Fake NEWS detector using LIAR-PLUS dataset.
In this project, I have used various NLP techniques ( text classification techniques) and four different machine learning models to classify fake news statements using sci-kit libraries from python.
LIAR-PLUS is a benchmark dataset for fake news detection, released recently. This dataset has evidence sentences extracted automatically from the full-text verdict report written by journalists in Politifact. It consists of 12,836 short statements taken from POLITIFACT and labeled by humans for truthfulness, subject, context/venue, speaker, state, party, and prior history. For truthfulness, the LIAR dataset has six labels: pants-fire, false, mostly-false, half-true, mostly-true, and true. These six label sets are relatively balanced in size. For more you can refer to this paper. Download the dataset from here.
An earlier version of the dataset appeared in this paper. Earlier Dataset can be downloaded from here.
The language used is Python3. Libraries used: ● Numpy
● Pandas
● Scikit-learn
● Seaborn
● nltk(Natural Language toolkit)
● Gensim
● Pickle
● Warnings
- Extract the zip file.
- Upload the ‘faceDetection.ipynb’ file on Google Colaboratory.
- Upload the datasets (i.e. train2.tsv, test2.tsv, val2.tsv, newtrain.csv, newvalid.csv and newtest.csv).
- Run the script on colab.
To get the insight of data I explored the training dataset and to check that all the classes of the label are fairly distributed in all three datasets, I plotted the distribution graph for all three datasets and found that they are fairly distributed.
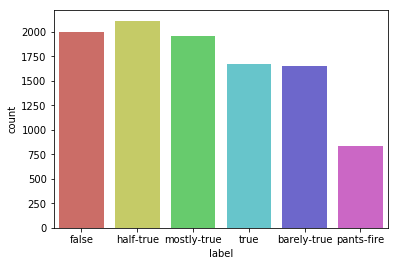
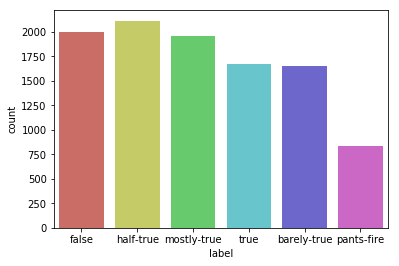

Distribution graphs for train2.tsv, test2.tsv and val2.tsv respectively.
Afterwards I checked for any missing label values with the help of ‘isnull()’ function and the result was none which depicts that there was no need to impute the data. After analyzing the research paper, to increase the accuracy of the classifier I merged the ‘justification’ column with ‘statement’ column of train dataset into a new column named ‘new’ and used it for both binary and six-way classification.
Since we cannot pass the text data directly to the machine learning classifiers as they take vectors of numbers as input, I converted the text into numbers by building a Bag-of-Words model first with CounterVectorizer and then with TfidfVectorizer.
Now, to convert the text data into word-count-vectors I used CountVectorizer method which provides a simple way to both tokenize a collection of text documents and to construct a vocabulary of known words, also it is used to encode new documents using that vocabulary.
● Created an instance of the CountVectorizer class,
● Called the fit_transform() function in order to tokenize, build the vocabulary and encoded the training dataset which returned an encoded vector with a length of entire vocabulary and integer count for the number of times each word appeared in the document.
Term frequency (or word count) has already been calculated by CountVectorizer method, now to calculate the inverse document frequency (idf):
● Created an instance of TfidfTransformer,
● Used the word-count-vectors generated by CountVectorizer method with fit_transform function.
The word-count-vectors generated by this method were then used to generate tfidf-ngram features.
To achieve the highest possible accuracy in binary classification and six-way classification, I used four different machine learning models:
● Logistic Regression
● Support Vector Machines
● Naive Bayes
● Random Forest
Now I used the above models with word-count-vectors first from CountVectorizer method and then from TfidfVectorizer method. Once fitting every model, I compared the f1 score and checked the confusion matrix.
The f1 score obtained resulted with the highest possible accuracy of “28.8%” when the Random Forest model was used with word-count-vectors from CountVectorizer method.
I used the same approach for binary classification task. First I saved new datasets with only 2 classes of the label. Below is the method I used for reducing the number of classes:{true -> true, mostly-true -> true, half-true -> true, barely-true -> false, false -> false, pants-fire -> false }
To reduce the words like attacking, attacked, attacker, etc to the root word attack I used the PorterStemmer stemming method.
But soon I realized that stemming the words could affect the meaning of news, for example: ‘A man was attacked by a lion’ and ‘A man was attacking a lion in Jim Corbett National Park’.
After stemming, the meaning of both sentences changes because both ‘attacked’ and ‘attacking’ are stemmed to their root word ‘attack’.
I also tried tokenizing the statements first to split the sentences into words and then count their frequency, but later on, I found that sci-kit learn library provides methods like ‘CountVectorizer’ and ‘TfidfVectorizer which does both tokenizing and word count. After analysing the research paper[2], I learned about GloVe Word Embeddings and tried to extract features using it’s pretrained vectors loaded from ‘glove.6B.50d.txt’ file but was unable to use them in my models due to lack of time.
For the task of news classification initially, I trained the four different machine learning models with only column-3 i.e. ‘statement’ column of the training dataset(train2.tsv). After training, RandomForest model was giving the highest accuracy of ‘~26%’ with word-count-vectors from CountVectorizer method. I also tried training the machine learning models with word-count-vectors from TfidfVectorizer method but was unable to complete as it was giving an error and I could not resolve it in the given time frame.
- “Where is your Evidence: Improving Fact-checking by JustificationModeling" by Tariq Alhindi, Savvas Petridis and Smaranda Muresan.
- “Liar, Liar Pants on Fire :A New Benchmark Dataset for Fake News Detection” by William Yang Wang.
- New dataset from https://github.com/Tariq60/LIAR-PLUS/tree/master/dataset .
- Old dataset from https://github.com/thiagorainmaker77/liar_dataset .
- Undergone https://machinelearningmastery.com/prepare-text-data-machine-learning-scikit-learn/ for Bag-of-Words model.
- For N-gram model and Tf-Idf model : https://medium.com/machine-learning-intuition/document-classification-part-2-text-processing-eaa26d16c719 .
- For Confusion matrix : https://machinelearningmastery.com/confusion-matrix-machine-learning/ .
- For Generating N-grams from sentences : http://www.albertauyeung.com/post/generating-ngrams-python/ .