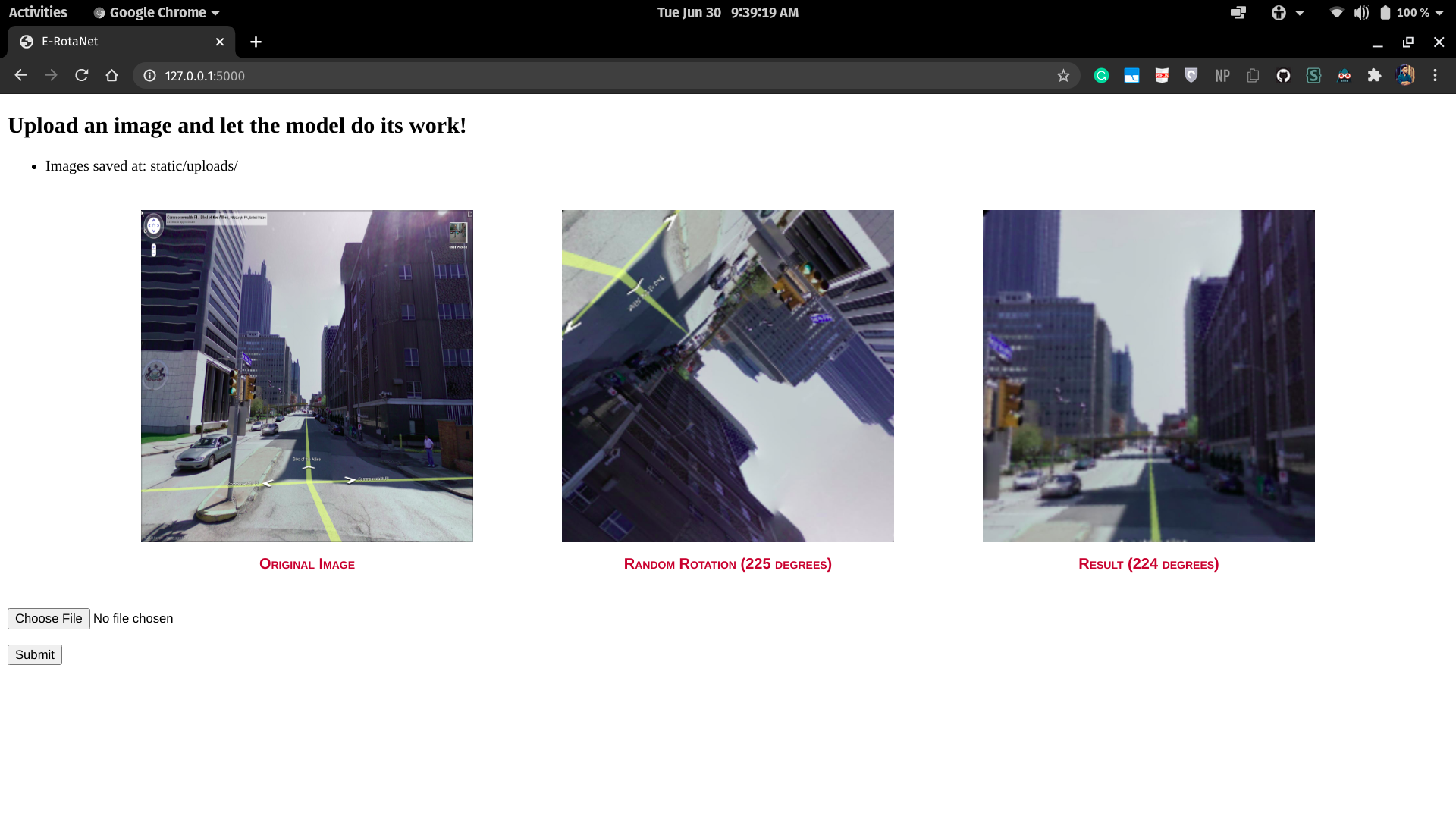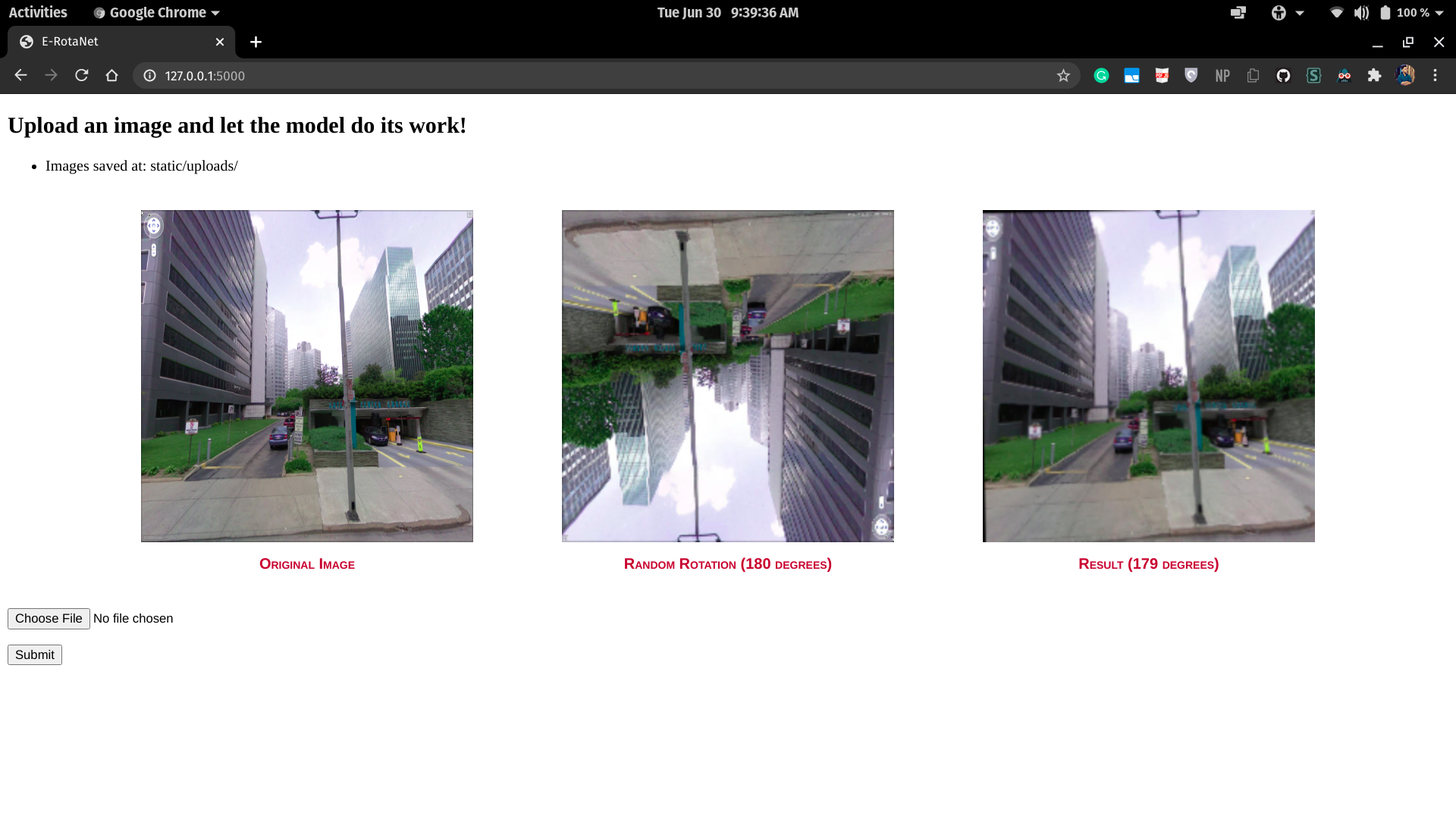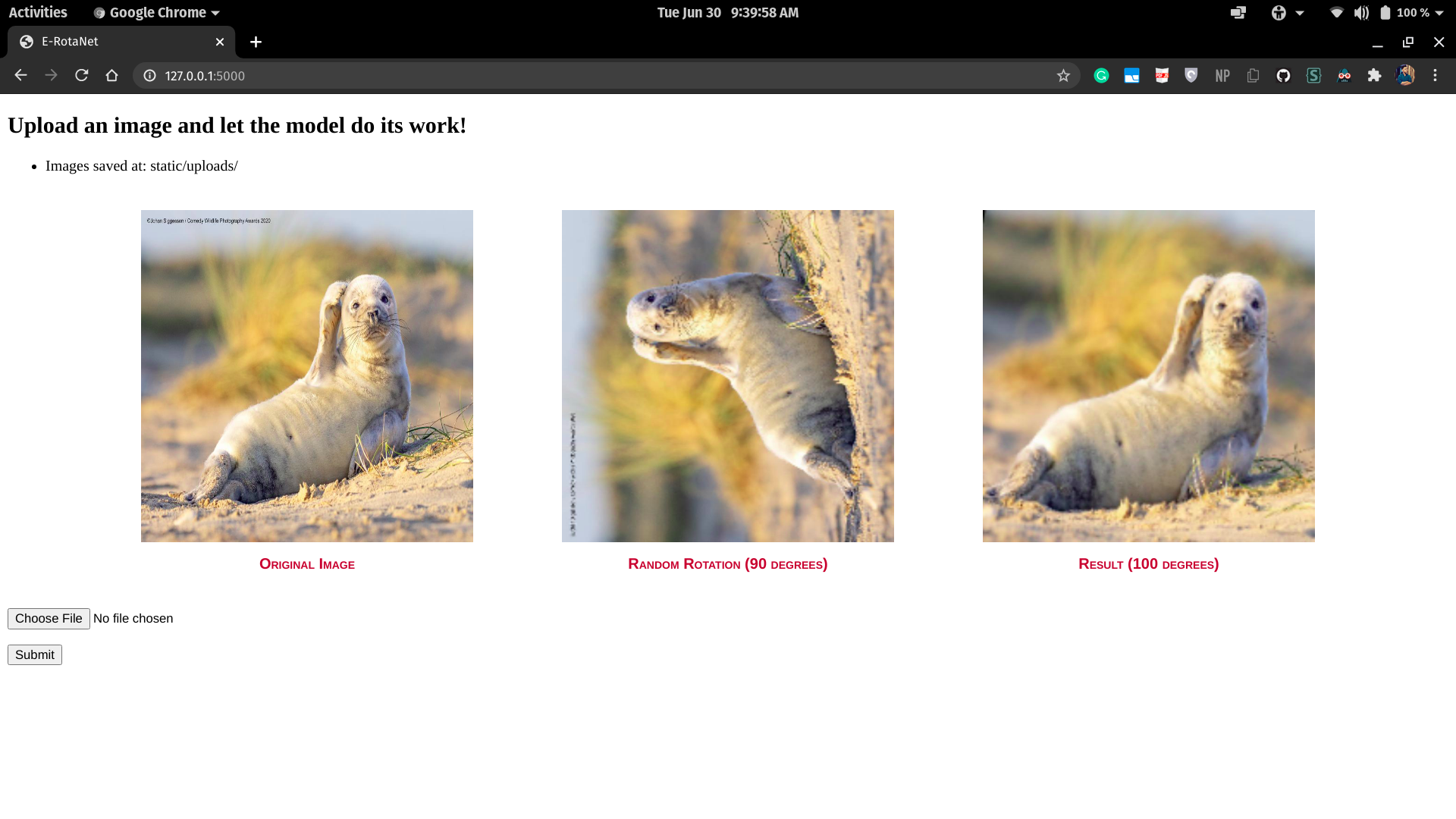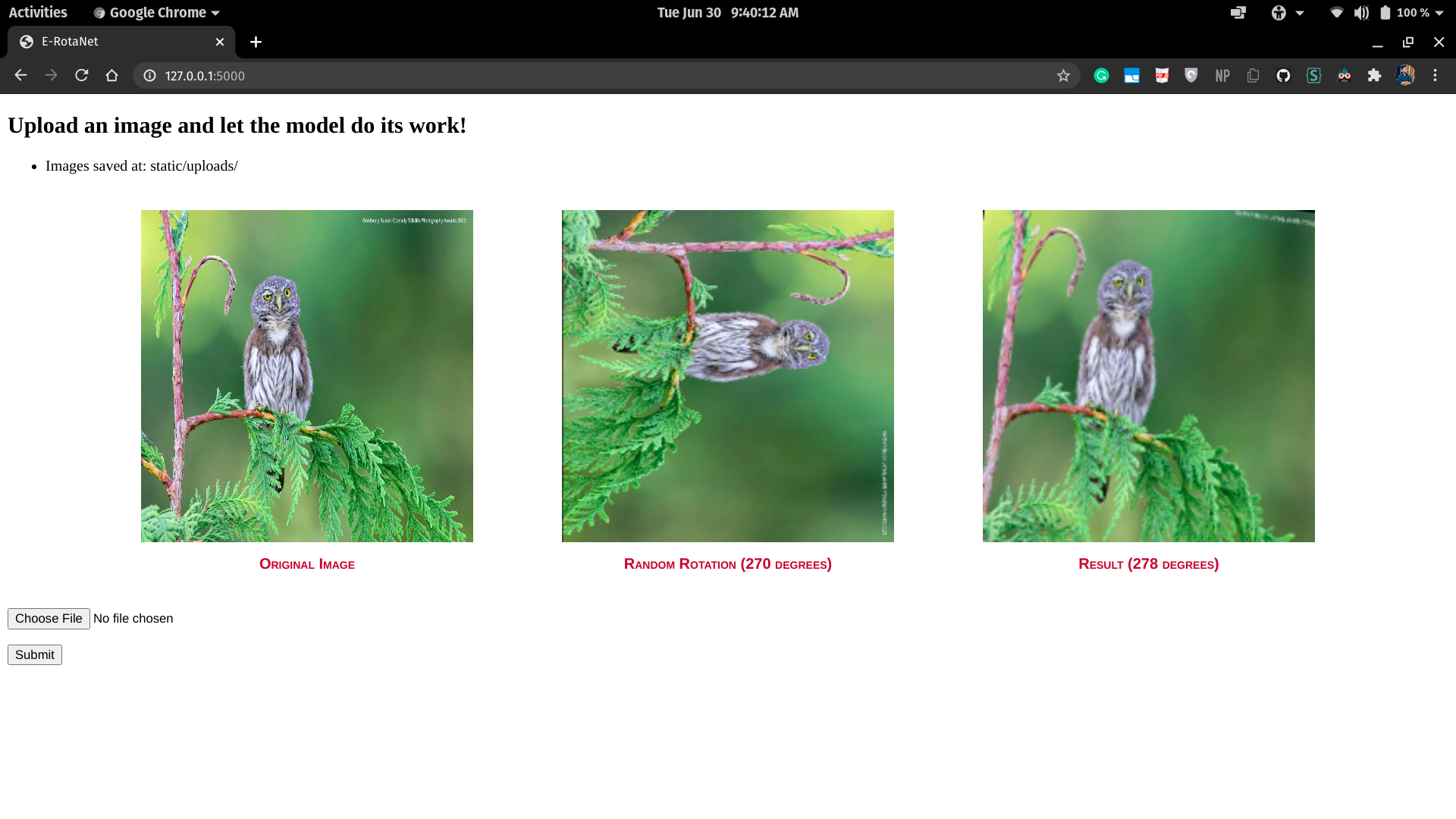
'E' stands for the Efficientnet backbone used in the model, to learn the features and the context of the images.
EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
The released models are trained on Google Street View dataset, which contains ~62k images which contain mostly human-perception viewing angles of streets and buildings.
Note: I highly recommend using Anaconda to maintain the environments.
git clone https://github.com/aitikgupta/E-RotaNet.git
cd E-RotaNet
conda env create -f environment.yml
conda activate e-rotanet
-
python E-RotaNet.pyThe flask application will run on http://127.0.0.1:5000/
-
Note: Training the model will consume around 1-1.5 hours of GPU
python src/train.py --help >>usage: train.py [-h] [--image_dir IMAGE_DIR] [--model_save MODEL_SAVE] [--resume_training RESUME_TRAINING] [--tb_dir TB_DIR] [--batch_size BATCH_SIZE] [--n_epochs N_EPOCHS] [--val_split VAL_SPLIT] [--img_size IMG_SIZE] [--regress] [--device DEVICE] optional arguments: -h, --help show this help message and exit --image_dir IMAGE_DIR Path to images directory --model_save MODEL_SAVE Model output directory --resume_training RESUME_TRAINING Path to model checkpoint to resume training --tb_dir TB_DIR Tensorboard logs directory --batch_size BATCH_SIZE Batch size --n_epochs N_EPOCHS Number of epochs --val_split VAL_SPLIT Validation split for images, eg. (0.2) --img_size IMG_SIZE Input size of image to the model, eg. (224,224) --regress Use regression instead of classification --device DEVICE Use device for inference (gpu/cpu) -
Note: 2-ways to proceed:
- Evaluate an image directory (Images will be randomly rotated)
- Evaluate a single image (Image will be rotated from 0->360 degrees and mean error will be printed)
python src/evaluate.py --help >>usage: evaluate.py [-h] [--model_dir MODEL_DIR] [--eval_dir EVAL_DIR] [--eval_single EVAL_SINGLE] [--batch_size BATCH_SIZE] [--img_size IMG_SIZE] [--regress] [--device DEVICE] optional arguments: -h, --help show this help message and exit --model_dir MODEL_DIR Path to model --eval_dir EVAL_DIR Path to images directory (Images will be randomly rotated) --eval_single EVAL_SINGLE Path to the image (Image will be rotated from 0 to 360 degrees) --batch_size BATCH_SIZE Batch size --img_size IMG_SIZE Input size of image to the model --regress Use regression instead of classification --device DEVICE Use device for inference (gpu/cpu)
-
To look at how the loss function works:
python src/loss.py >>Total Error: 0.7847222089767456 Absolute differences between angles: Truth: 60.0, Pred: 355.0 ; Diff: 65.0 Truth: 90.0, Pred: 360.0 ; Diff: 90.0 -
python src/preprocess.py >>[<PIL.Image.Image image mode=RGB size=224x224 at 0x7F278C492B70>, (1024, 1280, 3)]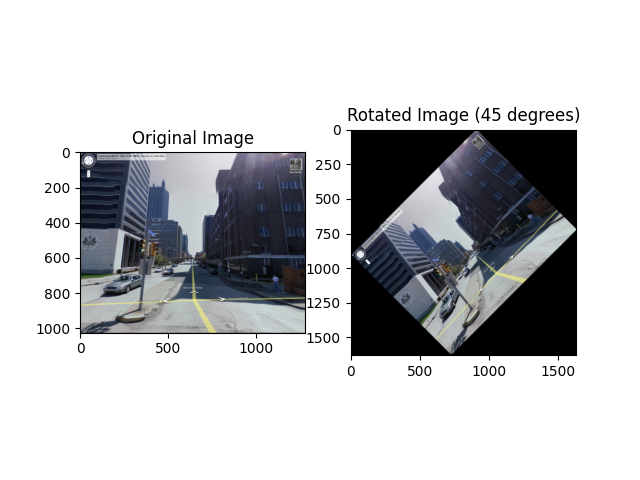
Note: The black corners are just for demonstration purpose, they're cropped in the actual pipeline
-
Output from the model
python src/predict.py \ --image_path images/000001_0.jpg \ --model_path release/model.h5 \ --rotation -1 \ --device cpu >>[<PIL.Image.Image image mode=RGB size=1024x1280 at 0x7F47D4765080>, <PIL.Image.Image image mode=RGB size=1024x1280 at 0x7F47D4765BE0>, 163]