Sparkify, the hot music streaming startup, looking to improve its product, service and analytics has decided to introduce more automation and monitoring to their data warehouse ETL pipelines, with an eye on the data warehouse quality assessment.
The company stores a collection of complex data and metadata from Sparkify Application in Amazon S3 that needs to be processed in Amazon Redshift.
As data engineers we have been asked to create high grade data pipelines that are dynamic and built from reusable tasks, can be monitored, and allow easy backfills. For this job we have adopted Apache Airflow.
To build the Redshift cluster for data warehousing we have used Python (Boto3); using SQL we have created the staging and final tables (star-schema); using Airflow we have architected and orchestrated the data pipeline from the S3 buckets passing by the staging area until the production area.
For the sake of this project the data and metadata under processing is part of the Million Song Dataset1 - the song dataset contains metadata about songs and artists. The log dataset holds log files about users activity and was generated by the program eventsim.
sparkify-airflow
| .gitignore # Config file for Git
| docker-compose.yml # Airflow container definition
| dwh.cfg # Data warehousing configuration parameters
| README.md # Repository description
| requirements.txt # Libraries required
| setup_cluster.py # AWS services definition
|
└--airflow
|
└--dags
| create_atbles_dag.py # DAG to create staging & production tables
| sparkify_dag.py # DAG to do etl (S3 to Redshift) & data validation
|
└--plugins
|
└--helpers
| create_tables.py # SQL statements to create tables
| sql_queries.py # SQL statements to transform data
|
└--operators
| data_quality.py # DataQualityOperator
| load_dimension.py # LoadDimensionOperator
| load_fact.py # LoadFactOperator
| stage_redshift.py # StageToRedshiftOperator
|
└--graphics
| conn_cred.png # AWS connection credentials
| conn_redshift.png # Redshift connection parameters
| DAG_1_2.png # DAGs status
| DAG_1_details.png # DAG details (create tables)
| DAG_2_details.png # DAG details (etl & data validation)
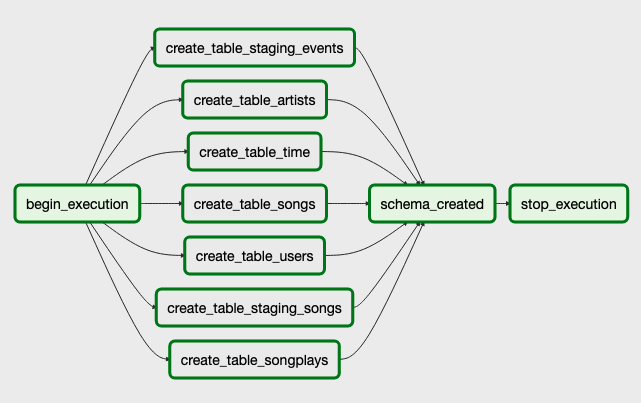
| DAG_1_diagram.png # DAG diagram (create tables)
| DAG_2_diagram.png # DAG diagram (etl & data validation)
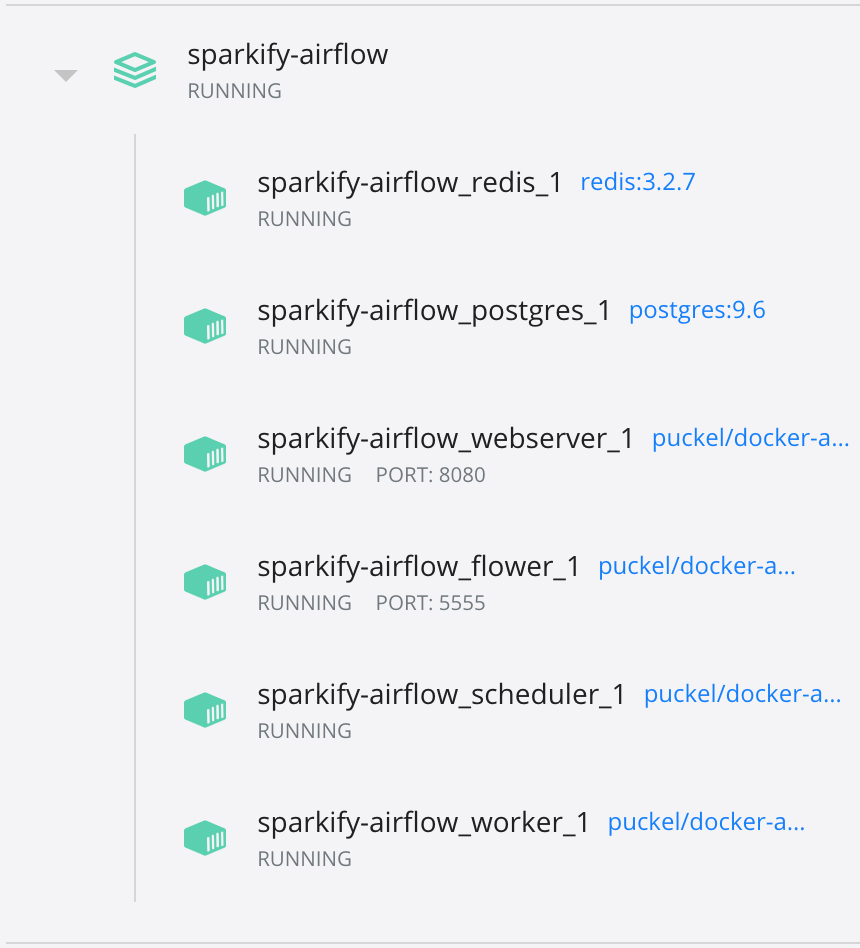
| docker_services.png # Docker services
| stag_prod_tables.png # Staging & production tables (Redshift)
DAG parameters:
- No dependencies on past runs
- On failure retry 3 times
- Retry every 5 min
- Email off
- Catchup off
DAG OPERATORS:
-
CREATE TABLE OPERATOR: Operator (PostgresOperator) creates all tables in Redshift using SQL helper statements (sql_queries.py file).
-
STAGE OPERATOR: Operator (StageToRedshiftOperator) loads any JSON files from S3 to Redshift; operator creates and runs SQL COPY statement based on parameters provided; operator parameters specify where in S3 the file is loaded and what is the target table; t the parameters should be used to distinguish between JSON file; another important requirement of the stage operator is containing a templated field that allows it to load timestamped files from S3 based on the execution time and run backfills.
-
FACT and DIMENSION OPERATOR: Operator (LoadFactOperator and LoadDimensionOperator) run data transformations using logic in SQL statements (sql_queries.py). Dimension operator has the option to use a truncate/insert or append mode; Fact operator has only the option to use append.
-
DATA QUALITY OPERATOR: Operator (DataQualityOperator) runs checks on the data itself; operator main functionality is to receive 1+ SQL based test cases along with the expected results and execute the tests; for each test, the test result and expected result needs to be checked, if there is no match, the operator should raise an exception, and the task should retry and fail eventually; in this task was implemented a list of checks (e.g.
{"check_sql": "SELECT COUNT(*) FROM songplays WHERE playid is null", "expected_result": 0}) to test if production tables are populated (not empty).
Illustration of DAGs (1 - ahead DAG, 2 - main DAG) with tasks and dependencies:

Tables in Redshift to store LOG and SONG data from JSON files stored in S3 (s3://udacity-dend/log_data & s3://udacity-dend/song_data).

- Clone this project, and to up and running it locally go to its directory (local machine) and create a virtual environment (venv), activate it and install the requirements.txt.
$ python3 -m venv /path/to/new/venv
$ source venv/bin/activate
$ pip install -r requirements.txt
- Start Airflow container (Docker). Docker image source of docker-compose.yml: https://hub.docker.com/r/puckel/docker-airflow & https://github.com/puckel/docker-airflow
$ docker-compose up
- Setup & launch AWS services:
Note: Using AWS services create an IAM user (with administrator privileges) and add its security credential values (ACCESS & SECRET KEYS) to the Redshift configuration file: dwh.cfg.
$ setup_cluster.py # launches Redshift
Running setup_cluster.py the data warehouse where tables will be stored is launched (dwh.cfg parameters are updated).
- Render Airflow UI:
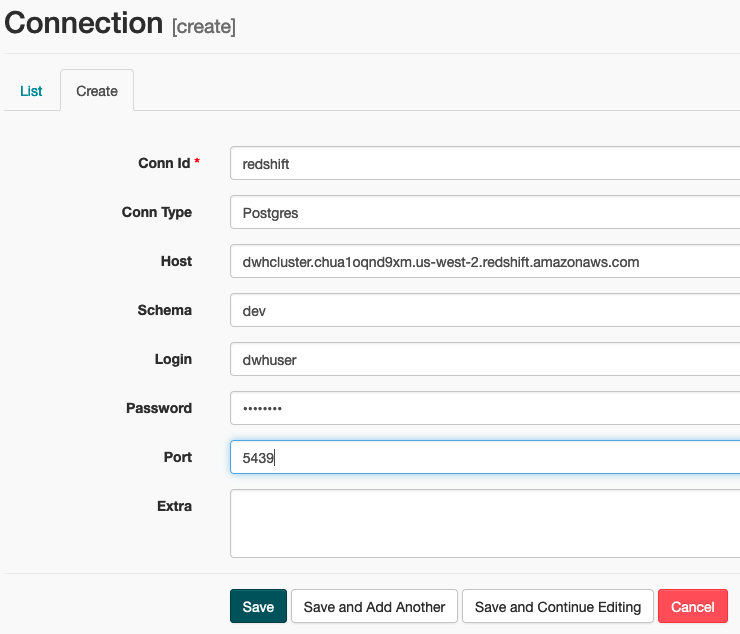
- Connect to AWS:
On Airflow UI > Connections > Create. Enter the parameters with Login & Password being the ACCESS & SECRET KEYS defined in AWS, and then select Save and Add Another.

Enter the parameters being Host the Redshift cluster ENDPOINT and the Login & Password the user & password defined in the cluster parameters, and then select Save.
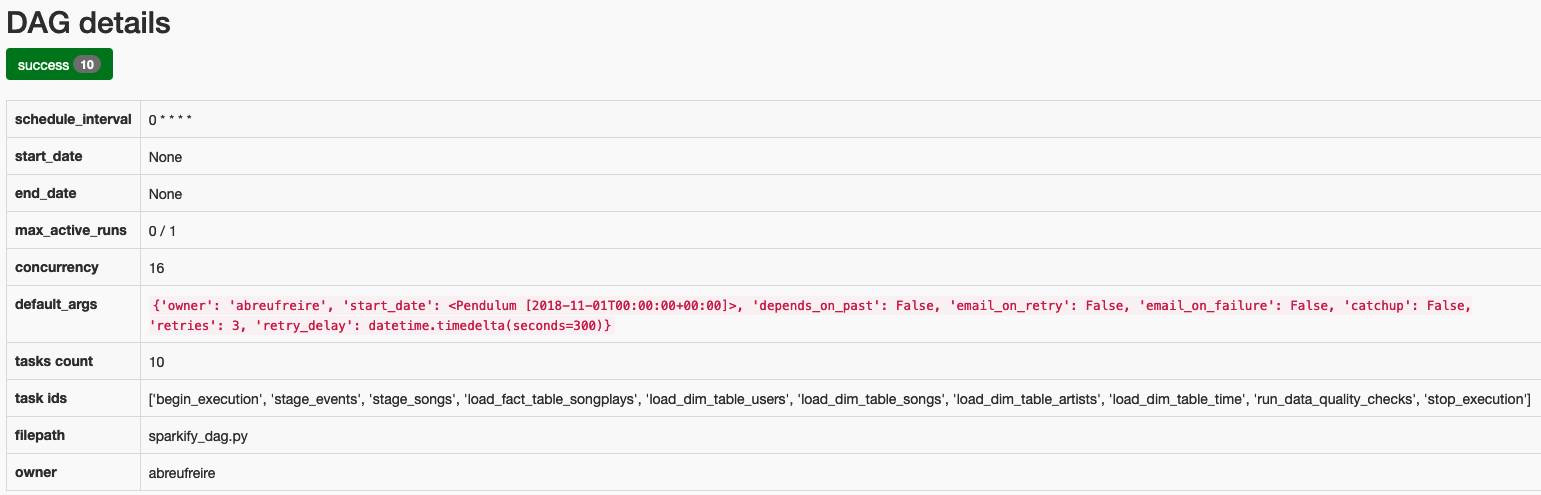
- Start/turn ON the DAGs:
- 6.1 create_tables_dag
- 6.2 etl_dag

Refresh DAG status and monitor the tasks being performed. The images present DAG tree view and details.

-
Stop & clean (docker-compose down) the Airflow container.
-
Delete AWS services (when job is done).
Docker services running with Airflow: