{kind=link}
This is the official implementation of our paper, LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models.
Authors: Adian Liusie, Potsawee Manakul, Mark J. F. Gales
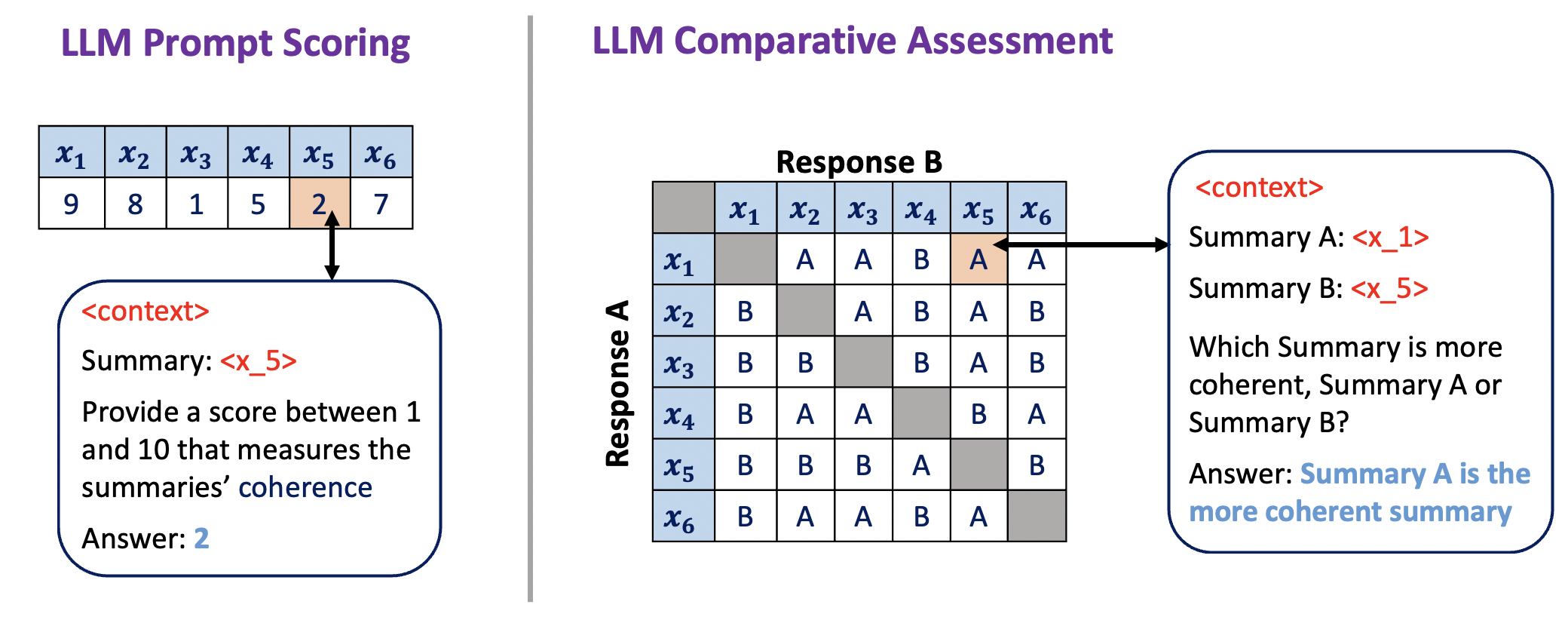
Abstract: Current developments in large language models (LLMs) have enabled impressive zero-shot capabilities across various natural language tasks. An interesting application of these systems is in the automated assessment of natural language generation (NLG), a highly challenging area with great practical benefit. In this paper, we explore two options for exploiting the emergent abilities of LLMs for zero-shot NLG assessment: absolute score prediction, and comparative assessment which uses relative comparisons between pairs of candidates. Though comparative assessment has not been extensively studied in NLG assessment, we note that humans often find it more intuitive to compare two options rather than scoring each one independently. This work examines comparative assessment from multiple perspectives: performance compared to absolute grading; positional biases in the prompt; and efficient ranking in terms of the number of comparisons. We illustrate that LLM comparative assessment is a simple, general and effective approach for NLG assessment. For moderatesized open-source LLMs, such as FlanT5 and Llama2-chat, comparative assessment is superior to prompt scoring, and in many cases can achieve performance competitive with state-ofthe-art methods. Additionally, we demonstrate that LLMs often exhibit strong positional biases when making pairwise comparisons, and we propose debiasing methods that can further improve performance.
pip install -r requirements.txt
python system_run.py --system flant5-xl --dataset summeval --score-type coherency --prompt-id c1 --output-path sum-coh-fT5xl-c1 --shuffle --max-len 10 --comparative
Arguments:
systemselects the LLM used as the backbone for comparative assessmentdatasetis used to specify the dataset to evaluate.score-typedefines the attribute to assess.prompt-idselects the attribute to assess. Comparative prompts begin withc, prompt scoring withsoutput-pathdefines where the outputs should be saved.shuffleis used to shuffle the ordering of examples (for parallelising generation)comparativeis a flag to specify that comparative assessment should be used (if omitted, prompt-scoring assumed)
- Custom datasets can be interfaced in src/data_handler.py
- New prompts and score attributes can be interfaced in src/prompts/load_prompt.py
- Different LLM systems can be added in src/models
Output decisions will be found in the output path, within the outputs/combined.json file. The utility loading files in src/evaluation/loader.py can be used to convert outputs to scores/rankings.