
Menarik pelanggan dengan promo.
- Deskripsi
- Analisis Statistikal Deskriptif
- Feature Engineering
- Feature Selection
- Develop Model
- Evaluasi Statistik
- Produk Final
- Tentang Penulis
Proyek ini memiliki objektif untuk membantu perusahaan fintech untuk mengklasifikasi member yang akan mendapatkan promo menggunakan logistic regression. Data yang diberikan adalah data mentah berupa csv yang merupakan data dari 50.000 user dengan 12 variabel first_open, dayofweek, hour, liked dll. member yang akan mendapatkan promo adalah member yang besar kemungkinan tidak langganan layanan premium. ini dimaksudkan dengan adanya promo maka mereka akan tertarik untuk menggunakan fitur premium
- Python
- Logistic Regression
- K fold cross validation
Statistik deskriptif merupakan analisis statistik yang memberikan gambaran secara umum mengenai karakteristik dari masing-masing variabel sehingga memberikan informasi yang berguna.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#import data set
dataku = pd.read_csv('data_fintech.csv')#ringkasan data
ringkasan = dataku.describe()
tipe_data = dataku.dtypes
#revisi kolom num screen
dataku['screen_list'] = dataku.screen_list.astype(str)+','
#membuat kolom perhitungan koma
dataku['num_screens'] = dataku.screen_list.str.count(',')
dataku.drop(columns=['numscreens'],inplace =True)
#konversi hour dari object ke integer
dataku.hour[1]
dataku.hour = dataku.hour.str.slice(1,3).astype(int)
#drop semua colom yang bukan angka
dataku_numerik = dataku.drop(columns=['user', 'first_open','screen_list'
,'enrolled_date'], inplace = False)
#membuat histogram
sns.set()
plt.suptitle('Overview Data')
for i in range(0,dataku_numerik.shape[1]):
plt.subplot(3,3,i+1)
figure = plt.gca()
figure.set_title(dataku_numerik.columns.values[i])
jumlah_bin = np.size(dataku_numerik.iloc[:,i].unique())
plt.hist(dataku_numerik.iloc[:,i], bins=jumlah_bin)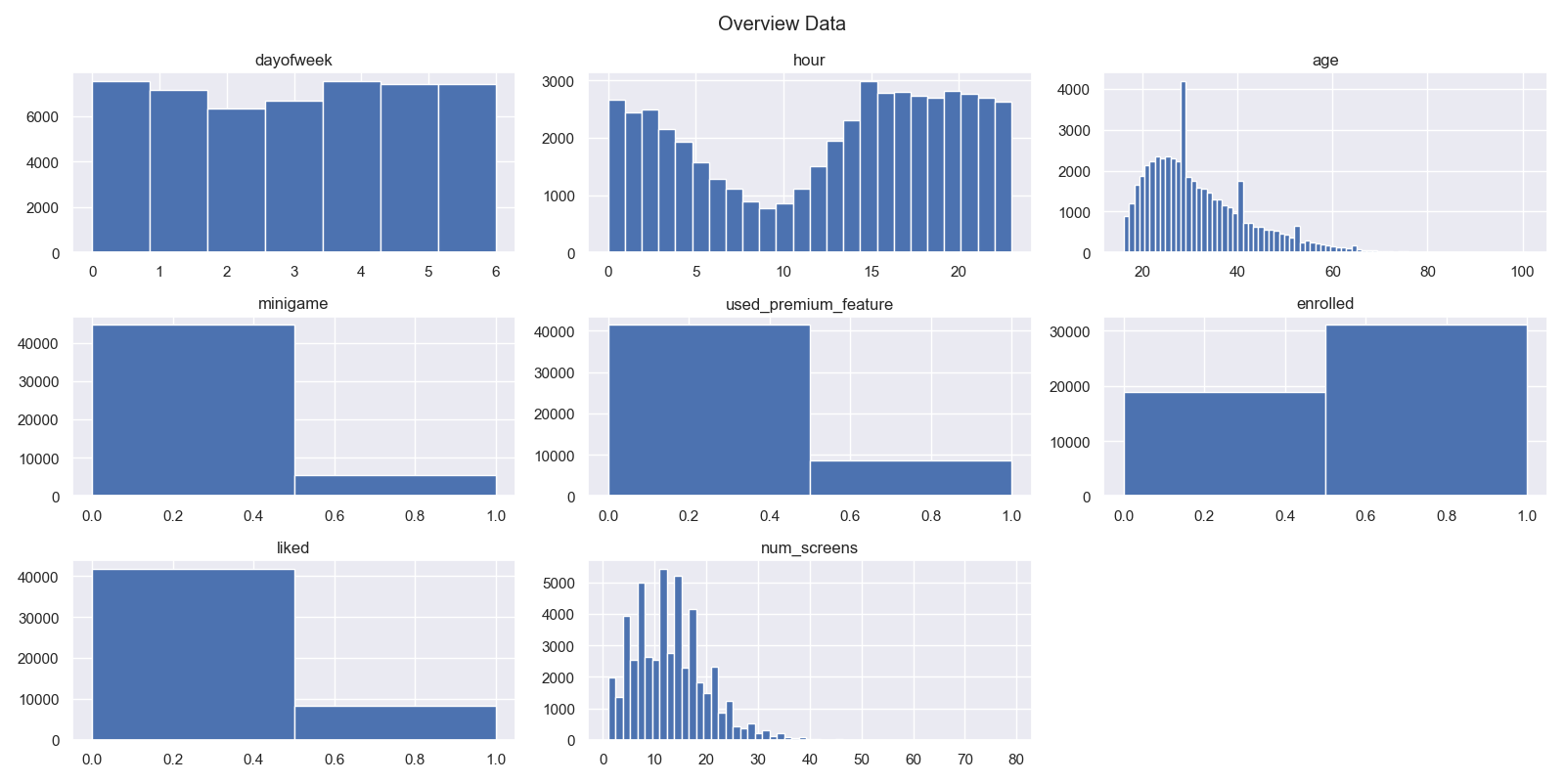 Dari kumpulan histogram masing masing variabel dapat di ketahui bahwa untuk variabel age dan num_screens memiliki sebaran yang tidak normal atau skewed.
Dari kumpulan histogram masing masing variabel dapat di ketahui bahwa untuk variabel age dan num_screens memiliki sebaran yang tidak normal atau skewed.
korelasi = dataku_numerik.drop(columns=['enrolled'],inplace=False).corrwith(dataku_numerik.enrolled)
korelasi.plot.bar('korelasi variable terhadap keputusan enrolled')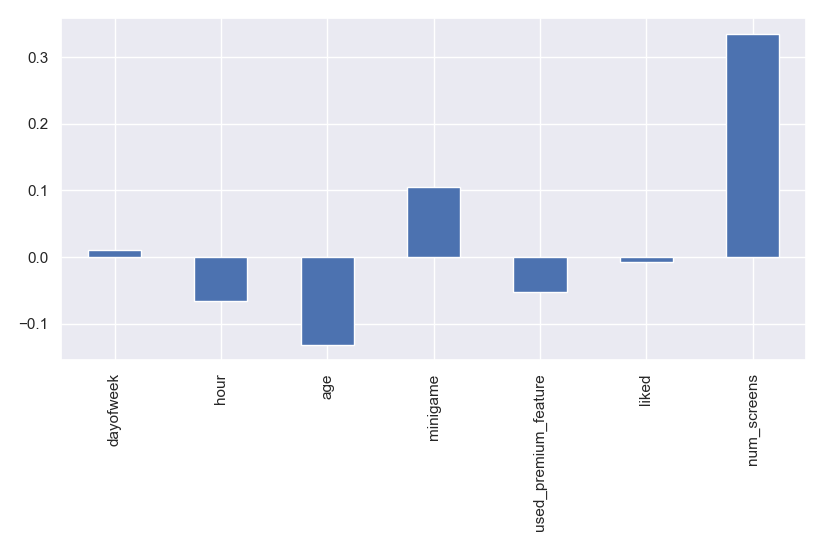
Dari ke 7 variabel yang sudah di ubah ke bentuk numerik. Variabel num_screens memiliki korelasi tertinggi yang artinya semakin banyak user mengakses jumlah layar maka akan semakin besar kemungkinan user untuk meng enrolled fitur premium. meskipun demikian presentase korelasinya cuma 0.3 artinya tidak begitu kuat sehingga bukan variabel noise yang dapat meredupkan variabel yang lain.
#membuat heatmap antar variable
matriks_korelasi = dataku_numerik.drop(columns=['enrolled'],inplace=False).corr()
sns.heatmap(matriks_korelasi, cmap='Reds')
#membuat heatmap custom
#buat matriks mask
mask = np.zeros_like(matriks_korelasi, dtype = np.bool)
mask[np.triu_indices_from(mask)] =True
#heatmap custom
ax = plt.axes()
cmapku = sns.diverging_palette(200,0,as_cmap=True)
sns.heatmap(matriks_korelasi,cmap=cmapku,mask=mask,linewidths=0.5,center=0,square=True)
ax=plt.suptitle('matriks korelasi antar variabel')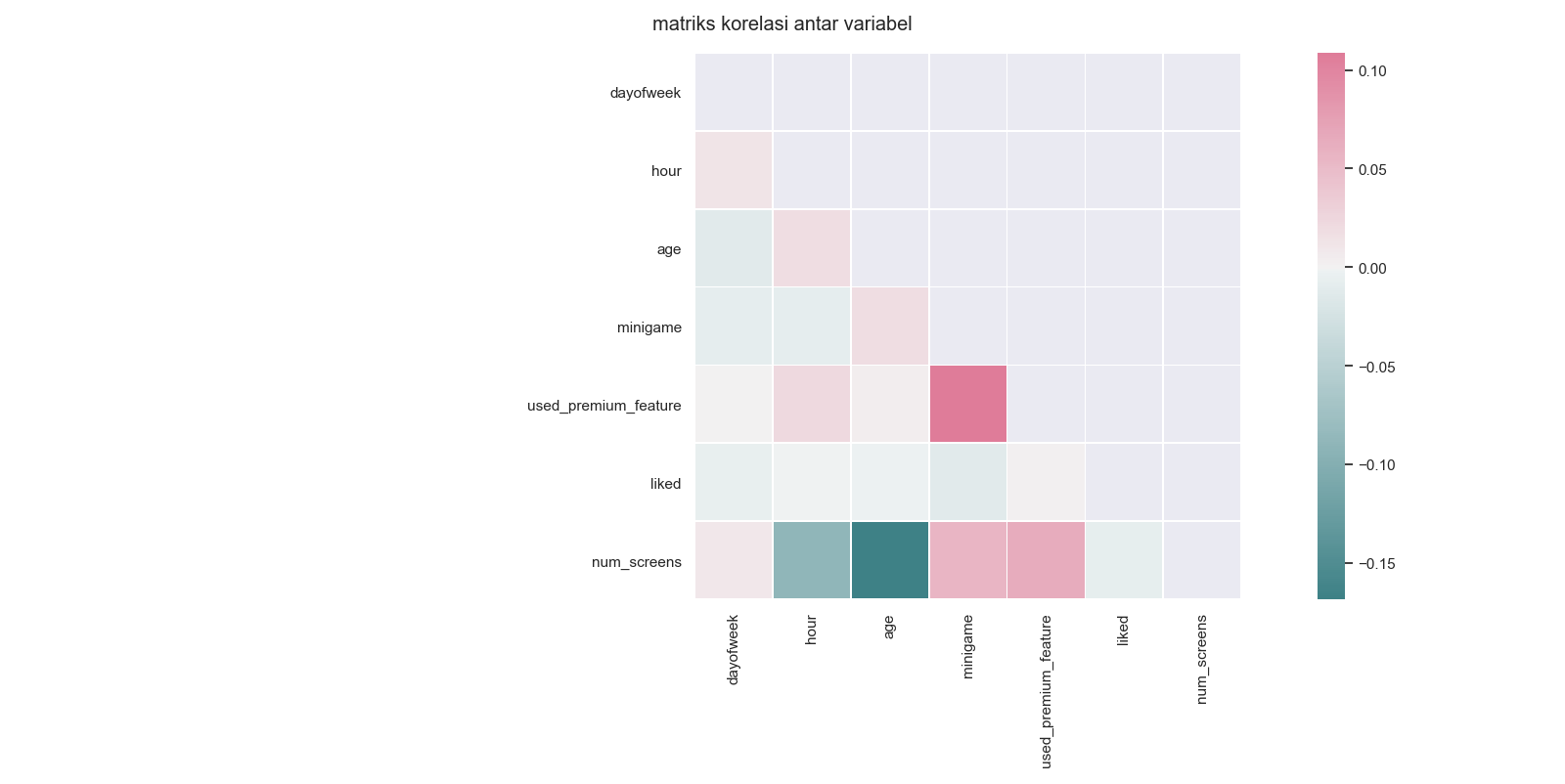 Pada heat map ini di tampilkan lebih luas masing masing korelasi satu variabel terhadap variabel lain.
Pada heat map ini di tampilkan lebih luas masing masing korelasi satu variabel terhadap variabel lain.
Pada analisis di atas diketahui bahwa ada beberapa variabel/feature yang tidak terdistribusi secara normal atau skewed. Data yang tidak terdistribusi normal ini disebabkan oleh data-data yang tidak merepresentasikan populasi atau yang kita sebut dengan noise. Sehingga diperlukan Feature Engineering untuk menghilangkan noise.
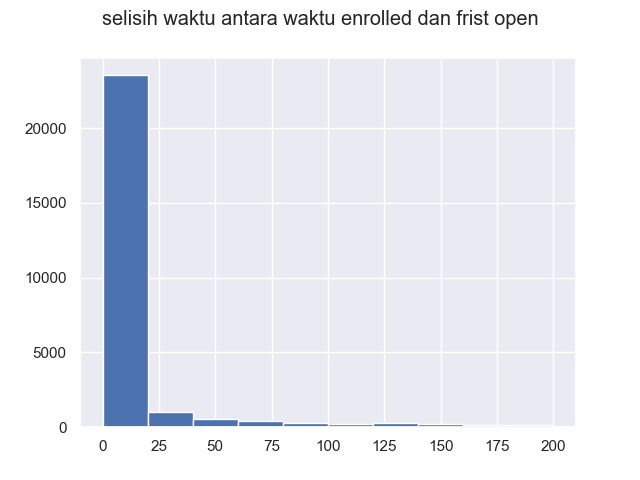
Data menunjukkan bahwa dari 0-25 merupakan representasi populasi. Selisih merupakan waktu user berlangganan dan waktu pertamakali membuka aplikasi. dalam kasus ini penulis mengambil rentan data 0-50 sebagai populasi untuk melatih model.
#proses parsing
from dateutil import parser
dataku.first_open = [parser.parse(i) for i in dataku.first_open]
dataku.enrolled_date = [parser.parse(i) if isinstance(i,str) else i for i in dataku.enrolled_date]
dataku['selisih'] = (dataku.enrolled_date - dataku.first_open).astype('timedelta64[h]')
#membuat histogram dataku['selisih']
plt.hist(dataku.selisih.dropna(), range =[0,200])
plt.suptitle('selisih waktu antara waktu enrolled dan frist open')
plt.show()
#memfilter nilai selisih yang lebih dari 50 jam karena tidak merepresentasikan populasi
dataku.loc[dataku.selisih>50,'enrolled']=0proses parsing di gunakan untuk menguraikan, atau pada kasus ini untuk merubah/memperbaiki kolom frist_open yang masih berupa text/string ke bentuk numerik.
Pada dataset (dataku) kita mempunya kolom screen_list, pada kolom tersebut kita pilih layar layar yang paling sering di akses. Maka dari itu di perlukan data set ke 2 yakni dataset top_screens yang diberikan oleh pihak fintech.
#mengimport data top screen
top_screens = pd.read_csv('top_screens.csv')
top_screens = np.array(top_screens.loc[:,'top_screens'])
#mencopy dataku
dataku2 = dataku.copy()
#membuat kolom topscreen
for layar in top_screens:
dataku2[layar] = dataku2.screen_list.str.contains(layar).astype(int)
for layar in top_screens:
dataku2['screen_list'] = dataku2.screen_list.str.replace(layar+',','')
#menghitung layar selain top screen
dataku2['lainya'] = dataku2.screen_list.str.count(',')
top_screens.sort()pada tahap ini data sudah bersih dari noise serta sudah berubah pada format yang tepat untuk ketahap selanjutnya.
Pada Feature Engineering kita sudah membreakdown layar layar yang sering diakses oleh user. Akan tetapi beberapa daftar top_screens yang diberikan oleh pihak fintech memiliki kesamaan seperti layar loan ada loan, loan 2, loan 3 dst. begitupun untuk layar saving, credit dan cc maka dengan Feature selection kita menggabungkan layar yang mirip.
# teknik funneling. penyederhanaan variable yang mirip
layar_loan = ['Loan',
'Loan2',
'Loan3',
'Loan4']
dataku2['jumlah_loan'] = dataku2[layar_loan].sum(axis=1)
dataku2.drop(columns=layar_loan, inplace = True)
layar_saving = ['Saving1',
'Saving2',
'Saving2Amount',
'Saving4',
'Saving5',
'Saving6',
'Saving7',
'Saving8',
'Saving9',
'Saving10']
dataku2['jumlah_Saving'] = dataku2[layar_saving].sum(axis=1)
dataku2.drop(columns=layar_saving, inplace = True)
layar_credit= ['Credit1',
'Credit2',
'Credit3',
'Credit3Container',
'Credit3Dashboard']
dataku2['jumlah_credit'] = dataku2[layar_credit].sum(axis=1)
dataku2.drop(columns=layar_credit, inplace = True)
layar_cc =['CC1',
'CC1Category',
'CC3']
dataku2['jumlah_cc'] = dataku2[layar_cc].sum(axis=1)
dataku2.drop(columns=layar_cc,inplace=True)
#mendefisinikan var dependen
var_enrolled = np.array(dataku2['enrolled'])
#menghilangkan kolom redundant
dataku2.drop(columns = ['user','first_open','enrolled','screen_list',
'enrolled_date'],inplace =True)
dataku2.drop(columns =['selisih'],inplace = True)sekarang semua data yang diperlukan untuk melakukan membuat model sudah siap.
Untuk mentraining model yang bertujuan untuk mengklasifikasi user penulis mencoba menggunakan metode logistic egression. Metode ini merupakan model linier umum yang digunakan untuk regresi binomial.
#membagi training set dan test set
from sklearn.model_selection import train_test_split
X_train,X_test,y_train, y_test = train_test_split(np.array(dataku2),var_enrolled,
test_size = 0.2,
random_state = 111)
#menghapus variabel kosong
X_train = np.delete (X_train,27,1)
X_test = np.delete (X_test,27,1)
#scalling. standarisasi data
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
#LOGISTIC REGRESSION
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state=0, solver='liblinear',
penalty='l1')
classifier.fit(X_train, y_train)
#mencoba membuat prediksi pada X_test
y_pred = classifier.predict(X_test)
#melihat evaluasi dengan confussion matrix
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
cm= confusion_matrix(y_test, y_pred)Ternyata pada kolom ke 27 terdapat variabel yang seluruh angkanya adalah 0. maka variabel ini kita hilangkan saja.
evaluasi = accuracy_score(y_test, y_pred)
print('akurasi:{:.2f}'.format(evaluasi*100))akurasi:76.32
cm_label= pd.DataFrame(cm, columns=np.unique(y_test),
index= np.unique(y_test))
cm_label.index.name='aktual'
cm_label.columns.name='prediksi'
sns.heatmap(cm_label, annot= True, cmap='Reds',fmt='g') 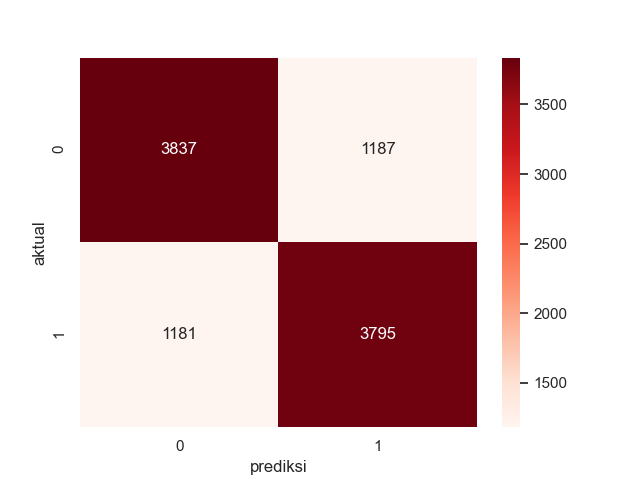
Diagram confussion matrix menujukkan bahwa model logistic regression mampu memprediksi user yang tidak enrolled dengan benar sebanyak 3837 user dan salah 1187 dan memprediksi user yang enrolled dengan benar sebanyak 3795 dan salah 1181.
#validasi dengan 10 fold cross validation
from sklearn.model_selection import cross_val_score
accuracies = cross_val_score(estimator=classifier,X=X_train,y=y_train, cv=10)
#melihat mean dan standart deviasi
accuracies.mean()
accuracies.std()
print('akurasi logistic regresi ={:.2f}% +/- {:.2f}%'.format(accuracies.mean()*100,accuracies.std()*100))akurasi logistic regresi =76.58% +/- 0.79%
Model ini merupakan model yang memprediksi keputusan berdasarkan behaviour user sehingga akurasi tersebut terbilang tinggi diatas 75%.
Yang dibutuhkan oleh perusahaan adalah daftar user yang akan diberi promo atau tidak. Maka KPI nya adalah sebuah daftar user yang akan di beri promo.
#membuat daftar saran orang yang akan mendapatkan promo
#mencopy dataku
dataku2 = dataku.copy()
var_enrolled = dataku2['enrolled']
from sklearn.model_selection import train_test_split
X_train,X_test,y_train, y_test = train_test_split(dataku2,var_enrolled,
test_size = 0.2,
random_state = 111)
train_id = X_train['user']
test_id = X_test['user']
#menggabungkan
y_pred_series = pd.Series(y_test).rename('asli',inplace =True)
hasil_akhir = pd.concat([y_pred_series,test_id],axis=1).dropna()
hasil_akhir['prediksi'] = y_pred
hasil_akhir = hasil_akhir[['user','asli','prediksi']].reset_index(drop=True)Karena pada proses feature selection kita membuang kolom user karena kita hanya membutuhkan kolom numerik. Maka untuk melacak user kita mencopy ulang dataku dan membangi nya dengan train_test_split dengan random state yang sama. sehingga di akhir proses daftar yang di inginkan oleh perusahaan sudah tersedia.

hi, saya Albara saya seorang mahasiswa teknik industri universitas islam indonesia yang memiliki ketertarikan pada bidang data science. jika anda ingin menghubungi saya anda dapat mengirim pesan pada link berikut.
- Twitter - @albara_bimakasa
- Email - 18522360@students.uii.ac.id