{kind=link}
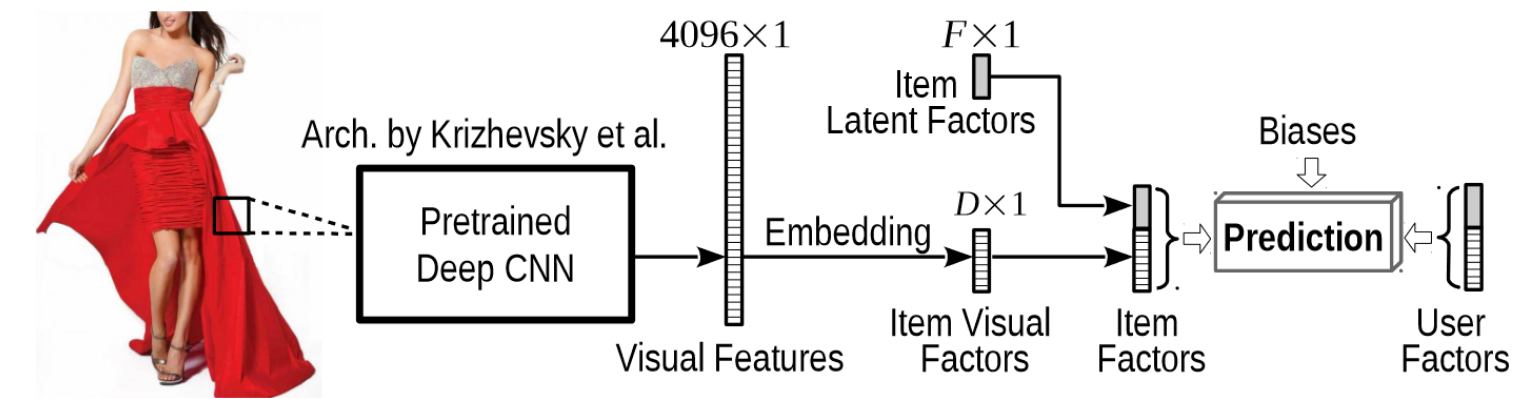
Implementation of VBPR, a visual recommender model, from the paper "VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback".
The implementation has a good enough training time: ~50 seconds per epoch in a regular Google Colab machine (GPU, free) in the Tradesy dataset (+410k interactions, using batch_size=64). Also, the whole source code includes typing annotations that should help to improve readibility and detect unexpected behaviors. Finally, the performance reached by the implementation is similar to the metrics reported in the paper:
| Dataset | Setting | Paper | This repo | % diff. |
|---|---|---|---|---|
| Tradesy | All Items | 0.7834 | 0.7628 | -2.6% |
| Tradesy | Cold Start | 0.7594 | 0.7489 | -1.4% |
@inproceedings{he2016vbpr,
title={VBPR: visual bayesian personalized ranking from implicit feedback},
author={He, Ruining and McAuley, Julian},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
volume={30},
number={1},
year={2016}
}pip install vbpr-pytorch
You can also install vbpr-pytorch with their optional dependencies:
# Development dependencies
pip install vbpr-pytorch[dev]
# Weight and biases dependency
pip install vbpr-pytorch[wandb]
This is a simplified version of the training script on the Tradesy dataset:
import torch
from torch import optim
from vbpr import VBPR, Trainer
from vbpr.datasets import TradesyDataset
dataset, features = TradesyDataset.from_files(
"/path/to/transactions.json.gz",
"/path/to/features.b",
)
model = VBPR(
dataset.n_users,
dataset.n_items,
torch.tensor(features),
dim_gamma=20,
dim_theta=20,
)
optimizer = optim.SGD(model.parameters(), lr=5e-04)
trainer = Trainer(model, optimizer)
trainer.fit(dataset, n_epochs=10)You can use a custom dataset by writing a subclass of TradesyDataset or making sure the the __getitem__ method of your dataset returns a tuple containing: user ID, positive item ID, and negative item ID.
Notice that the original VBPR implementation (available at He's website) contains a different regularization than the one used in this implementation. The authors update the gamma_items embedding in a stronger way for positive than for negative items (dividing the lambda by 10). Notice that Cornac applies this regularization in their implementation (code). In this implementation, it was not considered because it is hard to do without having to manually calculate the regularization as Cornac (I am prioritizing simplicity and portability of the implementation) or without having to use a custom loss that includes the regularization term (a future version might do this). In the future, I will implement the authors' regularization to check if the results change significantly, but it might not be significant (I assume this regularization was not included in the paper for a reason).
Relevant code:
// adjust latent factors
for (int f = 0; f < K; f ++) {
double w_uf = gamma_user[user_id][f];
double h_if = gamma_item[pos_item_id][f];
double h_jf = gamma_item[neg_item_id][f];
gamma_user[user_id][f] += learn_rate * ( deri * (h_if - h_jf) - lambda * w_uf);
gamma_item[pos_item_id][f] += learn_rate * ( deri * w_uf - lambda * h_if);
gamma_item[neg_item_id][f] += learn_rate * (-deri * w_uf - lambda / 10.0 * h_jf);
}