Code and documentation for the winning solution at the BCI Challenge @ NER 2015 : https://www.kaggle.com/c/inria-bci-challenge
Authors:
- Alexandre Barachant
- Rafal Cycon
- Cédric Gouy-Pailler
Contents :
Licence : GLPv3. see Licence.txt
The goal of this challenge was to detect error related potential recorded during a p300 spelling task. The classification must be done across subjects, i.e. training and test sets were composed by different subjects. This is a hard task due to the high inter-subjects variability of EEG. However, our Riemannian Geometry framework has been proven very powerful for dealing with this problem (see [2], [3], and the decMeg2014 kaggle challenge). This is partly due to the property of invariance by congruent transformation of the Riemannian metric.
Starting from here, the main difficulties of this challenge were to deal with the relatively high number of electrodes and to avoid overfitting. We overcome the first issue by using a channel selection algorithm, and the second by using a bagging procedure and an appropriate cross-validation methodology.
The leak : By analyzing the time between feedback events in session 5, it was possible to catch the output of the online detection Error. The idea is that when an error is detected, the correction of this error induces a small delay that can be detected with more or less reliability. Given that the online Error detection was properly calibrated for the current subject, this analysis gave us two insights :
-
the output of the online error detection for session 5. Of course, there is a higher probability of error when the online classifier detects an error, but it depends on the accuracy of the online classifier. This can be used to increase detection accuracy, but only for the session 5.
-
the percentage of error in session 5 i.e. a rough estimate of the class balance for each subjects. This second information is really important, because it can help to optimize the global AUC criterion, by adjusting the prediction to match the error probability of each subjects. Of course, this only helps the global AUC performance, and has little effect on the subject performance.
We propose two different models. The first one does not make any use of the leakage information and satisfies an "online processing" constraint, which means that any trial performed by a subject can be classified without the need for future complementary data or information. The second model uses the leak, thus it is not online-compatible. The two models are built upon the same classification pipeline, but with parameters tuned independently to achieve the highest performance.
EEG Signals are bandpass filtered by a 5th order Butterworth filter between 1 and 40 Hz. Then, signals are epoched to take only 1.3 second after the feedback event. The EOG channel is removed prior to any preprocessing.
The EEG-based Feature extraction is done in 4 steps :
- Xdawn Covariances : Two sets of 5 XDAWN [1] spatial filters are estimated, one for each class (Error and Correct). The grand average evoked potential of each class is then filtered by the corresponding set of spatial filters, and concatenated to each epochs. The covariance matrix of each resulting epoch is then used as feature for the next steps. This process is similar to the one described in [2] and [3].
- Electrode Selection : A channel selection is applied to keep only relevant channels. The procedure consist in a backward elimination with the Riemannian distance between the Riemannian Geometric mean of the covariances of each class as the criterion. The algorithm is described in [4].
- Tangent Space : Reduced Covariances matrices are then projected in the tangent space, as described in [5] and [6].
- Normalization : Feature Normalization using a l1 norm.
After these 4 steps, a set of Meta Feature are added to the EEG-based features. The basic set of Meta feature is the following :
- Session id : the session number of the current epoch.
- FeedBack : the Feedback count since the beginning of the session.
- Letter : the Letter position in the current word.
- Word : the word count since the beginning of the session.
- FeedBackTot : the feedback count since the first session.
- WordTot : the word count since the first session.
- isLong : was the current word flashed 8 times, i.e. a long sequence of flashes.
For the leak only, two other features are added :
- OnlineErr : 1 if the online Error detection has detected an error (only available in session 5).
- Err Prop : the percentage of errors detected in the session 5.
All the above features are inputted to an Elastic Net algorithm.
For the leak only, Err Prop is added to the prediction with a coefficient of 0.8. As an effect, it biases the results with an estimation of the classes balances. This has no effect on the AUC of a single subject, but acts as on optimization for the Global AUC, which was the target metric.
The above pipeline is applied on a number of random subsets of subjects, and predictions are averaged across bagged models. Each bagged model is built on an unique set of features (high diversity of features between subsets of subjects is achieved mostly due to the Electrode Selection step in feature extraction) and thus represents a different point of view of the training data. Ensembling bagged models improves generalization and effectively counters overfitting.
Final submission was an average of predictions of 500 bagged models, each trained on 9 subjects (out of 16, just one more subject above 50%). In 4-fold CV 150 bagged models were used.
The validation approach was a 4-fold CV with data randomly split into folds subject-wise. The splitting was repeated several times (10 in most cases) and obtained AUCs averaged. The method proved to produce a reliable measure of performance.
| Submission | Public LB | Private LB | Fold-wise CV (std) | Subject-wise CV (std) |
|---|---|---|---|---|
| No Leak (online compatible) | 0.85083 | 0.84585 | 0.7294 (0.037) | 0.7696 (0.004) |
| Leak | 0.85145 | 0.87224 | 0.8008 (0.039) | 0.7801 (0.004) |
CV results are given for 150 models, using the CV procedure described above. Fold-CV refers to the average AUC evaluated on all the predictions of the tests subjects. Subject-wise CV refers to the average AUC evaluated for each subject independently. Subject-wise CV represents performance of the model in a real case scenario, i.e. the performance a single user could expect in a online experiment.
Results across Public and Private LB are quite stable and exhibit very good performance of both models.
In cross validation, the introduction of the leak has a little effect (0.01 AUC) on subject specific performance, but has a tremendous effect on Fold CV. Shifting the predictions according to the leak effectively improves the Fold AUC.
Interestingly, this effect is not as strong for LB results. Indeed, the no-leak model is able to correctly catch the class balance of each subject and bias the prediction accordingly. This effect was not observed in CV results due to a smaller test set size.
A very important parameter was the number of electrodes in the electrode selection step ('nelec') of feature extraction. Riemannian geometry works best with a moderately low number of electrodes. The number of features in the tangent space is N(N+1)/2 with N the number of channels. A too high number of electrodes can lead to overfitting and estimation issues, while a too small number of channels leads to a loss of information.
Varying the number of electrodes gives the following results (for the no-leak model) :
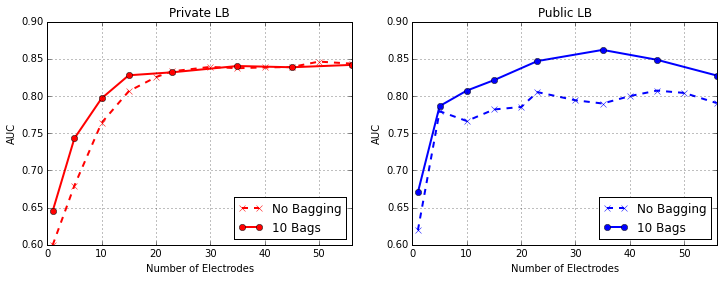
The electrode selection already achieves very high performance for a number of electrodes as low as 15. Interestingly, using all electrodes gives the best AUC for private LB, but an optimal choice of number of electrodes may be different when using more bagged models.
The introduction of bagged model stabilizes results by making the prediction less sensitive to the electrode subset. This effect is bigger when the number of electrodes in the subset decreases.
The final no-leak model was set to 35 electrodes, and only 23 for the leak model. These values were chosen according mainly to CV results, but also partially to public LB scores.
For the final submission we used 500 bagged models, each composed of 9 randomly selected subjects. The number of models for the final submissions was chosen based on the fact that adding more models could improve generalization (up to some 'plateau' point, which was unknown at the time), but too many models could not hurt the performance. It was the safest choice while keeping the processing time reasonable.
Post-competition tests indicated that as few as 10 models were already enough to provide good performance in private LB (tests made with the no-leak model):
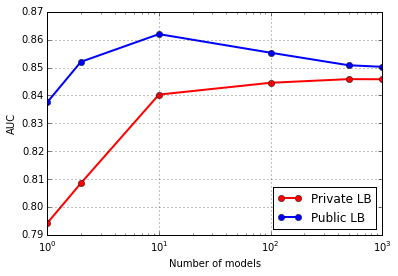
The proposed method shows very good performance. For the specific combination of subjects in the private LB, electrode selection and ensembling did not improve significantly results. However, they did help to prevent overfitting and increase significantly performances in cross-validation.
The introduction of Meta features improve the results by 0.015 AUC on private LB. While some of them seem odd, they are acting as a support for the classifier to take into account the possible shift in error prediction due to mental fatigue of the subject and other source of variability that occurs in long EEG sessions.
For this challenge, the evaluation criterion was the AUC calculated from the predictions of all the subjects put together. However, the fact that the subjects have different classes balances allow to optimize the score without making any prediction. As a matter of fact, submitting the estimation of class balance of each subject (thanks to the leak) results in a Private LB score of 0.746, enough to be ranked in the top10.
[1] Rivet, B.; Souloumiac, A.; Attina, V.; Gibert, G., "xDAWN Algorithm to Enhance Evoked Potentials: Application to Brain–Computer Interface," IEEE Transactions on Biomedical Engineering, vol.56, no.8, pp.2035,2043, Aug. 2009
[2] A. Barachant, M. Congedo ,"A Plug&Play P300 BCI Using Information Geometry", arXiv:1409.0107. link
[3] M. Congedo, A. Barachant, A. Andreev ,"A New generation of Brain-Computer Interface Based on Riemannian Geometry", arXiv: 1310.8115. link
[4] A. Barachant and S. Bonnet, "Channel selection procedure using riemannian distance for BCI applications," in 2011 5th International IEEE/EMBS Conference on Neural Engineering (NER), 2011, 348-351. pdf
[5] A. Barachant, S. Bonnet, M. Congedo and C. Jutten, “Multiclass Brain-Computer Interface Classification by Riemannian Geometry,” in IEEE Transactions on Biomedical Engineering, vol. 59, no. 4, p. 920-928, 2012. pdf
[6] A. Barachant, S. Bonnet, M. Congedo and C. Jutten, “Classification of covariance matrices using a Riemannian-based kernel for BCI applications“, in NeuroComputing, vol. 112, p. 172-178, 2013. pdf
The code is written in python. At least 8GB of RAM is required. The following packages are used :
- sklearn
- numpy
- scipy
- pylab
- pandas
- pyyaml
- glob
- multiprocessing
Extract train.zip and test.zip in the data folder. Put file TrainLabels.csv in the folder data/train.
Apply preprocessing on the data (one time only) :
cd preproc/
python preproc.pyrun prediction.py with the desired parameter file from the main folder.
For the submission with the leak :
python prediction.py parameters_Leak.yamlFor the submission without the leak :
python prediction.py parameters_noLeak.yamlrun cross_valid.py with the desired parameter file from the main folder.
For the submission with the leak :
python cross_valid.py parameters_Leak.yamlFor the submission without the leak :
python cross_valid.py parameters_noLeak.yamlCV takes around 12h to run on a 12-core, 64GB RAM computer
If you get Memory Error, decrease the number of cores in the parameters file. By default 4 cores are used, which should work fine on a computer with 16GB RAM.
For this challenge, we built a framework based on the sklearn Pipeline system allowing us to quickly test different ideas and parameters without changing a line of code. The classification pipeline is described in a parameter file, using a yaml syntax, and then parsed and built on the fly by the scripts. Parameters files can be shared between team-mates, and Version Controlled, reducing the chance of errors.
The parameter file for the no-leak submission looks like this :
imports:
sklearn.linear_model :
- ElasticNet
sklearn.preprocessing:
- Normalizer
classif:
- XdawnCovariances
- TangentSpace
- AddMeta
- ElectrodeSelect
CrossVal:
cores: 4
folds: 4
repetitions: 10
path: results.csv
comments: 'model-final-noLeak'
Submission:
path: submission-noLeak.csv
cores: 4
MetaPipeline:
#leak:
bagging:
bag_size: 0.51
models: 500
pipeline:
- XdawnCovariances:
nfilter: 5
subelec: range(0,56,1)
- ElectrodeSelect:
nfilters: 5
nelec: 35
metric: "'riemann'"
- TangentSpace:
metric: "'logeuclid'"
tsupdate: False
- Normalizer:
norm: '"l1"'
- AddMeta:
- ElasticNet:
l1_ratio: 0.5
alpha: 2e-4
normalize: TrueThe import section lists packages to import : The following section :
sklearn.linear_model :
- ElasticNetis evaluated as :
from sklearn.linear_model import ElasticNetThe different steps in the classification pipeline are described in the pipeline section. They are build and pipelined in the order of appearance in the yaml list.
The last element should implement two methods : fit and predict. All the intermediate element should implement a fit_transform and a transform methods. For more information about sklearn pipeline, see sklearn.pipeline
the folowing section
- ElasticNet:
l1_ratio: 0.5
alpha: 2e-4
normalize: Trueis evaluated as :
ElasticNet(l1_ratio=0.5 , alpha=2e-4 , normalize=True)Modifying or adding new steps in the pipeline can't be easier. Let say you want to add a PCA before the classification step.
Just declare the sklearn pca in the import section
imports:
sklearn.linear_model :
- ElasticNet
sklearn.decomposition:
- PCAand add it in the pipeline :
pipeline:
- XdawnCovariances:
nfilter: 5
subelec: range(0,56,1)
- ElectrodeSelect:
nfilters: 5
nelec: 35
metric: "'riemann'"
- TangentSpace:
metric: "'logeuclid'"
tsupdate: False
- Normalizer:
norm: '"l1"'
- AddMeta:
- PCA:
n_components: 10
- ElasticNet:
l1_ratio: 0.5
alpha: 2e-4
normalize: Trueand then run the prediction.py (or cross_valid.py) script :
python prediction.py parameters.yaml
Voilà!