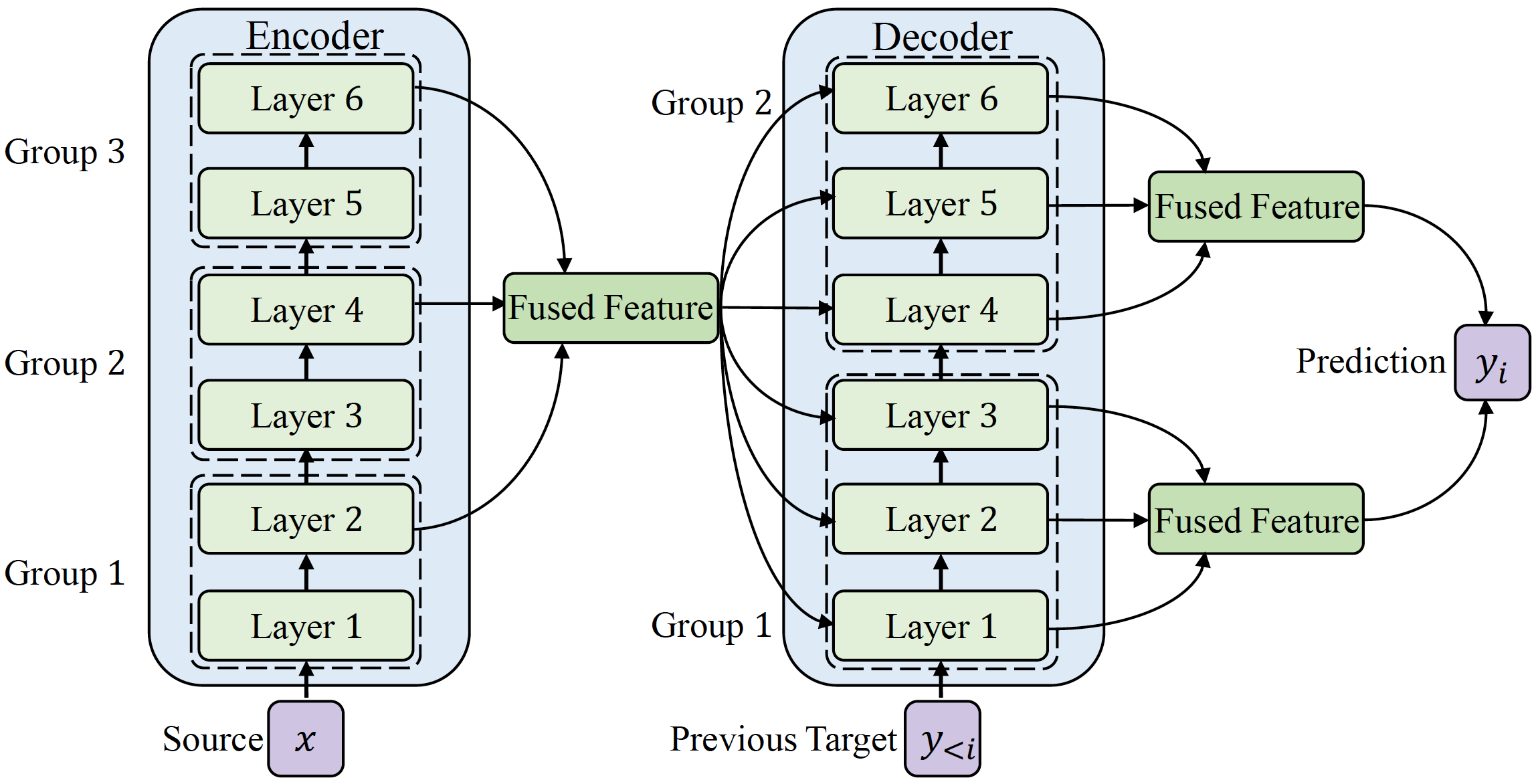
Transformer structure, stacked by a sequence of encoder and decoder network layers, achieves significant development in neural machine translation. However, vanilla Transformer mainly exploits the top-layer representation, assuming the lower layers provide trivial or redundant information and thus ignoring the bottom-layer feature that is potentially valuable. In this work, we propose the Group-Transformer model (GTRANS) that flexibly divides multi-layer representations of both encoder and decoder into different groups and then fuses these group features to generate target words. To corroborate the effectiveness of the proposed method, extensive experiments and analytic experiments are conducted on three bilingual translation benchmarks and two multilingual translation tasks, including the IWLST-14, IWLST-17, LDC, WMT-14 and OPUS- 100 benchmark. Experimental and analytical results demonstrate that our model outperforms its Transformer counterparts by a consistent gain. Furthermore, it can be successfully scaled up to 60 encoder layers and 36 decoder layers.
Keywords: Neural Machine Translation, Deep Transformer, Multi-layer Representation Fusion, Multilingual Translation
- IWSLT-2014
- The training set contains 16K pairs and the valid set contains 7K pairs. The combination of dev2010, dev2012, tst2010, tst2011, tst2012 is used as the test set.
- LDC
- We use a subset of the LDC dataset, containing nearly 1.25M sentence pairs filtered with sentence length limitation rules. We choose NIST-2006 (MT06) as the valid set. And NIST-2002 (MT02), NIST-2003 (MT03), NIST-2004 (MT04), NIST-2005 (MT05), NIST-2008 (MT08), and NIST-2012 (MT12) are adopted as test sets.
- WMT-2014
- The training data contains 4.5M sentence pairs, which are tokenized by Moses and BPE with a shared vocabulary of 40K symbols.
- IWSLT-2017
- we download English (En), German (De), Italian (It), Dutch (Nl), and Romanian (Ro) corpora from the IWSLT-2017 benchmark. All language pairs are tokenized by Moses and jointly byte pair encoded (BPE) with 40K merge operations using a shared vocabulary. We use dev2010 for validation and tst2017 for test.
- OPUS-100
- We use the OPUS-100 corpus for massively multilingual machine translation.
- OPUS-100 is an English-centric multilingual corpus covering 100 languages, which is randomly sampled from the OPUS collection.
- After removing 5 languages without test sets, we have 94 language pairs from and to English.
cd GTrans
pip install --editable ./- For faster training install NVIDIA's apex library:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" \
--global-option="--deprecated_fused_adam" --global-option="--xentropy" \
--global-option="--fast_multihead_attn" ./TEXT=/path/to/data/
MODEL_SAVE_DIR=${1}
mkdir -p ${MODEL_SAVE_DIR}
python train.py ${TEXT} \
--source-lang "en" --target-lang "de" \
--arch "GTrans_base" --variant "transformer" \
--criterion "label_smoothed_cross_entropy" \
--optimizer "adam" --adam-betas '(0.9, 0.98)' \
--lr 0.0005 --lr-scheduler "inverse_sqrt" \
--warmup-updates 4000 --max-update 100000 --max-epoch 100 \
--log-interval 100 --log-format "simple" \
--encoder-layers 60 --encoder-block-layers 6 \
--decoder-layers 36 --decoder-block-layers 6 \
--keep-last-epochs 1 --keep-interval-updates 1 --max-tokens 1024 --keep-best-checkpoints 5 \
--save-interval-updates 10000 --save-interval 1 --save-dir "${MODEL_SAVE_DIR}" \
--label-smoothing 0.1 --dropout 0.3 --update-freq 16 --seed 1 \
--ddp-backend=no_c10d --share-all-embeddings --fp16TEXT=/path/to/data/
NODES=${1}
MAX_TOKENS=${2}
UPDATE_FREQ=${3}
SEED=${4}
MODEL_SAVE_DIR=${5}
MAX_EPOCH=${6}
LR=${7}
WARMUP_STEPS=${8}
WEIGHT_DECAY=${9}
ENCODER_LAYERS=${10}
ENCODER_GROUP_LAYERS=${11}
DECODER_LAYERS=${12}
DECODER_GROUP_LAYERS=${13}
PRETRAINED_ENCODER_MODEL=/path/to/xlmr.base/model.pt
LANGS="af,am,ar,as,az,be,bg,bn,br,bs,ca,cs,cy,da,de,el,en,eo,es,et,eu,fa,fi,fr,fy,ga,gd,gl,gu,ha,he,hi,hr,hu,id,ig,is,it,ja,ka,kk,km,kn,ko,ku,ky,li,lt,lv,mg,mk,ml,mr,ms,mt,my,nb,ne,nl,nn,no,oc,or,pa,pl,ps,pt,ro,ru,rw,se,sh,si,sk,sl,sq,sr,sv,ta,te,tg,th,tk,tr,tt,ug,uk,ur,uz,vi,wa,xh,yi,zh,zu"
LANG_PAIRS="en-af,af-en,en-am,am-en,en-ar,ar-en,en-as,as-en,en-az,az-en,en-be,be-en,en-bg,bg-en,en-bn,bn-en,en-br,br-en,en-bs,bs-en,en-ca,ca-en,en-cs,cs-en,en-cy,cy-en,en-da,da-en,en-de,de-en,en-el,el-en,en-eo,eo-en,en-es,es-en,en-et,et-en,en-eu,eu-en,en-fa,fa-en,en-fi,fi-en,en-fr,fr-en,en-fy,fy-en,en-ga,ga-en,en-gd,gd-en,en-gl,gl-en,en-gu,gu-en,en-ha,ha-en,en-he,he-en,en-hi,hi-en,en-hr,hr-en,en-hu,hu-en,en-id,id-en,en-ig,ig-en,en-is,is-en,en-it,it-en,en-ja,ja-en,en-ka,ka-en,en-kk,kk-en,en-km,km-en,en-kn,kn-en,en-ko,ko-en,en-ku,ku-en,en-ky,ky-en,en-li,li-en,en-lt,lt-en,en-lv,lv-en,en-mg,mg-en,en-mk,mk-en,en-ml,ml-en,en-mr,mr-en,en-ms,ms-en,en-mt,mt-en,en-my,my-en,en-nb,nb-en,en-ne,ne-en,en-nl,nl-en,en-nn,nn-en,en-no,no-en,en-oc,oc-en,en-or,or-en,en-pa,pa-en,en-pl,pl-en,en-ps,ps-en,en-pt,pt-en,en-ro,ro-en,en-ru,ru-en,en-rw,rw-en,en-se,se-en,en-sh,sh-en,en-si,si-en,en-sk,sk-en,en-sl,sl-en,en-sq,sq-en,en-sr,sr-en,en-sv,sv-en,en-ta,ta-en,en-te,te-en,en-tg,tg-en,en-th,th-en,en-tk,tk-en,en-tr,tr-en,en-tt,tt-en,en-ug,ug-en,en-uk,uk-en,en-ur,ur-en,en-uz,uz-en,en-vi,vi-en,en-wa,wa-en,en-xh,xh-en,en-yi,yi-en,en-zh,zh-en,en-zu,zu-en"
GPUS=8
mkdir -p ${MODEL_SAVE_DIR}
python -m torch.distributed.launch \
--nproc_per_node=${GPUS} --nnodes=${NODES} --node_rank=${OMPI_COMM_WORLD_RANK} \
--master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} train.py ${TEXT} \
--save-dir ${MODEL_SAVE_DIR} --arch "GTrans_base" --variant "addffn" \
--task "translation_multi_simple_epoch" --langs ${LANGS} --lang-pairs ${LANG_PAIRS} \
--criterion "label_smoothed_cross_entropy" --label-smoothing 0.1 \
--pretrained-infoxlm-checkpoint ${PRETRAINED_ENCODER_MODEL} \
--init-encoder-only --init-decoder-only \
--sampling-method "linear" --sampling-temperature 5.0 --min-sampling-temperature 1.0 \
--warmup-epoch 5 --warmup-updates ${WARMUP_STEPS} \
--encoder-langtok "tgt" --langtoks '{"main":("tgt",None)}' \
--enable-lang-ids --same-lang-per-batch \
--enable-reservsed-directions-shared-datasets \
--share-all-embeddings --max-source-positions 256 --max-target-positions 256 \
--optimizer "adam" --adam-betas '(0.9, 0.98)' --lr-scheduler "inverse_sqrt" --lr ${LR} \
--max-update 1000000 --max-epoch ${MAX_EPOCH} --max-tokens ${MAX_TOKENS} \
--dropout 0.1 --attention-dropout 0.0 --weight-decay ${WEIGHT_DECAY} --update-freq ${UPDATE_FREQ} \
--encoder-layers ${ENCODER_LAYERS} --decoder-layers ${DECODER_LAYERS} \
--encoder-group-layers ${ENCODER_GROUP_LAYERS} --decoder-group-layers ${DECODER_GROUP_LAYERS} \
--seed ${SEED} --log-format simple --tensorboard-logdir ${MODEL}/log/ \
--truncate-source --ddp-backend=no_c10d \
--skip-invalid-size-inputs-valid-test --fp16 --fp16-init-scale 4 \
2>&1 | tee -a ${MODEL_SAVE_DIR}/train.log- Beam Search: (during the inference) beam size = 8.
- Metrics: BLEU. (BLEU: a Method for Automatic Evaluation of Machine Translation)
TEXT=/path/to/data/
MODEL=MODEL=/path/to/model
GENERATE=/path/to/DeepTransformerModel/DFF-v2/
TRAIN=/path/to/DeepTransformerModel/data/wmt14-en-de/baseline/train/
SRC=en
TGT=de
python ${GENERATE}/generate.py ${TEXT} \
--path ${MODEL}/checkpoint_best.pt \
--source-lang "${SRC}" --target-lang "${TGT}" \
--batch-size 24 --beam 8 --gen-subset "test" --remove-bpe \
--lenpen 0 --min-len 0 --unkpen 0 --no-repeat-ngram-size 4 \
--detoken-output ${TEXT}/result.de --quiet --no-progress-bar
sed "s/-/ - /g" ${TEXT}/result.de | sed "s/ / /g" > ${TRAIN}/result.de.post
sed "s/-/ - /g" ${TRAIN}/test.de-en.de.tok | sed "s/ / /g" > ${TRAIN}/test.de-en.de.tok.post
REF=${TRAIN}/test.de-en.de.tok.post
TRANS=${TRAIN}/result.de.post
perl /path/to/DeepTransformerModel/DFF-v2/scripts/bleu.pl ${REF} < ${TRANS}DATA=/path/to/data/
SPM=/path/to/spm/
TGT=/path/to/opus-100-corpus/supervised/
SPM_MODEL=${TEXT}/sentencepiece.bpe.model
SRC=$1
TGT=$2
BATCH_SIZE=$3
BEAM=$4
LENPEN=$5
MODEL=$6
mkdir -p ${TGT}
if [ -f $TEXT/test.${SRC}-${TGT}.${SRC} ]; then
INPUT=$TEXT/test.${SRC}-${TGT}.${SRC}
FTGT=${TGT}/${SRC}-${TGT}/opus.${SRC}-${TGT}-test.${TGT}
else
INPUT=$TEXT/test.${TGT}-${SRC}.${SRC}
FTGT=${TGT}/${TGT}-${SRC}/opus.${TGT}-${SRC}-test.${TGT}
fi
FOUT=${INPUT}.2${TGT}
cat ${INPUT} | python fairseq_cli/interactive.py ${DATA} \
--path ${MODEL} \
--encoder-langtok "tgt" --langtoks '{"main":("tgt",None)}' \
--task "translation_multi_simple_epoch" \
--langs "af,am,ar,as,az,be,bg,bn,br,bs,ca,cs,cy,da,de,el,en,eo,es,et,eu,fa,fi,fr,fy,ga,gd,gl,gu,ha,he,hi,hr,hu,id,ig,is,it,ja,ka,kk,km,kn,ko,ku,ky,li,lt,lv,mg,mk,ml,mr,ms,mt,my,nb,ne,nl,nn,no,oc,or,pa,pl,ps,pt,ro,ru,rw,se,sh,si,sk,sl,sq,sr,sv,ta,te,tg,th,tk,tr,tt,ug,uk,ur,uz,vi,wa,xh,yi,zh,zu" \
--lang-pairs "es-en,en-es,fr-en,en-fr,ro-en,en-ro,nl-en,en-nl,cs-en,en-cs,el-en,en-el,hu-en,en-hu,pl-en,en-pl,tr-en,en-tr,pt-en,en-pt,bg-en,en-bg,it-en,en-it,fi-en,en-fi,hr-en,en-hr,ar-en,en-ar,sr-en,en-sr,he-en,en-he,de-en,en-de,sl-en,en-sl,ru-en,en-ru,sv-en,en-sv,da-en,en-da,et-en,en-et,bs-en,en-bs,sk-en,en-sk,id-en,en-id,no-en,en-no,fa-en,en-fa,lt-en,en-lt,zh-en,en-zh,lv-en,en-lv,mk-en,en-mk,vi-en,en-vi,th-en,en-th,ja-en,en-ja,sq-en,en-sq,ms-en,en-ms,is-en,en-is,ko-en,en-ko,uk-en,en-uk,ca-en,en-ca,eu-en,en-eu,mt-en,en-mt,gl-en,en-gl,ml-en,en-ml,bn-en,en-bn,pa-en,en-pa,hi-en,en-hi,ta-en,en-ta,si-en,en-si,nb-en,en-nb,nn-en,en-nn,te-en,en-te,gu-en,en-gu,mr-en,en-mr,ne-en,en-ne,kn-en,en-kn,or-en,en-or,as-en,en-as,ka-en,en-ka,be-en,en-be,eo-en,en-eo,cy-en,en-cy,ga-en,en-ga,ug-en,en-ug,az-en,en-az,xh-en,en-xh,af-en,en-af,oc-en,en-oc,br-en,en-br,rw-en,en-rw,km-en,en-km,ku-en,en-ku,wa-en,en-wa,mg-en,en-mg,kk-en,en-kk,tg-en,en-tg,am-en,en-am,ps-en,en-ps,my-en,en-my,uz-en,en-uz,ur-en,en-ur,ky-en,en-ky,gd-en,en-gd,sh-en,en-sh,li-en,en-li,zu-en,en-zu,fy-en,en-fy,tk-en,en-tk,yi-en,en-yi,tt-en,en-tt,se-en,en-se,ha-en,en-ha,ig-en,en-ig" \
--source-lang ${SRC} --target-lang ${TGT} \
--buffer-size 10000 --batch-size ${BATCH_SIZE} --beam ${BEAM} --lenpen ${LENPEN} --truncate-source \
--remove-bpe=sentencepiece --no-progress-bar --fp16 --enable-lang-ids > ${FOUT}.log
BLEU_DIR=/path/to/BLEU/
mkdir -p ${BLEU_DIR}
echo "Saving BLEU to ${BLEU_DIR}/${SRC}-${TGT}.BLEU..."
echo "${MODEL}" | tee -a ${BLEU_DIR}/${SRC}-${TGT}.BLEU
cat ${FOUT}.log | grep -P "^H" | cut -f 3- > ${FOUT}
cat ${FOUT} | sacrebleu -l ${SRC}-${TGT} $FTGT | tee -a ${BLEU_DIR}/${SRC}-${TGT}.BLEU- Pre-norm Transformer with the pre-norm residual unit and Post-norm Transformer with the post-norm residual unit are two Transformer baselines. (Attention is All you Need)
- TA employs transparent attention mechanism to regulate the encoder gradient. (Training Deeper Neural Machine Translation Models with Transparent Attention)
- MLRF fuses all stacked layers for machine translation. (Multi-layer Representation Fusion for Neural Machine Translation)
- DLCL uses the dynamic linear combination and pre-norm techniques to train deeper Transformer. (Learning Deep Transformer Models for Machine Translation)
- ReZero use residual connections to focus on low-level features. (ReZero is All You Need: Fast Convergence at Large Depth)
Evaluation results on the Zh-En translation task with BLEU% metric. The "Avg." column means the averaged result of all NIST test sets except NIST2006. All models consist of 6 encoder and decoder layers.
| Models | MT06 | MT02 | MT03 | MT05 | MT08 | MT12 | Avg. |
|---|---|---|---|---|---|---|---|
| Pre-norm Transformer | 43.03 | 42.97 | 43.86 | 44.05 | 36.07 | 34.73 | 40.34 |
| Post-norm Transformer | 43.52 | 43.17 | 44.06 | 44.45 | 36.27 | 35.07 | 40.60 |
| TA | 44.02 | 43.40 | 44.22 | 44.66 | 36.33 | 35.22 | 41.30 |
| MLRF | 44.94 | 43.88 | 45.70 | 45.25 | 37.54 | 35.80 | 41.63 |
| DLCL | 44.02 | 43.84 | 44.98 | 44.62 | 36.77 | 34.89 | 41.02 |
| ReZero | 43.22 | 43.02 | 45.59 | 43.89 | 35.94 | 34.17 | 40.52 |
| GTrans | 44.48 | 44.02 | 46.54 | 46.33 | 38.22 | 36.42 | 42.31 |
BLEU-4 scores (%) on the IWSLT-2014 De-En task and WMT-2014 En-De translation task. All models consist of 6 encoder and decoder layers.
| Models | De-En | En-De |
|---|---|---|
| Pre-norm Transformer | 34.07 | 28.82 |
| Post-norm Transformer | 34.27 | 29.22 |
| TA | 34.54 | 28.64 |
| MLRF | 34.83 | 29.42 |
| DLCL | 34.40 | 29.42 |
| ReZero | 33.67 | 28.22 |
| GTrans | 35.32 | 30.01 |
BLEU-4 scores (%) on the IWSLT-2014 De-En task. All deep model consist of 12 encoder layers and 12 decoder layers.
| Models | BLEU |
|---|---|
| Pre-norm Transformer | 34.88 |
| Post-norm Transformer | 35.12 |
| TA | 34.80 |
| MLRF | 35.10 |
| DLCL | 34.82 |
| ReZero | 34.04 |
| GTrans | 35.68 |
Evaluation results on the IWSLT-2017 multilingual translation task with BLEU-4 scores (%). All models consist of 6 encoder and decoder layers.
| Models | De-En | En-De | It-En | En-It | Nl-En | En-Nl | Ro-En | En-Ro | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Pret-norm Transformer | 27.44 | 22.63 | 36.87 | 30.28 | 31.54 | 28.86 | 30.45 | 24.14 | 29.03 |
| Post-norm Transformer | 27.78 | 22.93 | 37.07 | 30.68 | 31.86 | 29.16 | 31.02 | 24.69 | 29.39 |
| TA | 27.35 | 24.39 | 36.70 | 32.35 | 32.33 | 30.63 | 32.44 | 26.00 | 30.27 |
| MLRF | 28.62 | 24.11 | 37.62 | 32.65 | 33.14 | 31.10 | 33.09 | 26.93 | 30.91 |
| DLCL | 27.29 | 22.66 | 37.04 | 31.53 | 32.57 | 29.39 | 31.45 | 25.13 | 29.63 |
| ReZero | 27.00 | 21.83 | 36.24 | 31.01 | 31.18 | 29.32 | 30.85 | 23.99 | 29.39 |
| GTrans | 29.61 | 24.94 | 38.99 | 33.37 | 33.63 | 30.96 | 33.35 | 26.57 | 31.43 |
X-En test BLEU for high/medium/low resource language pairs in many-to-many setting on OPUS-100 test sets. The BLEU scores are average across all language pairs in the respective groups. "WR": win ratio (%) compared to "ref" (MNMT).
| Models | #Params | High (45) | Med (21) | Low (28) | Avg (94) | WR |
|---|---|---|---|---|---|---|
| OPUS-100 baseline | 254M | 30.3 | 32.6 | 31.9 | 31.4 | - |
| MNMT | 362M | 32.3 | 35.1 | 35.8 | 33.9 | ref |
| XLM-R | 362M | 33.1 | 35.7 | 36.1 | 34.6 | - |
| GTrans | 362M | 34.0 | 36.5 | 37.0 | 35.5 | 78.5 |
En-X test BLEU for high/medium/low resource language pairs in many-to-many setting on OPUS-100 test sets.
| Models | #Params | High (45) | Med (21) | Low (28) | Avg (94) | WR |
|---|---|---|---|---|---|---|
| OPUS-100 baseline | 254M | 23.7 | 25.6 | 22.2 | 24.0 | - |
| MNMT | 362M | 26.3 | 31.4 | 31.2 | 28.9 | ref |
| XLM-R | 362M | 26.9 | 31.9 | 31.7 | 29.4 | - |
| GTrans | 362M | 27.8 | 32.6 | 32.1 | 30.2 | 77.7 |
Ablation study on the IWSLT-2014 De-En task. "Diverge" indicates that the model failed to train.
| De-En | 12L-12L | 24L-18L | 36L-30L |
|---|---|---|---|
| GTrans | 35.36 | 35.48 | 35.58 |
| GTrans w/o encoder fusion | 35.12 | Diverge | Diverge |
| GTrans w/o decoder fusion | 34.72 | Diverge | Diverge |
| GTrans w/o fusion | 34.22 | Diverge | Diverge |
@article{gtrans,
title = {GTrans: Grouping and Fusing Transformer Layers for Neural Machine Translation},
author = {Yang, Jian and Yin, Yuwei and Yang, Liqun and Ma, Shuming and Huang, Haoyang and Zhang, Dongdong and Wei, Furu and Li, Zhoujun},
journal = {IEEE/ACM Transactions on Audio, Speech, and Language Processing},
pages = {1489-1498},
year = {2023},
volume = {31},
doi = {10.1109/TASLP.2022.3221040},
url = {https://ieeexplore.ieee.org/document/9944969},
}Please refer to the LICENSE file for more details.
If there is any question, feel free to create a GitHub issue or contact us by Email.