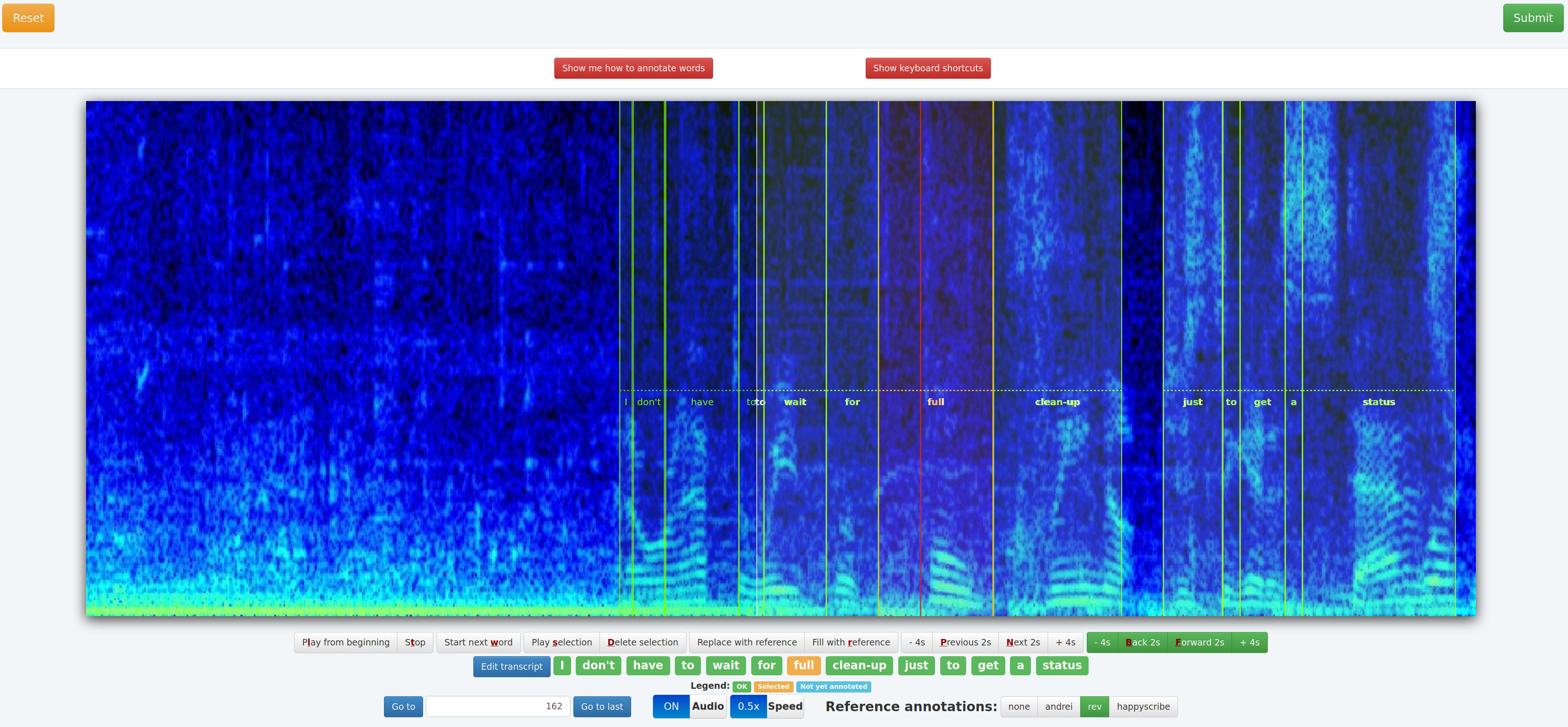
Annotate audio on the web. Collects transcripts and word onsets/offsets by annotating spectrograms.
{kind=link}
First you need to install some dependencies and initialize some secret keys (don't reuse these).
make install
echo 'ASECRET' > session-secret
echo 'BSECRET' > segment-key
After that in separate screen or tmux windows you will need to start 3 servers, in this order:
This starts the database (Note that we use a local custom redis on a custom port)
make start-redis
This starts the monitor which records user actions:
make start-telemetry-server
This starts the audio gui itself:
make start-server
We assume that your data
To import a movie run:
python toolkit.py import-movie /storage/datasets/video/lotr-1.mp4 lotr-1
python toolkit.py process-movie --movie-start=0 lotr-1 4
python toolkit.py process-movie --movie-start=2 lotr-1 4
This will generate 4 second-long segments starting that offset 0 and offset 2. If you want annotators to see shorter or longer segments you can change the parameters, as well as if you want them to have random access to other offsets. With 0 and 2 at length 4, only even timestamps will be accessible. You could generate 1 and 3 to make all offsets in the movie (rounded to a second) accessible. The GUI is nominally designed to work in offsets of 2 and 4 seconds, but this is simple to change.
If you have existing annotations you can import them to serve as a reference. You should store those annotations in a csv file which contains columns "start", "end", and "text". It can contain other columns as well but they will be ignored. "start" and "end" should be in seconds since the start of your movie file. "text" should contain a word.
python toolkit.py import-annotation /storage/datasets/transcripts/word-times-rev.csv lotr-1 rev
python toolkit.py process-annotation lotr-1 rev
There's no difference between data you load this way and data that is annotated by any other user.
Point annotators to:
lotr-1 is the movie name. 00048 and 00052 is the position in the movie. From second 48 to second 52. You want the difference between these two numbers to be the same as whatever data you generated above (4 in this case, and since we generated data at offset 0 and 2, 00048 should be even). If you go to a segment that doesn't exist, the UI will have a broken link and sit there hoping to load the audio.
You can set the worker id and provide any reference annotations that you want. Note that in this mode, the tool is designed to be cooperative: any worker can view any segment and change their worker id as well as inspect any reference annotation.
The two buttons will walk you through how the UI works.
The simplest way to do this is to extract a json file out of redis. Run pip install rdbtools python-lzf
python toolkit.py export-all-annotations
Will give you a dump.json file.