{kind=link}
{kind=link}
{kind=link}
{kind=link}
Python program to extract .pdf / .docx data and insert records into SQL Server for analysis


- open parser.iypnb in any jypyter notebook software
- Visual Studio Code jypyter notebook was used to produce output as shown
(can run in cloud up to you)
- you might want to adjust SQL connection string to your database model
(default is used {localhost} database)
- Create a Database named CVs - - refer to figure 1
with the following design, scripts will be provided in SQL folder to create database and tables just run all queries in order.
- edit cv.cvs file - refer to figure - 2
cv.cvs consists of the directories of the CVs, if you want to add CVs to process add the directory where the CV is by adding the path of it in a new line of cv.cvs
example in cv.cvs - refer to figure - 2
([x] is denoted as a line in cv.cvs do not type the brackets and line number in the file)
[1] C:\Users\Ashlin Darius G\Desktop\CVs\abc.pdf
[2] C:\Users\Ashlin Darius G\Desktop\CVs\def.docx
[n] nth cv path
paths might be different depending os type
its default set to windows
so find this line in the jypyter notebook
you are gonna find this in block [9] in the notebook
default windows path
import posixpath
paths[x] = paths[x].replace(os.sep,posixpath.sep)
if you having problem in linux
then you refer to block [9] and append the paths to fit your directory paths
- run all blocks
- Figure [1]
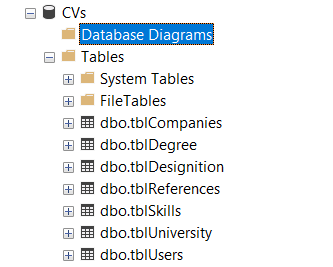
- Figure [2]