다음 공식으로 positional encoding을 구현한다.

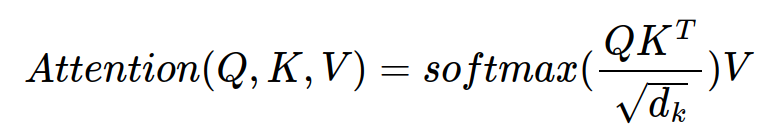

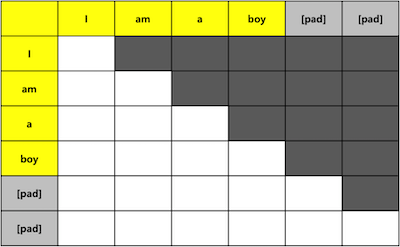
현재 단어와 이전 단어만 볼 수 있고 다음 단어는 볼 수 없도록 masking을 진행한다.

Activation function은 GELU를 사용한다.
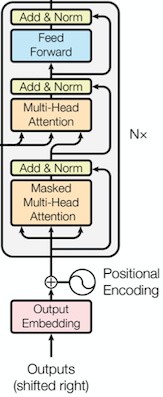
다음 그림을 토대로 decoder layer와 decoder를 구현한다.
Decoder layer 중간의 encoder-decoder attention은 제거한다.
| Name | Name | Last commit date | ||
|---|---|---|---|---|
다음 공식으로 positional encoding을 구현한다.
현재 단어와 이전 단어만 볼 수 있고 다음 단어는 볼 수 없도록 masking을 진행한다.
Activation function은 GELU를 사용한다.
다음 그림을 토대로 decoder layer와 decoder를 구현한다.
Decoder layer 중간의 encoder-decoder attention은 제거한다.