
Mendeteksi nasabah yang mungkin melakukan kecurangan
- Deskripsi
- Preprocessing Data
- Artificial Neural Network
- Evaluasi Statistik
- Teknik Under Sampling
- Evaluasi Statistik Teknik Under Sampling
- Pengujian Model Awal dan Under Sampling
- Tentang Penulis
Proyek ini memiliki objektif untuk membantu perusahaan kartu kredit untuk mendeteksi nasabah yang berpotensi melakukan fraud. Perusahaan memberikan data csv yang merupakan data dari 280.000 user dengan 29 variabel independen dan 1 variabel dependen. hasil akhir yang diinginkan adalah model yang bisa mengklasifikasi ya/tidak antara nasabah yang kemungkinan melakukan fraud.
- Python
- Artificial Neural Network
- Teknik Under Sampling
Feature Engineering adalah bagaimana kita menggunakan pengetahuan kita dalam membuat feature baru atau sekedar memodifikasinya sedangkan Features Selection adalah proses memilih features baik menggabungkan beberapa feature atau membuang sebagian feature. Kedua metode dimaksudkan agar model machine learning dapat bekerja lebih akurat dalam memecahkan masalah.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data_ku = pd.read_csv('data_kartu_kredit.csv');
data_ku.shapeStandarisasi Kolom Amount dengan metode "StadardScaler"
from sklearn.preprocessing import StandardScaler
data_ku['standar'] = StandardScaler().fit_transform(data_ku['Amount'].values.reshape(-1,1))standarisasi dimaksudkan untuk memudahkan komputasi
Membuang variabel yang tidak digunakan.
y = np.array(data_ku.iloc[:,-2])
X = np.array(data_ku.drop(['Time','Amount','Class'], axis=1))y = variabel dependen x = variabel independen
Untuk mentraining model yang bertujuan untuk mendeteksi user yang fraud kita menggunakan Artificial Neural Network . Metode ini merupakan sistem adaptif yang dapat mengubah strukturnya untuk memecahkan masalah berdasarkan informasi eksternal maupun internal yang mengalir melalui jaringan tersebut.l.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2 ,
random_state=111)
X_train, X_validate, y_train, y_validate = train_test_split(X_train,y_train,
test_size=0.2,
random_state=111)from keras.models import Sequential
from keras.layers import Dense, Dropout
classifier = Sequential()
classifier.add(Dense(units=16, input_dim=29, activation='relu'))
classifier.add(Dense(units=24, activation='relu'))
classifier.add(Dropout(0.25))
classifier.add(Dense(units=20, activation='relu'))
classifier.add(Dense(units=24, activation='relu'))
classifier.add(Dense(units=1, activation='sigmoid'))
classifier.compile(optimizer='adam', loss='binary_crossentropy',
metrics=('accuracy'))
classifier.summary()from keras.utils.vis_utils import plot_model
plot_model(classifier, to_file ='model_ann.png', show_shapes=True,show_layer_names=False)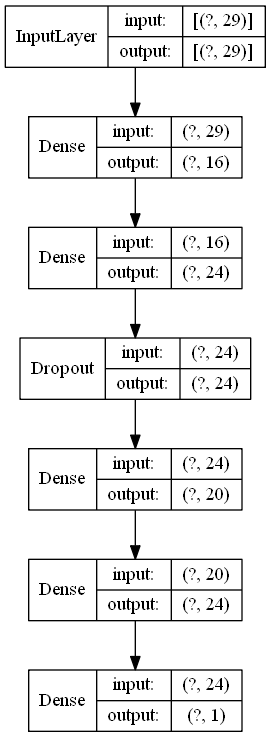
run_model = classifier.fit(X_train, y_train,
batch_size = 32,
epochs= 5,
verbose = 1,
validation_data = (X_validate, y_validate)) Epoch 1/5 5697/5697 [] - 9s 2ms/step - loss: 0.0029 - accuracy: 0.9994 - val_loss: 0.0031 - val_accuracy: 0.9994994
Epoch 2/5 5697/5697 [] - 8s 1ms/step - loss: 0.0030 - accuracy: 0.9994 - val_loss: 0.0031 - val_accuracy: 0.9994
Epoch 3/5 5697/5697 [] - 11s 2ms/step - loss: 0.0028 - accuracy: 0.9994 - val_loss: 0.0031 - val_accuracy: 0.9994
Epoch 4/5 5697/5697 [] - 12s 2ms/step - loss: 0.0026 - accuracy: 0.9995 - val_loss: 0.0031 - val_accuracy: 0.9994
Epoch 5/5 5697/5697 [] - 15s 3ms/step - loss: 0.0025 - accuracy: 0.9995 - val_loss: 0.0029 - val_accuracy: 0.9994
plt.plot(run_model.history['accuracy'])
plt.plot(run_model.history['val_accuracy'])
plt.title('model accuracy')
plt.xlabel('accuracy')
plt.ylabel('epoch')
plt.legend(['train','validate'], loc ='upper left')
plt.show()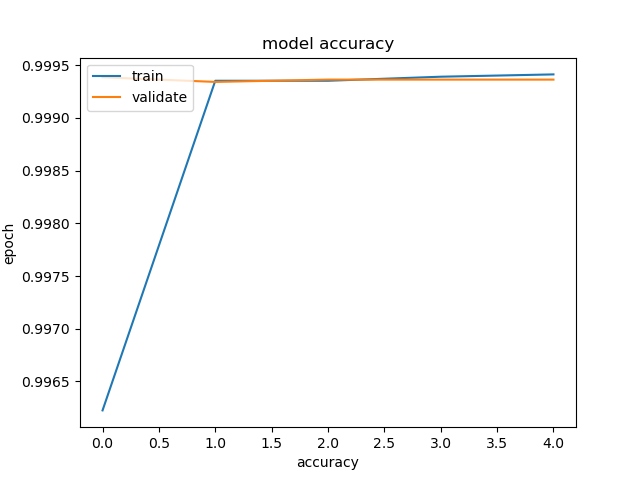
plt.plot(run_model.history['loss'])
plt.plot(run_model.history['val_loss'])
plt.title('model loss')
plt.xlabel('loss')
plt.ylabel('epoch')
plt.legend(['train','validate'], loc ='upper left')
plt.show() 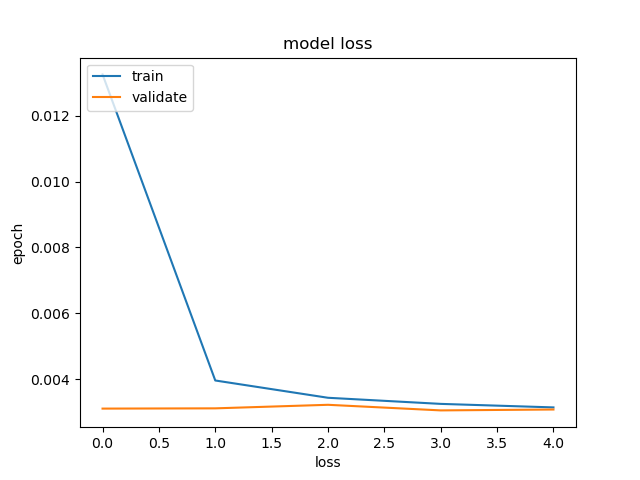
Data X_test dan y_test merupakan data yang belum pernah dilihat oleh model ANN.
evaluasi = classifier.evaluate(X_test,y_test)
print('akurasi:{:.2f}'.format(evaluasi[1]*100))1781/1781 [==============================] - 1s 823us/step-loss: 0.0023 - accuracy: 0.9994 akurasi:99.94
hasil_prediksi = classifier.predict_classes(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, hasil_prediksi)
cm_label = pd.DataFrame(cm, columns=np.unique(y_test),index=np.unique(y_test))
cm_label.index.name = 'aktual'
cm_label.columns.name = 'prediksi'
sns.heatmap(cm_label, annot=True, Cmap='Reds', fmt='g')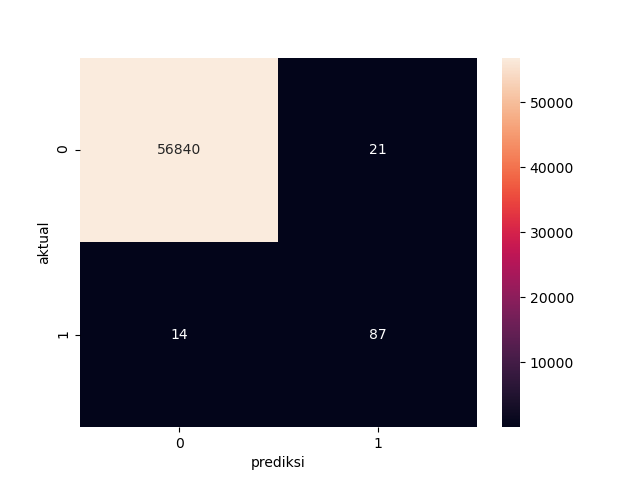
from sklearn.metrics import classification_report
jumlah_kategori = 2
target_names = ['class{}'.format(i) for i in range(jumlah_kategori)]
print(classification_report(y_test, hasil_prediksi,target_names=target_names)) precision recall f1-score support
class0 1.00 1.00 1.00 56861
class1 0.81 0.86 0.83 101
accuracy 1.00 56962
macro avg 0.90 0.93 0.92 56962
weighted avg 1.00 1.00 1.00 56962
Pada tahap Menguji model ANN pada data X_test dan y_test didapat akurasi sebesar 99.94% sangat tinggi atau bisa dikatakan terlampau tinggi sehingga too good to be truth. Akurasi tersebut dapat dijelaskan dengan melihat nilai F1-score Nilai f1-score pada class0 memiliki nilai 1, sebuah nilai sempurna yang hampir mustahil terjadi. sedangkan untuk class1 pada angka 0.83. Sehingga dapat disimpulkan terjadi imbalance dataset yang disebabkan tidak seimbang data untuk yang melakukan kecurangan dan tidak.
- Undersampling menyeimbangkan dataset dengan mengurangi ukuran kelas yang berlimpah. Metode ini digunakan ketika jumlah data mencukupi. Dengan menjaga semua sampel di kelas langka dan secara acak memilih jumlah sampel yang sama di kelas berlimpah, dataset baru yang seimbang dapat diambil untuk pemodelan lebih lanjut. Pada intinya step-step yang berbeda dengan model awal adalah pada proses preprocessing data.
index_fraud = np.array(data_ku[data_ku.Class == 1].index)
n_fraud = len(index_fraud)
index_normal = np.array(data_ku[data_ku == 0].index)
index_data_normal = np.random.choice(index_normal, n_fraud, replace=False )
index_data_baru = np.concatenate([index_fraud, index_data_normal])
data_baru = data_ku.iloc[index_data_baru,:]y_baru = np.array(data_baru.iloc[:,-2])
X_baru = np.array(data_baru.drop(['Time','Amount','Class'], axis=1)) X_train2, X_test_final, y_train2, y_test_final = train_test_split(X_baru,y_baru,
test_size = 0.1,
random_state=111)
X_train2, X_test2, y_train2, y_test2 = train_test_split(X_train2,y_train2,
test_size = 0.1 ,
random_state=111)
X_train2, X_validate2, y_train2, y_validate2 = train_test_split(X_train2,y_train2,
test_size=0.2,
random_state=111)classifier2 = Sequential()
classifier2.add(Dense(units=16, input_dim=29, activation='relu'))
classifier2.add(Dense(units=24, activation='relu'))
classifier2.add(Dropout(0.25))
classifier2.add(Dense(units=20, activation='relu'))
classifier2.add(Dense(units=24, activation='relu'))
classifier2.add(Dense(units=1, activation='sigmoid'))
classifier2.compile(optimizer='adam', loss='binary_crossentropy',
metrics=('accuracy'))
classifier.summary()run_model2 = classifier2.fit(X_train2, y_train2,
batch_size = 8,
epochs= 5,
verbose = 1,
validation_data = (X_validate2, y_validate2))plt.plot(run_model2.history['accuracy'])
plt.plot(run_model2.history['val_accuracy'])
plt.title('model accuracy')
plt.xlabel('accuracy')
plt.ylabel('epoch')
plt.legend(['train','validate'], loc ='upper left')
plt.show()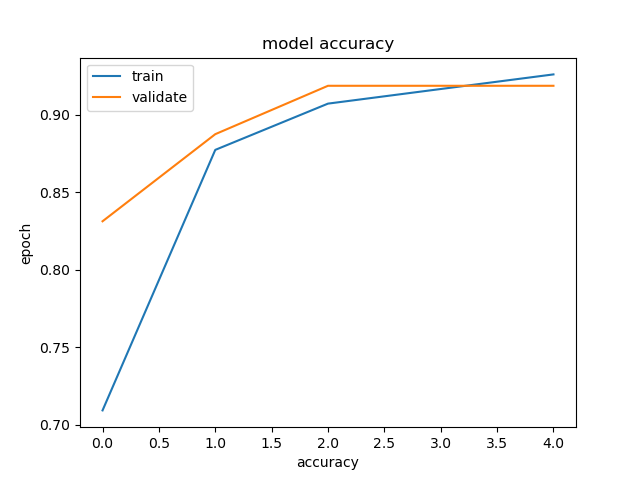
plt.plot(run_model2.history['loss'])
plt.plot(run_model2.history['val_loss'])
plt.title('model loss')
plt.xlabel('loss')
plt.ylabel('epoch')
plt.legend(['train','validate'], loc ='upper left')
plt.show()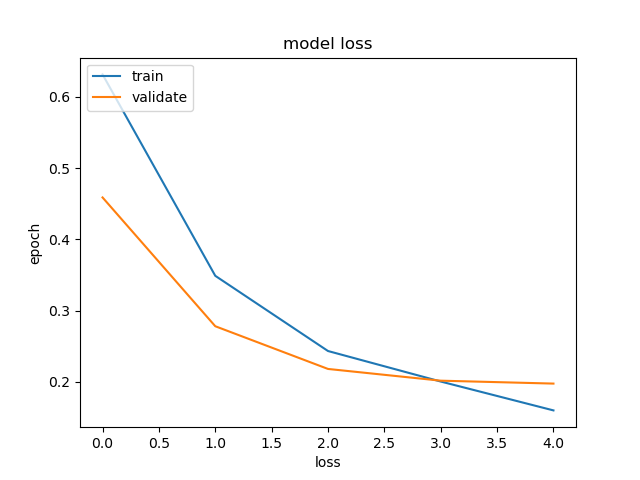
evaluasi2 = classifier2.evaluate(X_test2,y_test2)
print('akurasi:{:.2f}'.format(evaluasi2[1]*100))3/3 [==============================] - 0s 5ms/step - loss: 0.1846 - accuracy: 0.9213
akurasi:92.13
Pada model dengan teknik undersampling didapat akurasi sebesar 92.13 % sebuah model yang sudah cukup baik, tidak terlalu sempurna mendekati 100%.
hasil_prediksi2 = classifier2.predict_classes(X_test2)
cm2 = confusion_matrix(y_test2, hasil_prediksi2)
cm_label2 = pd.DataFrame(cm2, columns=np.unique(y_test2),index=np.unique(y_test2))
cm_label2.index.name = 'aktual'
cm_label2.columns.name = 'prediksi'
sns.heatmap(cm_label2, annot=True, Cmap='Reds', fmt='g')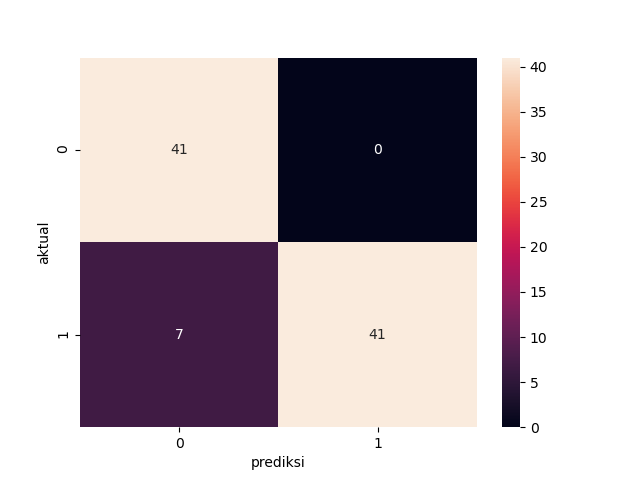
print(classification_report(y_test2, hasil_prediksi2,target_names=target_names)) precision recall f1-score support
class0 0.85 1.00 0.92 41
class1 1.00 0.85 0.92 48
accuracy 0.92 89
macro avg 0.93 0.93 0.92 89
weighted avg 0.93 0.92 0.92 89
Dengan menggunakan teknik undersampling didapat nilai F1-Score sebesar 0.92. Kita mengabaikan nilai sempurna precission pada Class1 dan berfokus pada nilai F1-Score, ini dikarenakan F1-Score sendiri adalah harmonic mean dari precision dan recall.
Pengujian ini adalah menjalankan model pada data yang belumpernah dilihat sama sekali. atau data yang merepresentasikan dunia nyata.
hasil_prediksi3 = classifier2.predict_classes(X_test_final)
cm3 = confusion_matrix(y_test_final, hasil_prediksi3)
cm_label3 = pd.DataFrame(cm3, columns=np.unique(y_test_final),index=np.unique(y_test_final))
cm_label3.index.name = 'aktual'
cm_label3.columns.name = 'prediksi'
sns.heatmap(cm_label3, annot=True, Cmap='Reds', fmt='g')
precision recall f1-score support
class0 0.95 0.96 0.96 56
class1 0.95 0.93 0.94 43
accuracy 0.95 99
macro avg 0.95 0.95 0.95 99
weighted avg 0.95 0.95 0.95 99
Hasil pengujian lumayan baik meski tidak setinggi model yang awal akan tetapi model ini mempunyai kelebihan bisa di generalisir dalam artian dapat di aplikasikan kepada data data real yang tidak berat sebelah.

hi, saya Albara saya seorang mahasiswa teknik industri universitas islam indonesia yang memiliki ketertarikan pada bidang data science. jika anda ingin menghubungi saya anda dapat mengirim pesan pada link berikut.
- Twitter - @albara_bimakasa
- Email - 18522360@students.uii.ac.id