A novel feature selection technique for text data using Term-Term correlation based on clusters generated using the Fuzzy C-Means (FCM) Algorithm
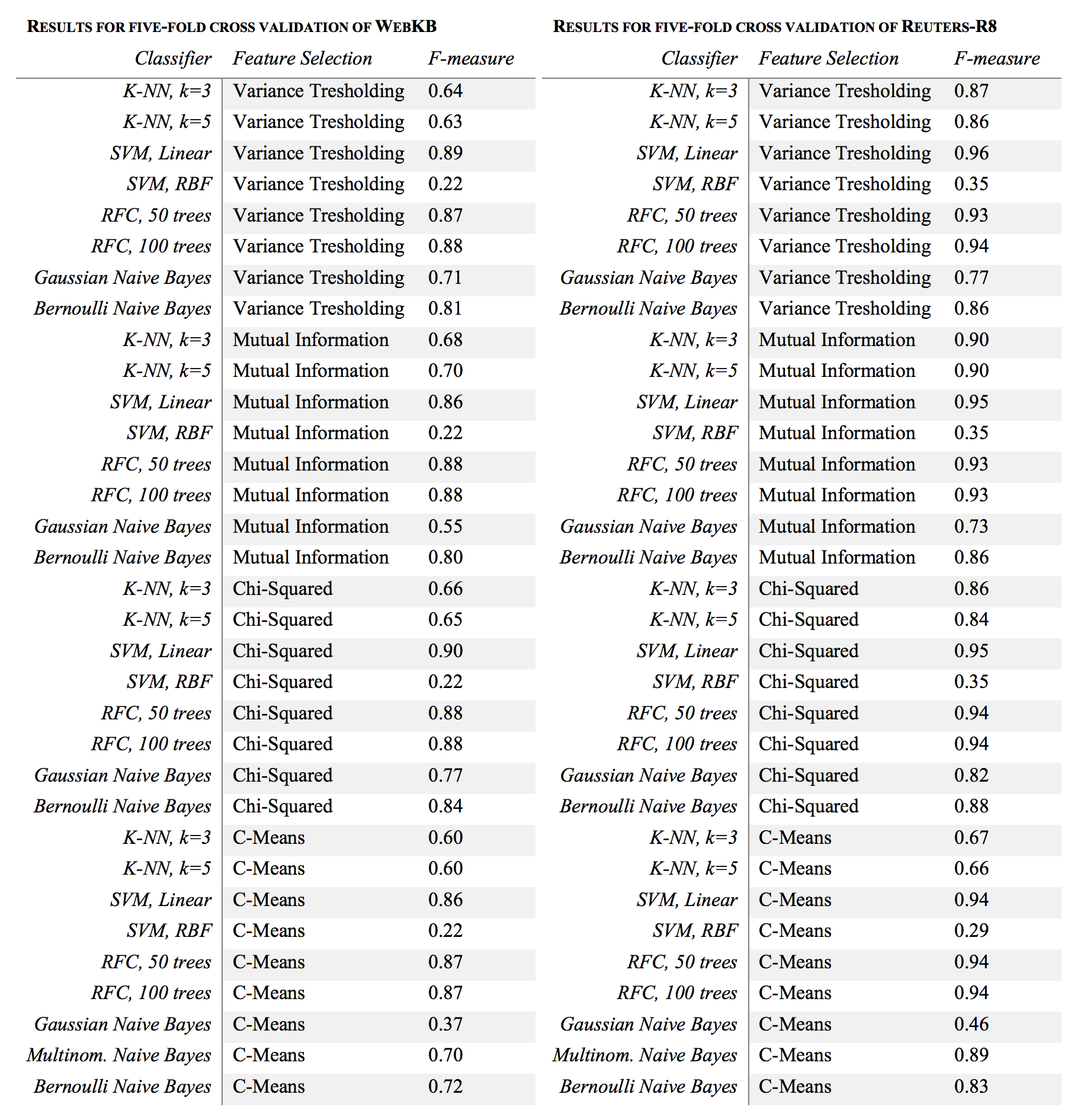
Top ‘k’ features are selected from these datasets using cosine similarity scores on the semantic centroids calculated from the normalized correlation factors. We attempt to show that the features selected through this mechanism shall result in comparable F-measures for classification tasks in comparison to more traditional feature selection techniques like Chi-Squared, Mutual Information and Variance Thresholding. We also intend to show that this feature selection technique is more robust with a lower reduction in F-measure with a given reduction in the number of top features chosen vis-a-vis the other approaches and thus, the resulting lower classification time, to an extent, makes up for the increased feature selection time.
The implementation made use of the classifiers and feature selection algorithms implemented in the Scikit-learn library for Python, and Scikit-fuzzy package was used for the FCM algorithm. Stopword removal, Snowball Stemmer and WordNet Lemmatizer from the NLTK library were used to preprocess the corpora. The computation of the CF matrix is highly time consuming and hence to perform the computations and store the intermediate results, the popular Numpy package was used. The Pandas package provided the necessary utilities for reading and storing the pre-processed text data
Run baseline_knn_chi2_webKB.py files to get an estimate of the baseline KNN performance on WebKB with Chi2 feature selection. Similarly for other feature selection techniques and datasets. The following scripts need to be run sequentially:
- Run generate_cf_matrix_webKB.py to generate the CF matrix for the Reuters-R8 dataset.
- Next run the feature_selection_using_cmeans.py to select and save the features from the previously generated CF matrix.
- Finally, run classification_with_novel_features.py to get the F-measures.
- Similarly follow for Reuters-R8 dataset.
When contributing to this repository, please first discuss the change you wish to make via issue, email, or any other method with the owners of this repository before making a change. Ensure any install or build dependencies are removed before the end of the layer when doing a build. Update the README.md with details of changes to the interface, this includes new environment variables, exposed ports, useful file locations and container parameters.
This project is licensed under the MIT License - see the LICENSE.md file for details
I thank Rajendra Roul for his guidance and the ideas implemented in this project. I worked with a few others to finish the work and would like to mention George Joseph and Shobhik Bhadraray for their contributions.