| layout | title | date | comments | categories | language | abstract | references |
|---|---|---|---|---|---|---|---|
post |
Fraud Detection with Semi-supervised Learning |
2019-02-13 23:57 |
true |
architecture |
en |
Fraud Detection fights against account takeovers and Botnet attacks during login. Semi-supervised learning has better learning accuracy than unsupervised learning and less time and costs than supervised learning. |
Leveraging user and device data during user login to fight against
- ATO (account takeovers)
- Botnet attacks
ATOs ranking from easy to hard to detect
- from single IP
- from IPs on the same device
- from IPs across the world
- from 100k IPs
- attacks on specific accounts
- phishing and malware
Semi-supervised learning = unlabeled data + small amount of labeled data
Why? better learning accuracy than unsupervised learning + less time and costs than supervised learning
- K-means: not good
- DBSCAN: better. Use labels to
- Tune hyperparameter
- Constrain
Challenges
- Manual feature selection
- Feature evolution in adversarial environment
- Scalability
- No online DBSCAN
Architecture
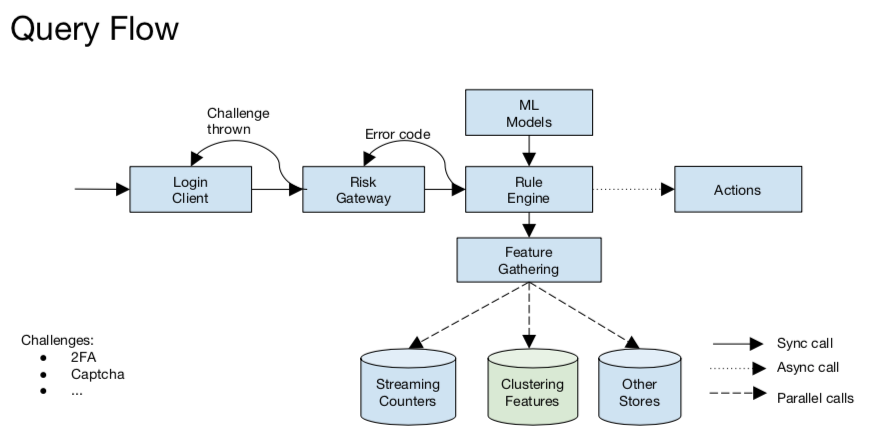
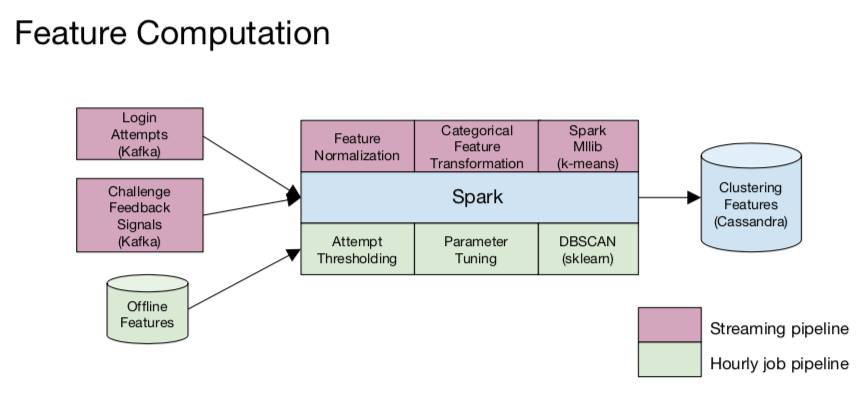
- Batch: 7 days worth of data, run DBSCAN hourly
- Streaming: 60 minutes moving window, run streaming k-means
- Used feedback signal success ratios to mark clusters as good, bad or unknown
- Bad clusters: Always throw
- Good clusters: Small % of attempts
- Unknown clusters: X% of attempts