This repository contains an updated code version, related to my diploma thesis "Automated Audio Source Extraction From Recordings Using Deep Neural Networks"(in Greek) supervised by prof. Nikolaos Mitianoudis. This repo covers the case of Singing Voice Separation problem. The main difference between this and my initial implementation is the creation of the dataset. For the initial implementation I used h5py library to create a static dataset, whereas here I present a method to randomly generate data. For the initial implementation check "Old Thesis Code" folder.
For this implementation I used Tensorflow v2.4.1 and Keras Functional API.
Here are some output examples extracted using my method. The music tracks are the following
Ιουλία Καραπατάκη - Μπιρ Αλλάχ (exact time interval 90-120 sec.) - Vocals - Accompaniment
Villagers of Ioannina City - Perdikomata (exact time interval 360-390 sec.) - Vocals - Accompaniment
Boston - More Than A Feeling (exact time interval 45-75 sec.) - Vocals - Accompaniment
Porcupine Tree - Trains (exact time interval 70-100 sec.) - Vocals - Accompaniment
TCTS - Not Ready For Love (feat. Maya B) (exact time interval 30-60 sec) - Vocals - Accompaniment
Note that the current pre-trained model is not fully optimized yet. It can be further improved and lead to better results.
Use Python 3.8 interpreter in order to get Librosa version 8.0 library work smoothly. Use the package manager pip to install the following packages. See "requirements.txt" for the exact package versions.
pip install -Iv tensorflow-gpu==2.4.1
pip install -Iv librosa==0.8
pip install -Iv numpy==1.20.1
pip install -Iv musdb==0.40.0An easier approach is to use Anaconda environment. If you use Anaconda, install the following
conda install -c conda-forge librosa
conda install -c conda-forge ffmpeg
conda install -c conda-forge musdb
conda install -c anaconda tensorflow-gpu First, you have to download MUSDB18 dataset. I used the predefined split, 84 tracks for training and 16 tracks for validation.
This method borrows much from these two papers 1, 2.
I randomly cut 30 second chunks, downsample to 22.05kHz and apply Short Time Fourier Transform to time domain signals. Then I feed the model with 9 overlapping magnitude spectograms. Their overlap is 1 frame. Also, I random mixing channels and batches for data augmentation and better generalization overall.
2D Convolutional layers with (3x12) kernels are used for feature extraction. Max Pooling layers for downsampling the frequency dimension(a process similar to MFCCs extraction). Dropout layers and Early Stopping for regularization and Dense layers, which have been successfully used for audio source separation. The output is a soft mask, thus the final layer is activated by a sigmoid function.
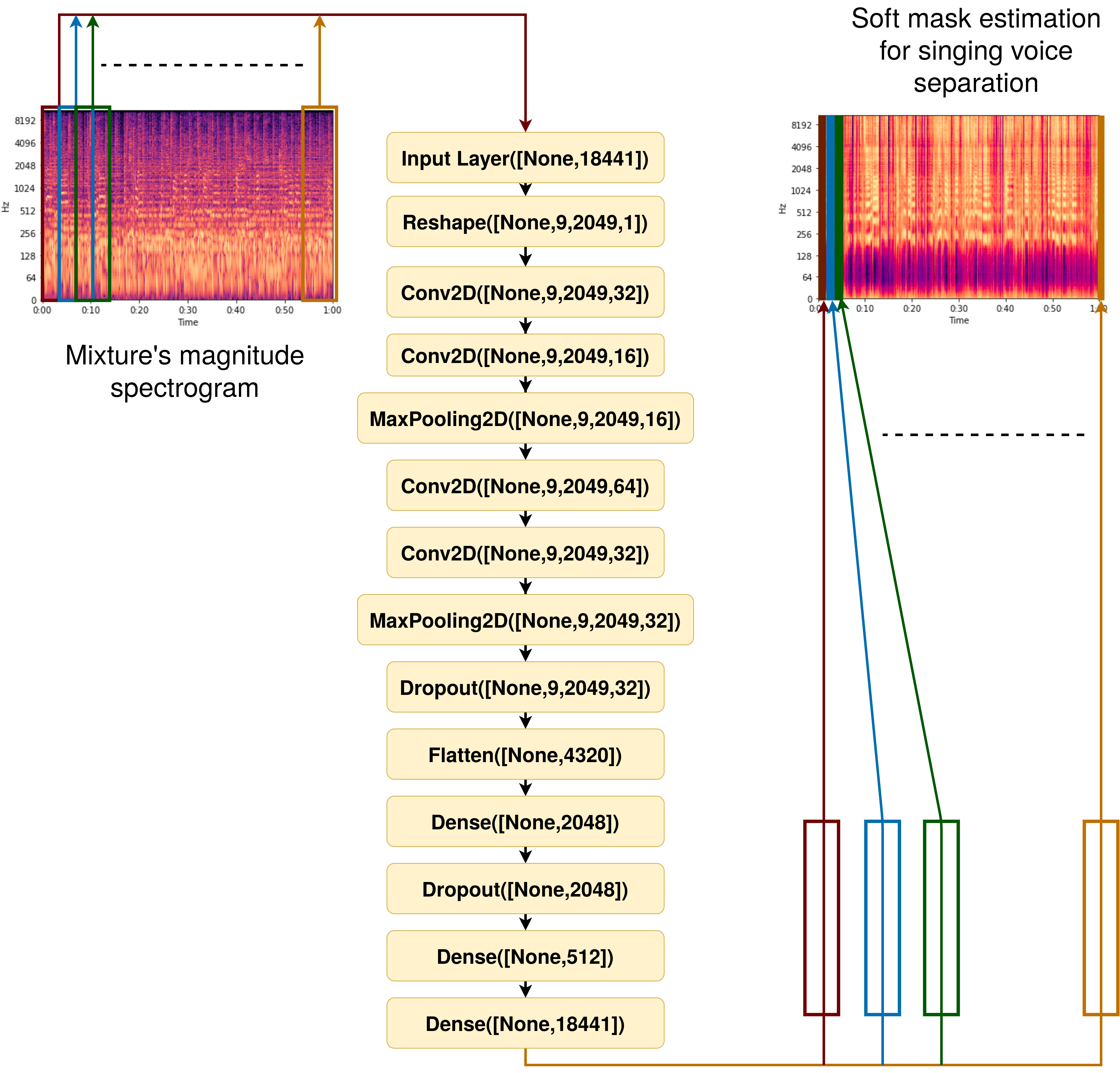
The model is trained to minimize the binary cross-entropy of between the ideal binary mask and the model's predictions formed by the sigmoid function of the final layer, in the time-frequency domain for the validation set. The ideal binary mask is created by comparing mixture's and vocals' magnitude spectrograms.
Reconstruction of the 9 spectrogram frames, application of the estimated soft masks to magnitude spectrogram and element-wise multiplication(Hadamard product) with the original phase. Thresholds are applied to vocal and accompaniment soft masks to further improve separation. I recommend 0.1-0.2 for vocals and 0.75-0.85 for accompaniment, depending on track. Then I apply inverse Short Time Fourier Transform to reconstruct the signals to time domain, and upsample to 44.1kHz.
In Google Colaboratory jupyter notebook "postprocessing_yt_no_out.ipynb", in "Estimating soft masks" section, I have commented out the following
......
# Estimating soft masks
vocals_soft_mask = np.zeros((freq_bins, time_bins))
# predictions = model.predict(input)
for i in range(time_bins):
temp_soft_mask = np.transpose(np.reshape(model.predict(input[i:i+1,:]), (num_frames, freq_bins)))
# temp_soft_mask = np.transpose(np.reshape(predictions[i,:],(num_frames, freq_bins)))
......This is slower method, but is useful when trying to source separate tracks with over 30 sec. duration, because the process then becomes more memory intense. The faster equivalent method is to comment and uncomment the following lines(in the same section)
......
# Estimating soft masks
vocals_soft_mask = np.zeros((freq_bins, time_bins))
predictions = model.predict(input)
for i in range(time_bins):
# temp_soft_mask = np.transpose(np.reshape(model.predict(input[i:i+1,:]), (num_frames, freq_bins)))
temp_soft_mask = np.transpose(np.reshape(predictions[i,:],(num_frames, freq_bins)))
......This works well and fast for small durations, with the same results, but it will probably run your system out of memory for tracks with over 30 sec. duration.
To execute the code you should have a GPU with at least 12GB memory , e.g. NVIDIA TITAN Xp. The related code is in "Python" folder. When training a model, the code assumes that the data is stored as .stem.mp4 files with folder structure ../Dataset/musdb18/train/source.stem.mp4 and ../Dataset/musdb18/test/source.stem.mp4.
To train model run
python train.pyUse "batch_size" parameter according to your memory restrictions.
I mostly worked my diploma thesis using Google Colaboratory. You can find the related code in "Google Colaboratory" folder. You can separate tracks from YouTube using youtube-dl. I recommend to save MUSDB18 dataset to your Google Drive, then mount it
from google.colab import drive
drive.mount('/gdrive')and copy MUSDB18 dataset to the root of Colab's virtual machine
!gsutil -m cp -r "path-to-musdb18-on-gdrive" "/root"Currently if you have a pro subscription at Google Colaboratory, you will be able to train your model up to 24 hours without disconnecting, whereas for users without pro subscription the limit is 6 hours. You should save your model after each epoch on Google Drive using the following Keras Callback
checkpoint_path = "your-model-saving-path-to-gdrive/model.h5"
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, monitor='val_binary_crossentropy',verbose=1, save_best_only=True, mode='min')Use "steps_per_epoch" parameter according to the training time limit.
Generally, when using a GPU, selecting batch size as power of 2, leads to better execution times. Furthermore bigger batch sizes can lead to better gradient estimation. I recommend to select a power of 2 batch size number between 8-512, according to your memory restrictions.
When loading a model with
model = tf.keras.models.load_model("path-to-model", compile=False)the Tensorflow versions should match, i.e. if you use Tensorflow v2.4.1 when training the model and try to load model using Tensorflow v2.2. you will possibly get an error. At publishing time, model was created with Tensorflow v2.4.1.
This repository borrows many ideas from the following CNN-with-IBM-for-Singing-Voice-Separation and blind-audio-source-separation-cnn