CO: szybkie i podstawowe przejście przez kagglowy zbiór danych Titanic - podobno najpierwszy i najlepszy start dla wszystkich chcących ogarnąć Machine Learning. Jeśli szukasz czegoś bardziej skomplikowanego, zajrzyj do części rozszerzonej
PO CO: żebym w końcu miała w jednym miejscu skrót procesu myślowego, który zaszedł w trakcie pracy nad zbiorem. Plus to taki mój mały pamiętniczek, zmusza mnie do myślenia, sprawdzania pojęć, definicji. Więc po co - totalnie dla mnie ;)
DLACZEGO PO POLSKU: bo tutoriali w języku angielskim na temat Titanica jest już milion pięćset sto dziewięćset, a polskich prawie wcale
Co jest ważne?
- warto połączyć zbiór treningowy z testowym, żeby zwiększyć ilość danych.
- model ML nie przyjmie danych z brakami - jeśli dane mają braki, należy się ich pozbyć (usunąć lub uzupełnić, wedle uznania)
- model ML przyjmuje jedynie dane liczbowe - jeśli dane mają inną formę (na przykład kolor), należy je przerobić
- przed przystąpieniem do tworzenia modelu dobrze jest przeanalizować dane i użyć zdrowego rozsądku oraz intelektu (niestety)
- Wczytać dane, połączyć zbiory i rzucić na nie okiem.
- Ogarnąć kontekst historyczno-kulturowy.
- Przygotować/wyczyścić dane.
- Stworzyć model i sprawdzić jego skuteczność.
- Wgrać wynik do Kaggle.
#import danych treningowych
df_train = pd.read_csv("./train.csv")
#import danych testowych
df_test = pd.read_csv("./test.csv")
# połączenie zbiorów
df = df_train.append(df_test, ignore_index=True, sort=True)
df.head(5)

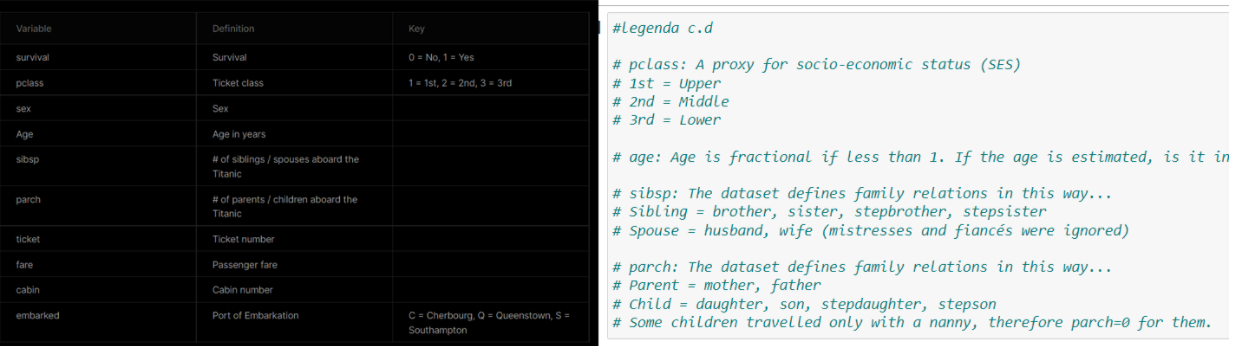
Legenda:
Dobrze jest mieć szerszy wgląd w sytuację i dane, które analizujemy. Tutaj ważniejsze fragmenty artykułu z Wikipedii:
"RMS Titanic – brytyjski transatlantyk typu Olympic, który w nocy z 14 na 15 kwietnia 1912 roku, podczas dziewiczego rejsu na trasie Southampton – Cherbourg – Queenstown – Nowy Jork, zderzył się z górą lodową i zatonął.
Dane o ofiarach są niejednoznaczne – w zależności od źródeł. Spośród 2208–2228 pasażerów i załogi „Titanica” zginęło ponad 1500 osób. Przeżyło katastrofę tylko około 730. Z pasażerów I klasy zginęło nieco mniej niż połowa, z pasażerów II klasy około 60%, z pasażerów III klasy trzy czwarte. Załogi zginęło prawie 80%.
W łodziach „Titanica” było miejsce dla ponad 1100 osób, ale wiele z nich było częściowo pustych. Zwłaszcza w pierwszej fazie ewakuacji łodzie odpływały z niewielką liczbą osób. Dopiero w dalszej fazie wypadku łodzie odpływały pełne. Nie podjęto niemal żadnej próby ratowania osób, które znalazły się w wodzie. Jedynie piąty oficer, Harold Lowe, rozdzielił pasażerów ze swej łodzi między inne łodzie i popłynął wydobywać z wody tych, którzy pływali w morzu, ale zrobił to zbyt późno i ocalił tylko kilka osób."
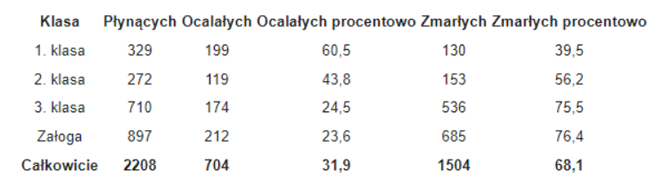
Po co dorzucam suche fakty z Wiki? Żebyśmy mogli mieć punkt odniesienia. Porównajmy dane z informacjami. Nasz zbiór zawiera 891 wierszy, czyli 40% pasażerów podróżujących Titanikiem. W naszym zbiorze członków brak załogi (informacja potwierdzona, po prostu zbiór ich nie zawiera).
Jednym z problemów, z jakimi mierzymy się w świecie data science, są brakujące dane. Sposobów na radzenie sobie z nim jest kilka i trzeba nimi żonglować w zależności od sytuacji. Jaki więc mamy wybór?
- usunąć wiersze z brakującymi wartościami. Jeśli wierszy mamy dużo, te, w których występują brakujące wartości nie są wyjątkowe i niewiele stracimy, możemy je usunąć
- usunąć kolumny z brakującymi wartościami. Jeśli wiemy, że dana kolumna nie będzie brała udziału w analizie (bo nie ma związku i wpływu na przewidywaną przez nas cechę), możemy ją porzucić
- uzupełnić kolumny byle jaką wartością liczbową. Cokolwiek (na przykład 0) bardziej się spodoba modelowi niż brak wartości. Czasami to nie ma wpływu na wynik, czasami jeśli nam się spieszy i chcemy po prostu mieć działający (nie mówię, że dobrze działający) model, można skorzystać z tej metody.
- uzupełnić wiersze własnymi wartościami używając zdrowego rozsądku. Na przykład:
- jeśli posiadamy kolumnę pełną 0 i 1, w której brakuje wartości, możemy wpisać w brakujące miejsca same 0, lub same 1. Jest to o tyle zdroworozsądkowe, że w kolumnie występują 0 i 1 (nie wpisujemy 3jek), ale o tyle małorozsądkowe, że nasza bonusowa liczba 0 lub 1 może zmienić wynik końcowy. Możemy więc wejść na wyższy poziom zdrowego rozsądku, sprawdzić stosunek 0 do 1 i wpisać odpowiednio w brakujące miejsca od góry najpierw pewną liczbę 0 , a potem pewną liczbę 1 odpowiadającą stosunkowi w całej kolumnie. Czyli jeśli mamy 90 wierszy, w których jest 60 zer i 20 jedynek, oraz 10 brakującyh pól, to wpisujemy tam 7 zer i 3 jedynki.
- jeśli mamy kolumnę zawierającą czyjś wiek ( a to się za chwilę wydarzy), to w brakujące miejsca możemy: wpisać dowolną wartość z zakresu długości ludzkiego życia (zdrowy rozsądek podpowiada, żeby to nie było -4 albo 236). Na przykład 2 (bo dlaczego nie 2). Możemy też sprawdzić, jaki jest średni wiek wszystkich ludzi w zbiorze. Albo mediana wieku. Albo możemy sprawdzić, jaki jest rozkład odpowiednich grup wiekowych i na tej podstawie uzupełnić pola tak, żeby stosunek poszczególnych grup (dzieci, nastolatkowie, dorośli, emeryci) został zachowany.
Zatem do dzieła. Gdzie brakuje nam danych?
# brakujące wartości
df.isnull().sum()

Nie jest źle. Zacznijmy od najmniejszego problemu, czyli brakującej dla 1 osoby informacji o cenie biletu. Uzupełnijmy ten drobny brak średnią ceną wszystkich biletów:
df.loc[df['Fare'].isnull(), 'Fare'] = 14.435422
Rozwiązaliśmy problem BRAKUJĄCEJ wartości. Ale kiedy przyjrzymy się kolumnie Fare, dostrzeżemy, że zawiera ona również zera.

Czy to możliwe, żeby ktoś nie zapłacił za bilet? Dostał go w prezencie? Nie, encyklopedia Titanica o niczym takim nie wspomina. Wyliczymy więc średnią cenę biletu dla każdej klasy i portu zaokrętowania i w ten sposób wypełnimy zera. Oczywiście można by to również zastosować do brakującej wartości powyżej - obydwie metody są tak samo skuteczne.
fare_means = df.groupby(['Embarked', 'Pclass'])['Fare'].mean().reset_index()
def find_fare(embarked, pclass):
fare = fare_means[(fare_means['Embarked'] == embarked) & (fare_means['Pclass'] == pclass)]['Fare'].values[0]
return(fare)
df['Fare'] = df.apply(lambda x: find_fare(x.Embarked, x.Pclass) if x.Fare == 0 else x.Fare, axis=1)
Następnie mamy dla 2 osób brak informacji o porcie zaokrętowania. Podglądnijmy te 2 wiersze:
df[df['Embarked'].isnull()]

Widzimy, że te dwie podróżne mieszkały w jednej kabinie. Być może płynęły z kimś jeszcze, kto mieszkał w tej samej kabinie i posiada informację o porcie, w którym wsiedli?
df[df['Cabin'] == "B28"]

Niestety nie. Skorzystajmy więc po prostu z potęgi internetu, wpiszmy w wyszukiwarkę imię i nazwisko pasażerki:
Miss Rose Amélie Icard, 38, was born in Vaucluse, France on 31 October 1872, her father Marc Icard lived at Mafs á Murs (?). She boarded the Titanic at Southampton as maid to Mrs George Nelson Stone. She travelled on Mrs Stone's ticket (#113572).
Problem rozwiązany, dorzucamy 'S' w brakujące miejsca:
df.loc[df['Embarked'].isnull(), 'Embarked'] = 'S'
Braków w kolumnie Wiek i Kabina mamy dużo, a nawet o wiele więcej. W tym podstawowym rozwiązaniu podejmiemy decyzję, żeby te kolumny w takim razie porzucić.

Model ML przyjmuje jedynie wartości numeryczne. Musimy więc wszystkie kolumny, które chcemy do modelu wcisnąć, a które zawierają coś innego niż cyfry, zamienić na formę zrozumiałą dla komputera. W tej chwili nasze dane mają formę:
df.info()

Imię i nazwisko pasażera raczej nam się nie przyda, tak samo jak numer biletu, te kolumny pominiemy. Zdecydowaliśmy sie też pominąć wiek i kabinę. Potrzebna jest natomiast płeć, port i klasa. Żeby zamienić dane opisowe na liczbowe, utworzymy dodatkowe kolumny dla tych wszystkich cech, zawierające jedynki i zera - zamiast jednej kolumny Sex z wartościami 'male' i 'female' będziemy mieli 2 nowe kolumny, jedną nazwaną 'male', która będzie posiadała jedynki dla wszystkich pasażerów, którzy są mężczyznami (i zera dla reszty), i jedną kolumnę nazwaną 'female', zawierającą jedynki wszędzie tam, gdzie płeć = kobieta, i analogicznie zera na pozostałych miejscach. To samo stanie się z innymi kolumnami, rozmnożą się.
type_dummies = pd.get_dummies(df['Sex'])
df = pd.concat([df,type_dummies],axis=1)
type_dummies = pd.get_dummies(df['Embarked'])
df = pd.concat([df,type_dummies],axis=1)
type_dummies = pd.get_dummies(df['Pclass'])
df = pd.concat([df,type_dummies],axis=1)
df.sample()

Dlaczego dodajemy kolumny również dla klasy, skoro klasa ma wartość liczbową? Owszem, ma, ale ma wartość 1, 2 , 3. # dla komputera jest większe, niż 2 i 1, mógłby więc w jakiś sposób faworyzować trójki. Albo jedynki. Albo wpaść na inny pomysł, widząc dane, które można porównać. Dlatego zamienimy 1, 2 i 3 na dodatkowe kolumny z zerami i jedynkami, tak samo jak płeć i port. To ma sens?

MLowa część kodu zwykle jest najkrótsza, dużo dzieje się samo i automagicznie, ale wciąż pozostaje kilka decyzji, które musimy podjąć sami. Między innymi:
- które zmienne wejdą do modelu (to mamy trochę wyżej, zdecydowaliśmy się użyć zmiennych Klasa, Wiek, Cena, Port, SibSp i Parch. Wiek i Kabina zostały odrzucone ze względu na duże braki, Bilet ze względu na bardzo dużą niejednorodność danych (bilet to kombinacja literek i cyferek, kilkaset różnych rekordów, o których nie wiemy prawie nic), imię, ponieważ jest unikalne dla każdego pasażera, tak samo jak ID, a zatem mało nam mówi o grupach ludzi (grupa przeżył lub nie)
- jakiego modelu będziemy używać. Nasze badanie oczekuje klasyfikacji, przypisania osoby do grupy 'przeżył' lub 'nie przeżył'. Z tego względu mamy do wyboru szereg modeli do klasyfikacji przeznaczonych, takich jak drzewa losowe, catboost xgboost i inne.
Let's go!
Po pierwsze, metoda odpowiedzialna za trenowanie modelu ma nazwę: fit i oczekuje 2 argumentów:
- Pierwszy argument to macierz/tablica cech (Uwaga: cecha może być jedna, ale to nadal ma być tablica, nie wektor!)
- Drugi argument to wektor zmiennej docelowej (eng. target variable)
# lista cech, których chcemy użyć w modelu:
feats = ['Fare', 'Parch', 'SibSp', 'female', 'male', 'C', 'Q', 'S', 1, 2, 3]
# macierz cech. Pamiętajmy, że złączyliśmy 2 zbiory! Model chcemy stworzyć na podstawie zbioru treningowego, więc
# musimy odfiltrować te wiersze, które nie mają zmiennej Survived!
train = df[df['Survived'].isna() == False][feats] # macierz cech zbioru treningowego
targets = df[df['Survived'].isna() == False]['Survived'] # wektor zmiennej docelowej
X_test = df[feats] # macierz cech zbioru testowego
model = xgb.XGBClassifier() # wybieramy model, dziś to będzie XGBoost
model.fit(train, targets) # trenujemy model na zbiorze treningowym
predictions = model.predict(X_test) # używamy modelu na zbiorze treningowym i próbujemy 'przewidzieć' zawartość kolumny Survived
df["y_pred"] = predictions # dopisujemy przewidziane wyniki do naszego datasetu
I to już :) Wiem, mało imponujące. Co tu zaszło? Algorytm dostał macierz cech X (train) i wektor cechy docelowej Y (targets). Zbadał związki między jednym i drugim i zbudował funkcję, według której cechy train wpływają na wartość targets. Następnie tę funkcję aplikujemy do testowego zbioru (X_test) i generujemy zestaw wyników.
Czas wziąć wyniki, wrzucić na Kaggle i dowiedzieć się, jaki mamy wynik.
results = df[df["Survived"].isna() == True][["PassengerId", "y_pred"]]
results.columns = ["PassengerId", "Survived"]
results["Survived"] = results["Survived"].astype(int)
results.to_csv("very_basic.csv",index=False)

Mój wynik to 0.76555. Myślę, że to się plasuje gdzieś w kategorii brązowego medalu, czyli nie było najgorzej, zdecydowanie może być lepiej. Ale hej, tu chodziło o zrozumienie schematu i kolejności wykonywania działań przy zwyczajnym zadaniu MLowym. Na inżynierię cech i inne cuda przyjdzie jeszcze czas.
PS> Btw, nie dajcie się zdeprymować wynikami równymi 1 na leaderboardzie Kaggle. To ludzie, którzy oszukiwali - tutaj info na ten temat.