Reinforcement Learning applied to Object Avoidance.
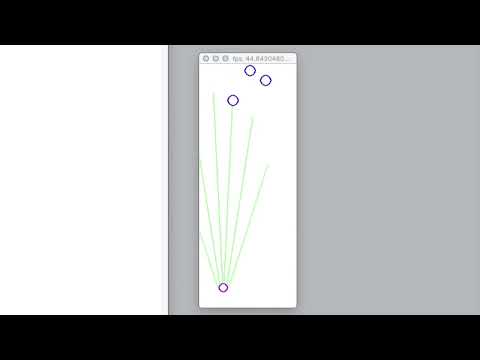
Using the tf-agents library, I taught an RL agent to play my own custom game. The game involves an agent, represented by the purple ball, dodging falling green balls.
At each timestep:
- The agent perceives its environment using six raycasts, and it receives their lengths, ranging from 0 to 1 as input.
- The agent can take one of three actions: move left, move right, or do nothing.
The episode ends when the agent hits either a ball or wanders into one of the side walls.
This project uses the following libraries in addition to Python 3.7:
By cloning the repo to your local machine, you can run:
pip install -r /path/to/requirements.txt
to install all dependencies, assuming you have python3 and pip installed.
-
The environment is defined in the file env.py.
-
Running load_model.py loads up an existing model from tmp/full_train, and checks its performance by stepping through its policy.
-
Running train.py creates an untrained model and trains it until it receives a reward of > 1500. The model is saved as a checkpoint in the newly_trained_models directory under tmp.
So what was my approach to solving this problem?
For this project, I used the reinforce-agent, which is provided by the tf-agents library and based on the Policy Gradients algorithm. The algorithm is essentially an act and observe strategy, where the agent learns the ideal action to take when given an environment state. Such is the case in many RL algorithms, but PG forms a set of probabilities for each possible action which measure the liklihood that the action is going to maximize reward. Over time, the agent learns which decision making policy maximizes the reward it receives. For more information, this article offers a more detailed view.
How is the agent rewarded?
If the agent survives a timestep,
It is given a fixed reward of 1.0 for surviving, and it receives more reward equal to the average raycast length for that particular timestep. In other words, the agent is rewarded for having a the space above it clear of balls.
If the agent dies,
It receives a reward of -100.0 for hitting a ball or the wall.
How is the agent trained?
The agent wants to choose the best action for each state, so it refines its own policy over the course of many episodes using data gathered in the episode. In the beginning, the agent's actions are random, but it slowly learns which state actions lead to higher reward through experience.
For instance, one general relationship that the agent may find is that when the raycasts on the left become small, moving to the right leads to higher rewards. This makes intuitive sense, as this would represent a situation in which a ball would be approaching the agent from the left, and so the agent should dodge the ball by moving right.
What's the result?
The model plays better than me within around 300-500 training episodes ~ 30 mins on my 5 year old laptop.
The current hyperparameters and model setup are likely not ideal. I'd encourage cloning the repo to find a more efficient solution, but I can share some of my experiences:
When first training the model, I originally used four raycasts and a retrospectively high learning rate of 0.01 as well as only one fully connected layer of 100 nodes.
This setup lead to very inconsistent and varied performance. Occasionally, the agent would find a very good policy within less than 250 training episodes and other times the agent wouldn't find an adequate policy even after many episodes. In other words, the model seemed "highstrung," making drastic changes to pursue some higher reward it found in the short term.
Through more testing, I found that lowering the learning rate from 0.01 to 0.001 as well as adding another fully connected layer improved the agent's performance.
The game can be made more difficult by increasing the rate at which balls spawn into the environment. This setting and others like it can be changed in the env.py file.
Born out of a casual interest in machine learning, this is my first project involving ML!