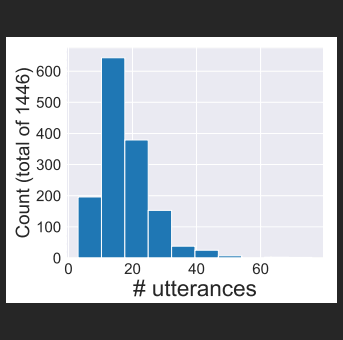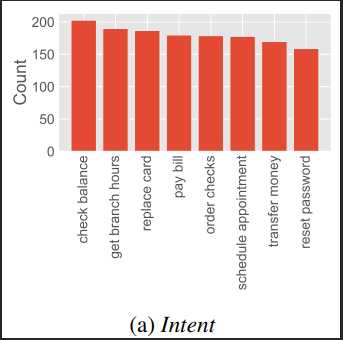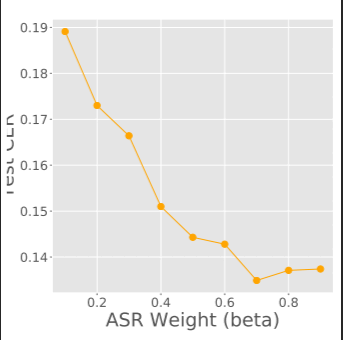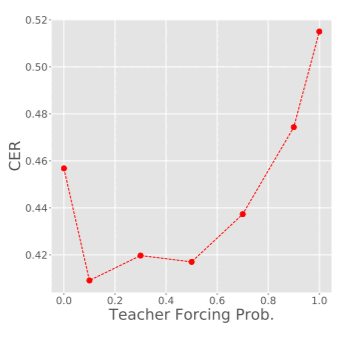
In the financial sector, understanding customer needs accurately and efficiently is paramount. This project aims to advance speech recognition capabilities within banking dialogues by employing a Convolutional, Recurrent, and Dense Neural Network (CRDNN) alongside Language Model (LM) support. Utilizing the HarperValleyBank (HVB) corpus, we delve into creating a speech recognition system that accurately transcribes banking interactions, paving the way for improved customer service automation and analytics in the banking industry.
The primary goal is to elevate the precision and performance of automatic speech recognition (ASR) systems tailored for banking dialogues. By optimizing a CRDNN model with the HVB dataset and integrating language models for context, project strive to develop an ASR system that can faithfully transcribe spoken banking dialogues, enhancing customer service experiences and operational efficiencies.
- HarperValleyBank (HVB) Corpus: A specialized spoken dialog corpus for banking, featuring annotated banking interactions. For further information, consult the HVB Corpus Documentation.
- CRDNN Model Optimization: Fine-tuning a pre-existing CRDNN model from SpeechBrain with the HVB dataset to better accommodate banking-specific dialogues.
- Language Model Application: Enhancing transcription accuracy by incorporating language models that offer banking-specific contextual understanding.
- Performance Assessment: Evaluating the optimized CRDNN model, both with and without LM enhancement, using a test segment of the HVB corpus to determine transcription effectiveness.
- SpeechBrain: A comprehensive, PyTorch-powered speech toolkit facilitating pre-trained ASR model access and deployment.
- Hugging Face: Used for accessing and implementing the SpeechBrain pre-trained CRDNN model.
- Python Ecosystem: Utilizes
torchaudio,torch,json, among other libraries for efficient data management and model training workflows.
Follow these steps to prepare your environment and obtain all necessary resources:
# Prepare the HVB dataset
gdown 1oJh0U3g_bUx6UPX4xix2UHMVHeCE_H1y
gdown 1_OXiLOL2RBsbdCb4WyQsLudYxzJxMDJr
unzip -q hvb.zip
mv content/data /content/
rm -r /content/content
# Retrieve configuration files for training and inference
gdown 1a0EGlsLbXnGn1xwZoSqT0tcdAQ1L2nfd # train.py
gdown 1yCmjRbxXRxfEN5LXdnE1Zpl8ZOIzdrAO # train.yaml
gdown 1KHmdcLVFI9ontvGmi5J6vfaropGYuKcr # inference.yaml
# Install SpeechBrain
pip install speechbrain -qRefer to the included Python scripts and configuration files for comprehensive training and evaluation instructions.
My sincere appreciation goes to the SpeechBrain toolkit creators and the HVB corpus maintainers for their contributions to the public domain, supporting ongoing advancements in speech recognition technology.