
A Rossmann é uma das maiores redes de drogarias da Europa com cerca de 56.200 funcionários e mais de 4.000 lojas. Em 2019 a Rossmann teve um faturamento de mais de € 10 bilhões na Alemanha, Polônia, Hungria, República Tcheca, Turquia, Albânia, Kosovo e Espanha. A companhia está em grande expansão e num ritmo elevado, com investimentos para serem utilizados nas mais diversas áreas. Dessa forma é muito importante que a gestão da empresa consiga fazer uma previsão de vendas para um determinado intervalo de tempo no futuro.
A rede Rossmann pretende renovar a fachada das lojas alterando sua identidade visual com intuito de melhorar sua imagem e vincular a marca à suas novas metas e valores. O setor financeiro da rede solicitou aos gerentes de cada loja que façam uma previsão das vendas diárias para seis semanas no futuro, para calcular o impacto financeiro da medida. As vendas de cada loja são influenciadas por muitos fatores, entre eles: promoções, concorrência, feriados, sazonalidade e localização. Com milhares de gerentes fazendo suas predições baseado nas circunstâncias de sua loja a acurácia dos resultados pode ser bastante variada e assim a tarefa se torna um grande desafio para a rede.
Para solucionar o problema acima a empresa disponibilizou o histórico de vendas de 1.115 lojas no Kaggle. O histórico consiste em um Dataset com os dados de vendas destas lojas de 2015 até 2017, lembrando que algumas lojas do dataset estão fechadas temporariamente para reforma. O dataset apresenta as seguintes features:
| Atributos | Descrição |
|---|---|
| Id | Identificador da transação |
| Store | Identificador único para cada loja |
| Sales | Volume de vendas no dia (Variável target) |
| Customers | Número de clientes no dia |
| Open | Indica se a loja está aberta ou fechada |
| StateHoliday | Indica feriado estadual, algumas lojas fecham nos feriados |
| SchoolHoliday | Indica feriado escolar |
| StoreType | Tipo da loja |
| Assortment | Indica o nível de variedade de produtos da loja |
| CompetitionDistance | Distância em metros do concorrente mais próximo |
| CompetitionOpenSince | Mês e ano que abriu o concorrente mais próximo |
| Promo | Indica se está ocorrendo alguma promoção na loja |
| Promo2 | Indica se o prazo final da promoção foi extendido |
| Promo2Since | Indica mês e ano que a loja iniciou a Promo2 |
| PromoInterval | Indica os intervalos consecutivos em que a Promo2 é iniciada |
Para desenvolvimento da solução utilizei um processo de modelagem cíclico chamado CRISP-DM. Este processo baseia-se em uma separação lógica e clara dos passos para desenvolvimento da solução e em sua estrutura cíclica, de forma que um ciclo consiste em percorrer todas as fases do desenvolvimento e a entrega ágil de uma solução (Minimum Viable Product). Sua natureza cíclica permite não só o refatoramento do código como também a formulação de outras hipóteses, criação de novas features, melhora dos modelos, fine tuning, etc.
Rascunho - CRISP
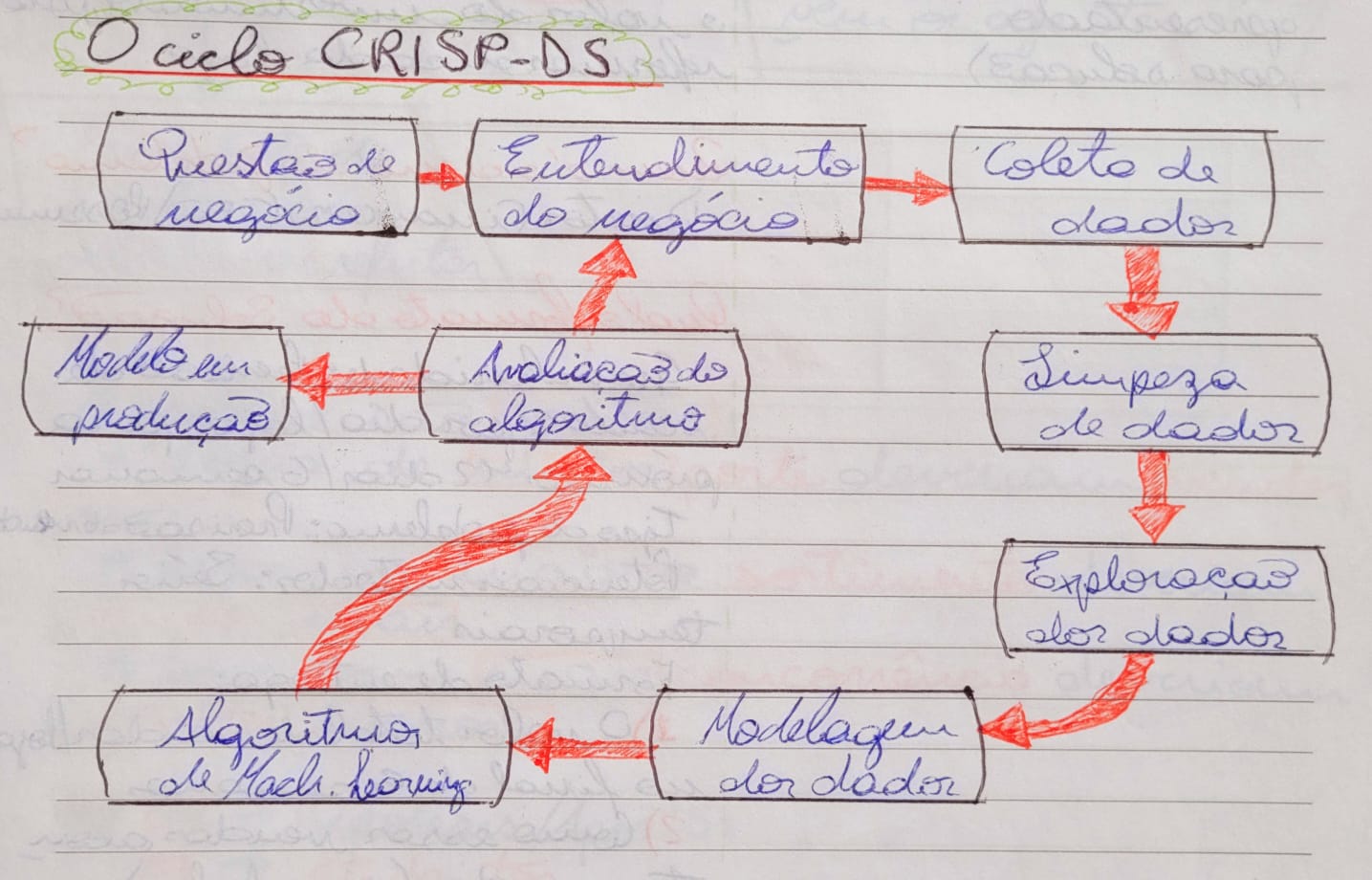
Mapa mental - CRISP
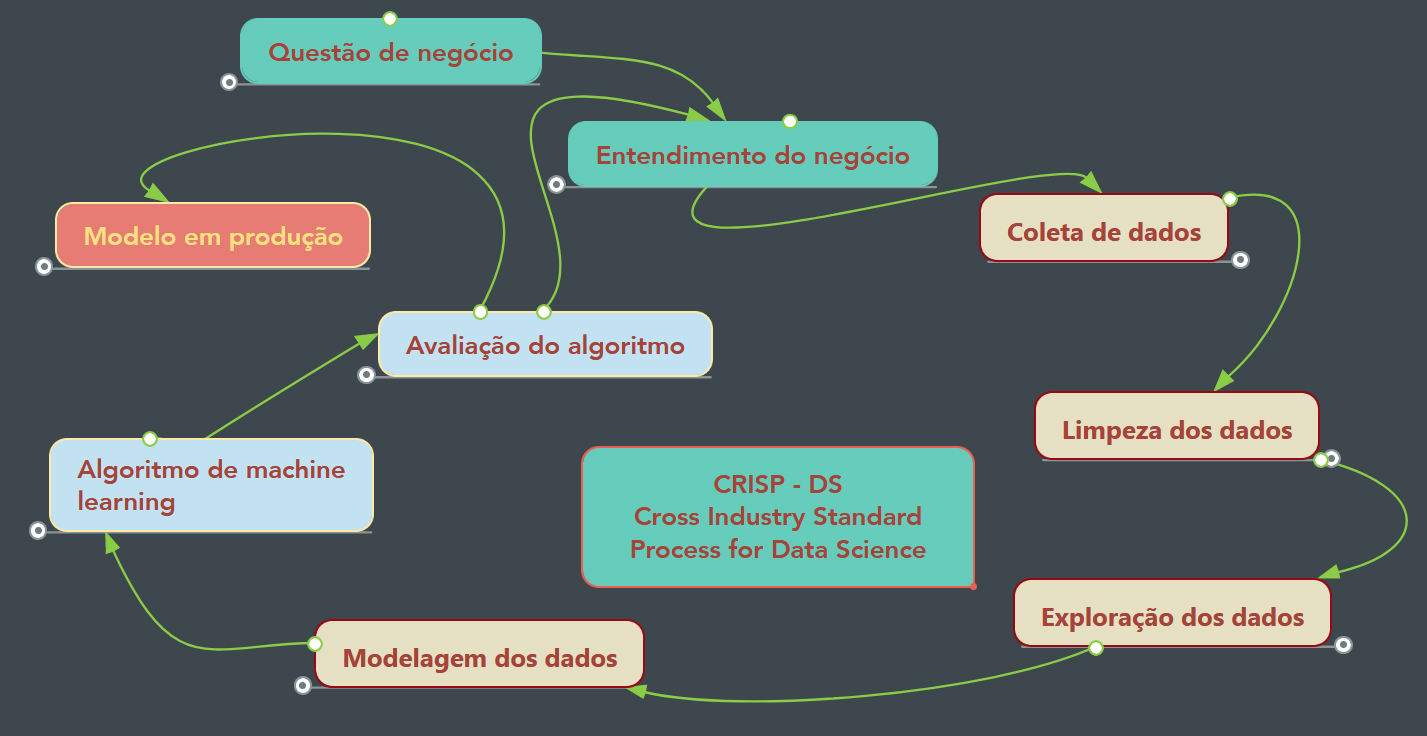
Mapa Completo - CRISP
 (mapas mentais criados usando a ferramenta Mindmeister)
(mapas mentais criados usando a ferramenta Mindmeister)
Como produto entregável minha decisão foi por disponibilizar o modelo desenvolvido em uma API e criar um Bot no aplicativo Telegram para consumir o serviço da API, tornando assim a consulta dinâmica e mobile friendly.
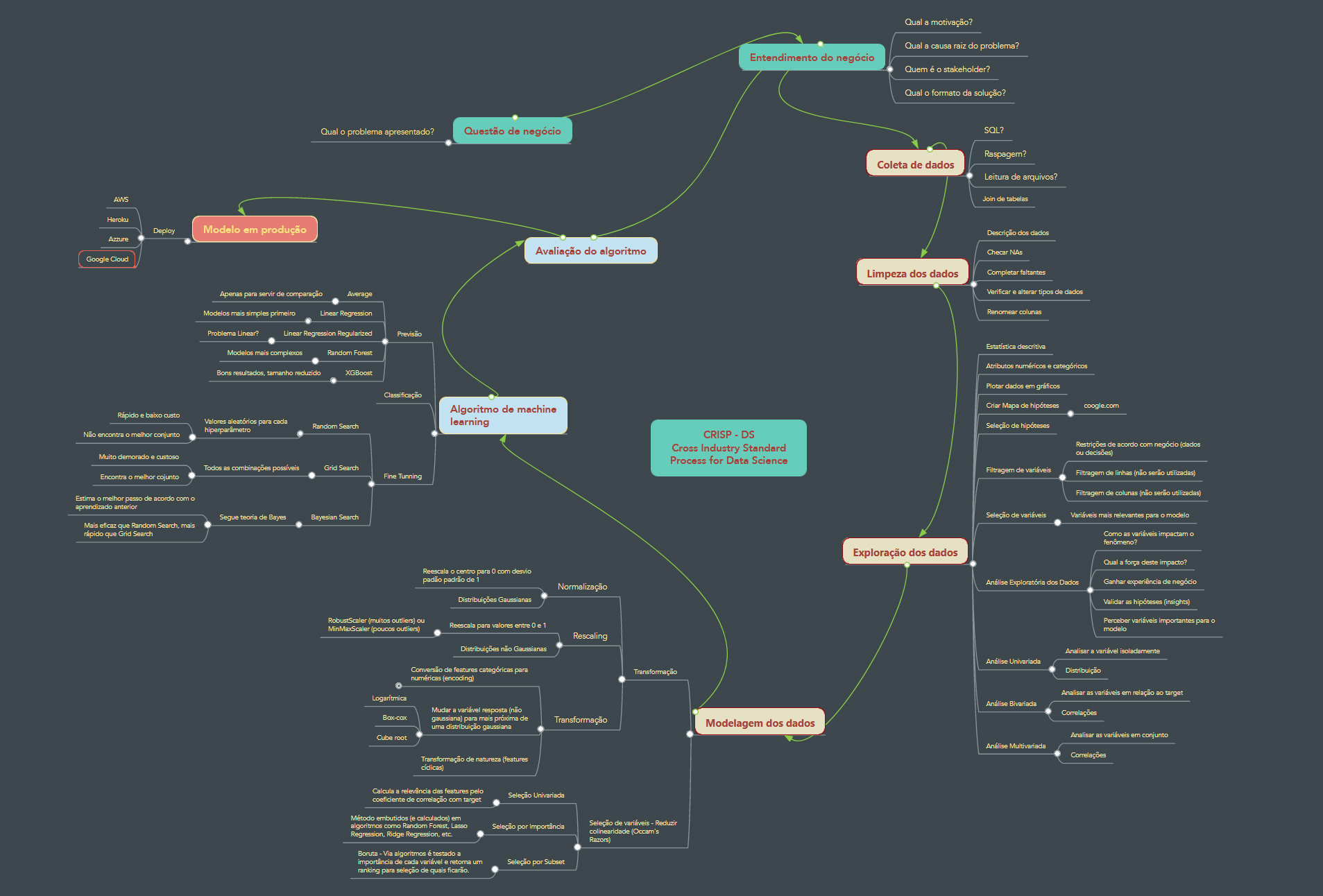
A sequência de tarefas realizadas no desenvolvimento da solução, seguindo a metodologia CRISP-DM, segue documentada abaixo:
Passo 01 - Descrição dos dados:
Esta é a etapa inicial do projeto para conhecer os dados e as dimensões do dataset, verificar os tipos das colunas, usar estatística descritiva para mensurar a média, moda, mediana, kurtosis, desvio patrão, skewness e range dos dados. Também foram separados os dados por tipos numéricos ou descritivos, alterado os nomes das colunas e feito o planejamento e o preenchimentos dos valores faltantes de forma a fazer sentido para o problema.
Passo 02 - Feature Engineering:
Na etapa de Engenharia das Features o foco foi em Separar os grupos de features por categorias intuitivamente (mapa mental) de forma a visualizar alguns insights e através de brainstorm criar uma lista empírica de hipóteses além de filtrar e eliminar as hipóteses que não possam ser provadas. À partir da lista final de hipóteses criar e derivar novas features para responder às perguntas e provar ou refutar estas hipóteses.
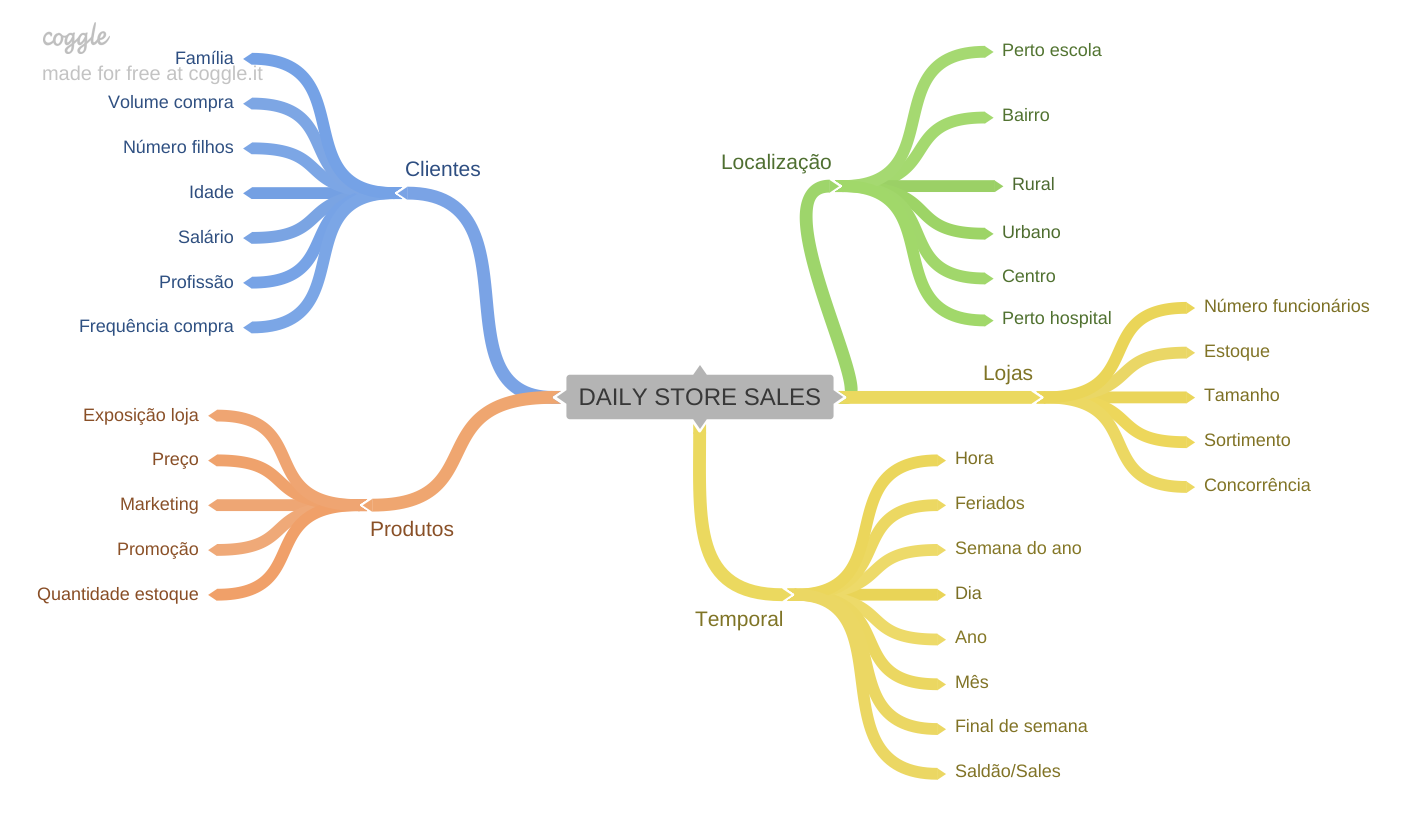 (mapas mentais criados usando a ferramenta Coggle)
(mapas mentais criados usando a ferramenta Coggle)
Passo 03 - Filtragem dos dados:
O objetivo desta etapa foi filtrar linhas e excluir colunas que não são relevantes para o modelo ou não fazem parte do escopo do negócio, como por exemplo, desconsiderar dias que as lojas não estavam operando e/ou que não houveram vendas.
Passo 04 - Análise Exploratória dos dados:
O objetivo desta etapa foi explorar os dados para encontrar insights, entender melhor a relevância das variáveis no aprendizado do modelo. Foi realizado análise das variáveis isoladamente (Análise variada), de cada variável em relação a variável reposta (Análise bivariada) e das variáveis em conjunto (Análise multivariada). Para tal foram usados histogramas para verificar a distribuição das variáveis, boxplot para análise de range e outliers, matriz de confusão para medir correlação, método de Kramer's V, entre outros. Também nessa fase foram provadas ou refutadas as hipóteses da etapa anterior além de ordenar as features por nível relevância para o modelo.
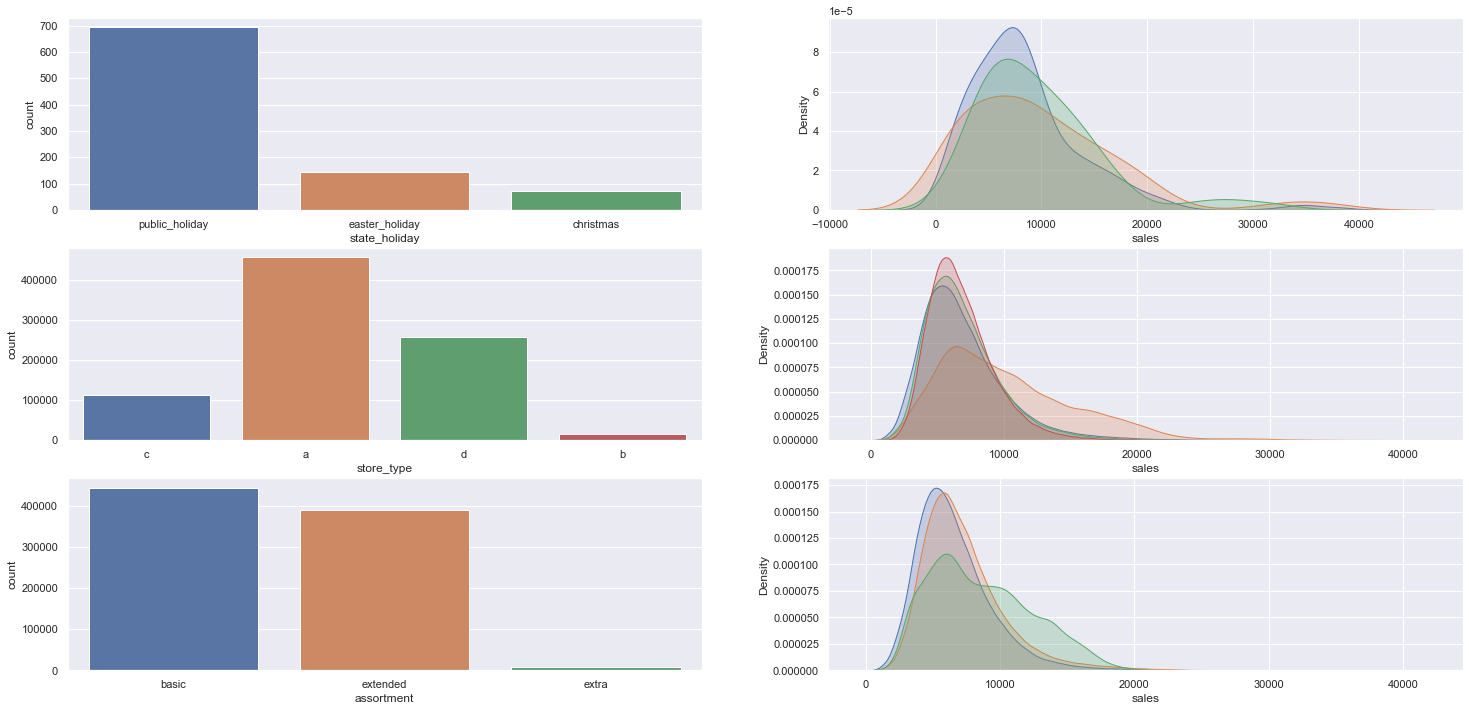
Passo 05 - Preparação dos dados:
Nessa etapa os dados foram preparados para o início das aplicações de modelos de machine learning. Foi utilizada técnicas como Rescaling usando MinMaxScaler e RobustScaler conforme a característica das features e seus respectivos outliers, foi utilizado Encoding das variáveis categóricas usando One Hot Encoding, Ordinal Encoding, Laber Encoding e transformação de natureza usando Seno e Coseno. Por último a transformação da variável resposta usando o método logarítmo.
Passo 06 - Seleção de Features:
Nesta etapa o objetivo foi selecionar os melhores atributos para treinar o modelo. Foi utilizado o algoritmo Boruta para fazer a seleção das variáveis, destacando as que tinham mais relevância para o fenômeno. Também foi incluído manualmente algumas features criadas no passo de Feature Enginnering que o Boruta não selecionou.
Passo 07 - Modelagem de Machine Learning:
Na modelagem foram realizados os treinamentos dos modelos de machine learning selecionados para o problema em questão:
- Average model
- Linear regression
- Lasso
- Random Forest
- XGBoost
Na primeira parte da etapa foi realizado a avaliação simples do modelo (Single Performance) e na segunda parte foi aplicado o método de Cross Validation. O método de validação cruzada consiste em separar os dados de teste em dois conjuntos: conjunto de teste e o menor de validação, após treinar e medir o desempenho do modelo esses dois conjuntos são redimensionados de forma a testar e validar o modelo em todas as porções dos dados.
Single Performance:
| Model Name | MAE | MAPE | RMSE |
|---|---|---|---|
| XGBoost Regressor | 687.46 | 0.10 | 997.97 |
| Random Forest | 679.69 | 0.10 | 1010.61 |
| Average Model | 1354.80 | 0.46 | 1835.14 |
| Linear Regression | 1867.09 | 0.29 | 2671.05 |
| Linear Regression Regularized | 1891.70 | 0.29 | 2744.45 |
Cross Validation Performance
| Model Name | MAE | MAPE | RMSE |
|---|---|---|---|
| Random Forest | 837.97 +/- 218.4 | 0.12 +/- 0.02 | 1256.45 +/- 318.73 |
| XGBoost Regressor | 905.77 +/- 182.34 | 0.13 +/- 0.02 | 1304.21 +/- 266.28 |
| Linear Regresion | 2081.73 +/- 295.63 | 0.3 +/- 0.02 | 2952.52 +/- 468.37 |
| Lasso | 2116.38 +/- 341.5 | 0.29 +/- 0.01 | 3057.75 +/- 504.26 |
Dentre os modelos testados houve pequena diferença nas métricas do Random Forest e do XGBoost, que foram os dois melhores. A escolha do modelo XGBoost foi baseado, entre outros fatores menores, no tempo de processamento do algoritmo, que é muito menor que o Random Forest, significando redução de custos de processamento e cloud.
Passo 08 - Hyperparameter Fine Tuning:
Nesta etapa foram analisados os métodos de fine tuning de hiper parâmetros: Random Search, Grid Search e Bayesian Search. A decisão por usar o Random Search foi baseada no tempo de processamento e nos custos relacionados, haja visto que usando o Random Search com 10 kfolds (iterações) levou mais de 15 horas em um PC I3 com 16gb de memória RAM, em um ambiente corporativo isso seria traduzido em custos com serviços de Cloud por exemplo. Outro ponto importante é ressaltar a natureza cíclica do método CRISP, que em outras iterações permite mudar o método de fine tuning e até o modelo de machine learning selecionado.
| Model Name | MAE | MAPE | RMSE |
|---|---|---|---|
| XGBoost | 1774.97 +/- 190.59 | 0.25 +/- 0.01 | 2544.36 +/- 255.35 |
| XGBoost | 818.38 +/- 141.72 | 0.11 +/- 0.01 | 1185.16 +/- 207.73 |
| XGBoost | 865.39 +/- 122.18 | 0.12 +/- 0.01 | 1249.63 +/- 188.49 |
| XGBoost | 929.53 +/- 149.83 | 0.13 +/- 0.01 | 1340.54 +/- 210.67 |
| XGBoost | 1027.43 +/- 121.43 | 0.14 +/- 0.01 | 1470.98 +/- 159.45 |
| XGBoost | 1768.97 +/- 192.54 | 0.25 +/- 0.01 | 2537.99 +/- 262.93 |
| XGBoost | 4108.73 +/- 493.42 | 0.5 +/- 0.02 | 5048.82 +/- 600.72 |
| XGBoost | 945.64 +/- 129.29 | 0.13 +/- 0.01 | 1368.71 +/- 189.71 |
| XGBoost | 1791.7 +/- 197.04 | 0.25 +/- 0.01 | 2567.88 +/- 271.0 |
| XGBoost | 782.18 +/- 124.32 | 0.11 +/- 0.01 | 1134.51 +/- 185.33 |
Passo 09 - Tradução e interpretação de erros:
O objetivo dessa etapa foi de fato demonstrar o resultado do projeto, verificar e estudar as métricas de erros utilizadas e observar se o modelo está subestimando ou superestimando suas previsões. Aqui também é disponibilizado o resultado do modelo para a equipe de negócios usando moeda corrente, percentuais e indicadores de Melhores/Piores cenários.
Amostra do resultado do modelo em Euros:
| id_loja | Predição | Pior cenário | Melhor cenário | Erro | Erro % |
|---|---|---|---|---|---|
| 1 | € 159.820,91 | € 159.545,94 | € 160.095,87 | € 274,97 | 6.2 % |
| 2 | € 175.638,09 | € 175.291,62 | € 175,984,57 | € 346,48 | 7.3 % |
| 3 | € 264.181,34 | € 263.633,38 | € 264.729,31 | € 547,97 | 8.1 % |
| 4 | € 338.874,09 | € 337.950,47 | € 339.797,71 | € 923,62 | 8.9 % |
| 5 | € 173.785,28 | € 173.402,96 | € 174.167,61 | € 382,33 | 8.7 % |
Resultado total:
| Cenário | Valores |
|---|---|
| Predições | € 282.796.384,00 |
| Pior cenário | € 282.097.185,79 |
| Melhor cenário | € 283.495.623,37 |
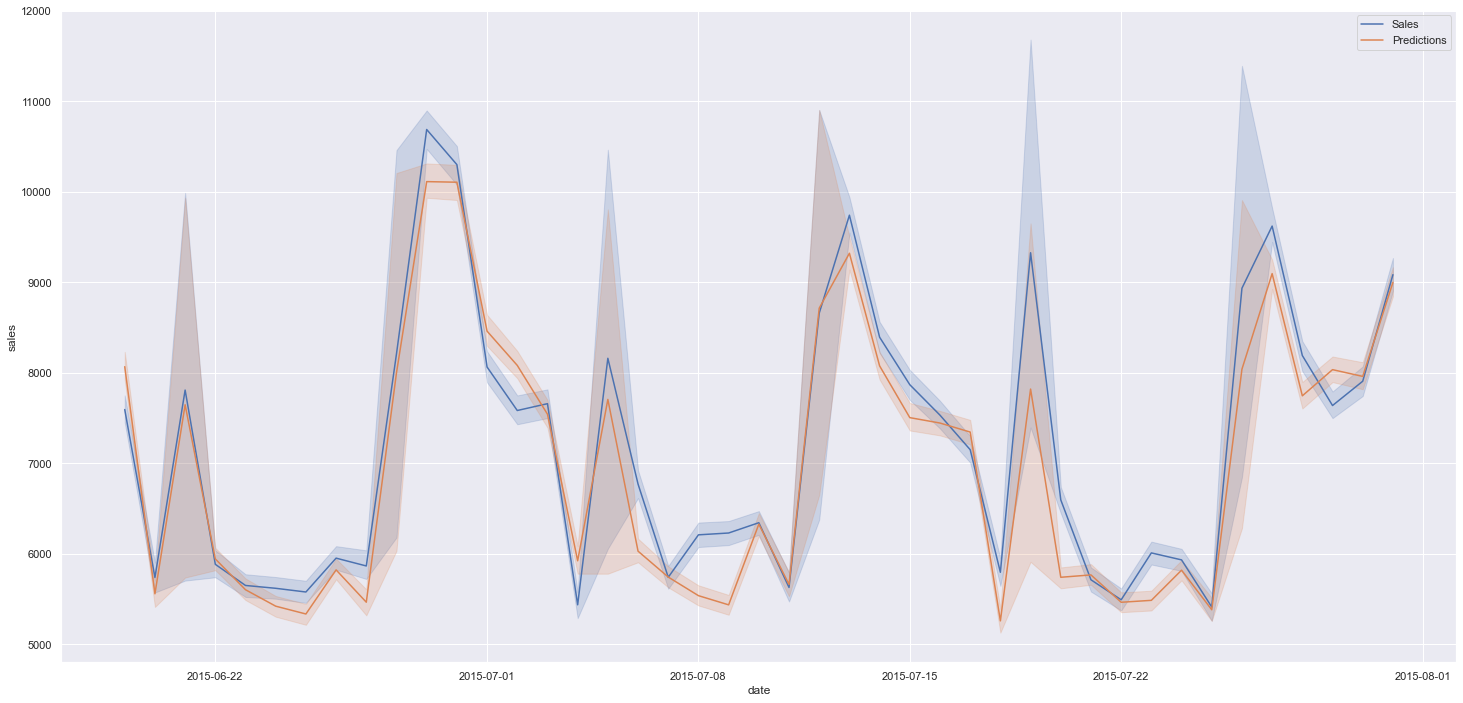
Previsão x Vendas reais
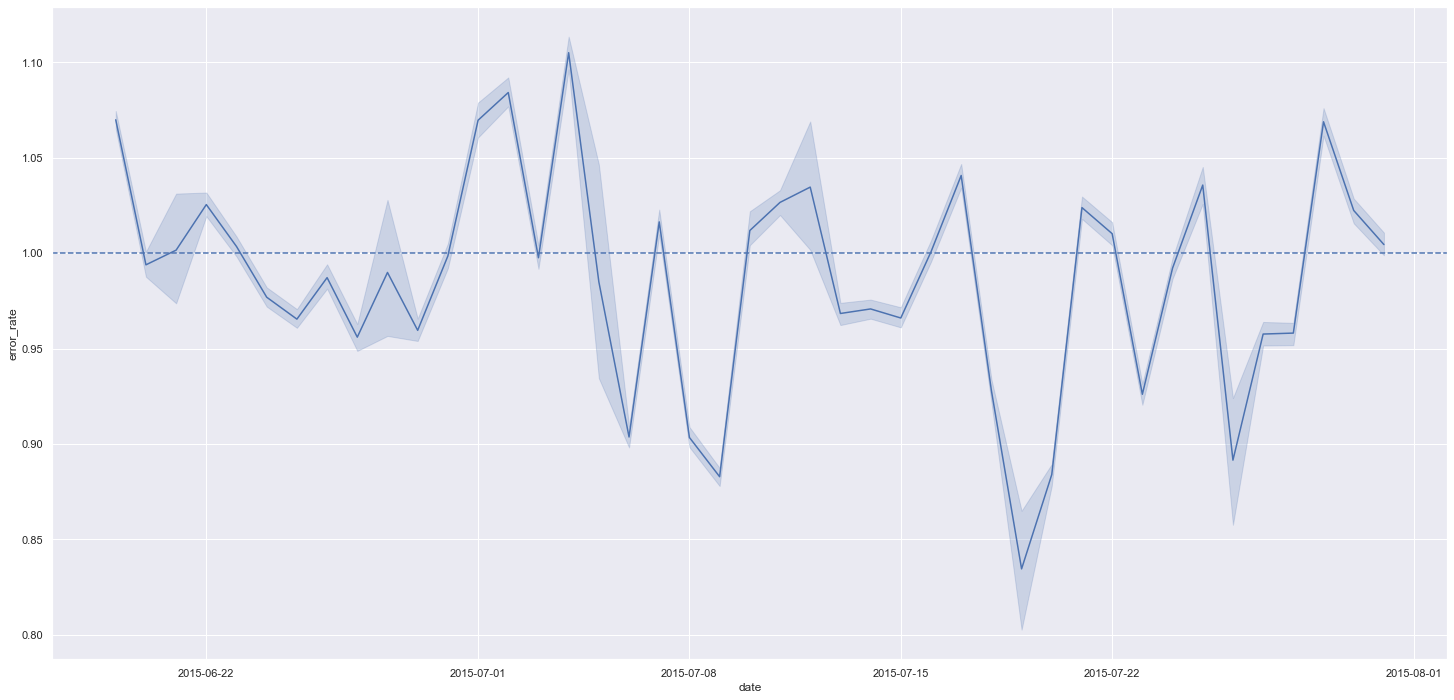
Sobrestimação e Superestimação
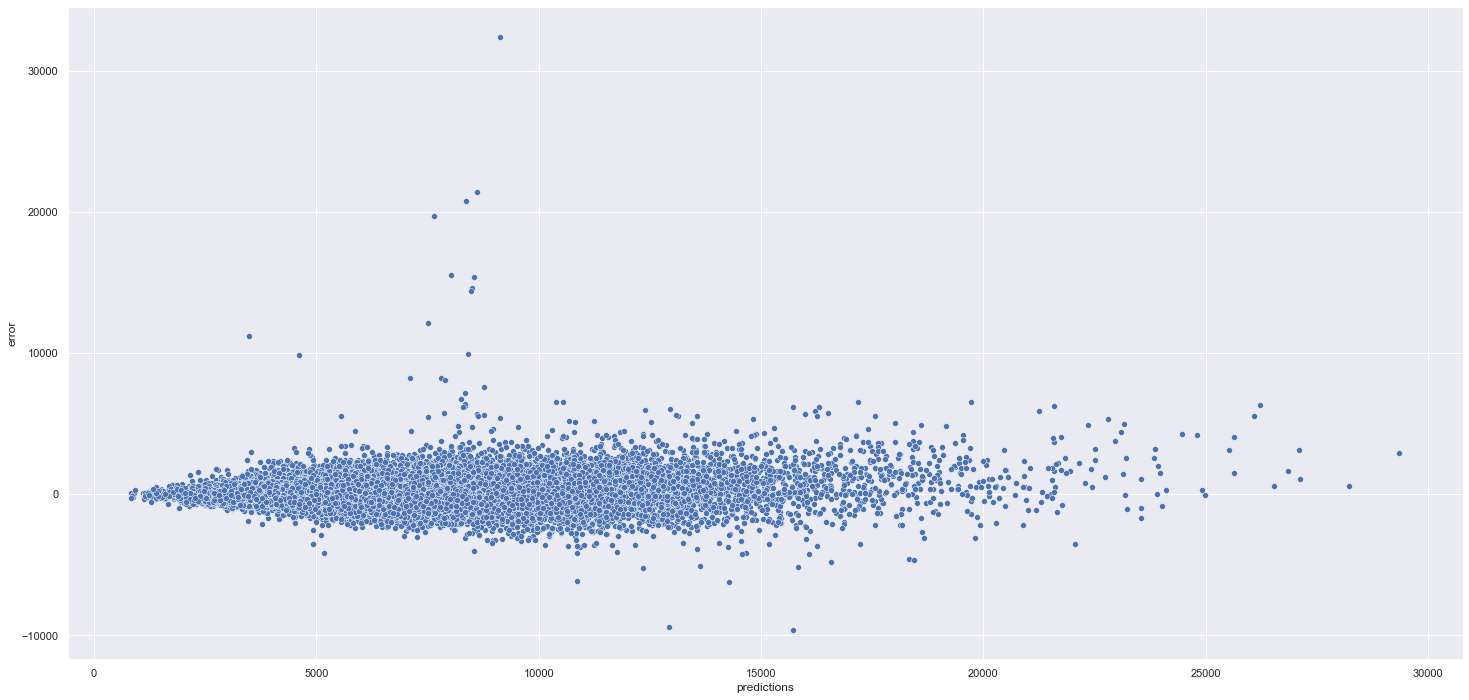
Análise de resíduos
Passo 10 - Deploy do modelo em produção:
Após execução bem sucedida do modelo o objetivo é publica-lo em um ambiente de nuvem para que outras pessoas ou serviços possam usar os resultados para melhorar a decisão de negócios. A escolha foi criar uma API usando a plataforma de nuvem Heroku e os passos foram:
- Salvar o modelo já treinado e com todos os ajustes finos de hiper parâmetros para não ter de realizar no ambiente de produção;
- Cria uma classe com os métodos de limpeza, transformação, encoding e predição para encapsular o funcionamento do aplicativo;
- Cria uma aplicação em Flask para ser o controler da arquitetura que vai receber as requisições, encaminhar para o modelo processar e devolver o resultado via response;
- Criar a estrutura das pastas, criar os arquivos de configurações necessárias e publicar na ferramenta de cloud Heroku.
Planejando o deploy
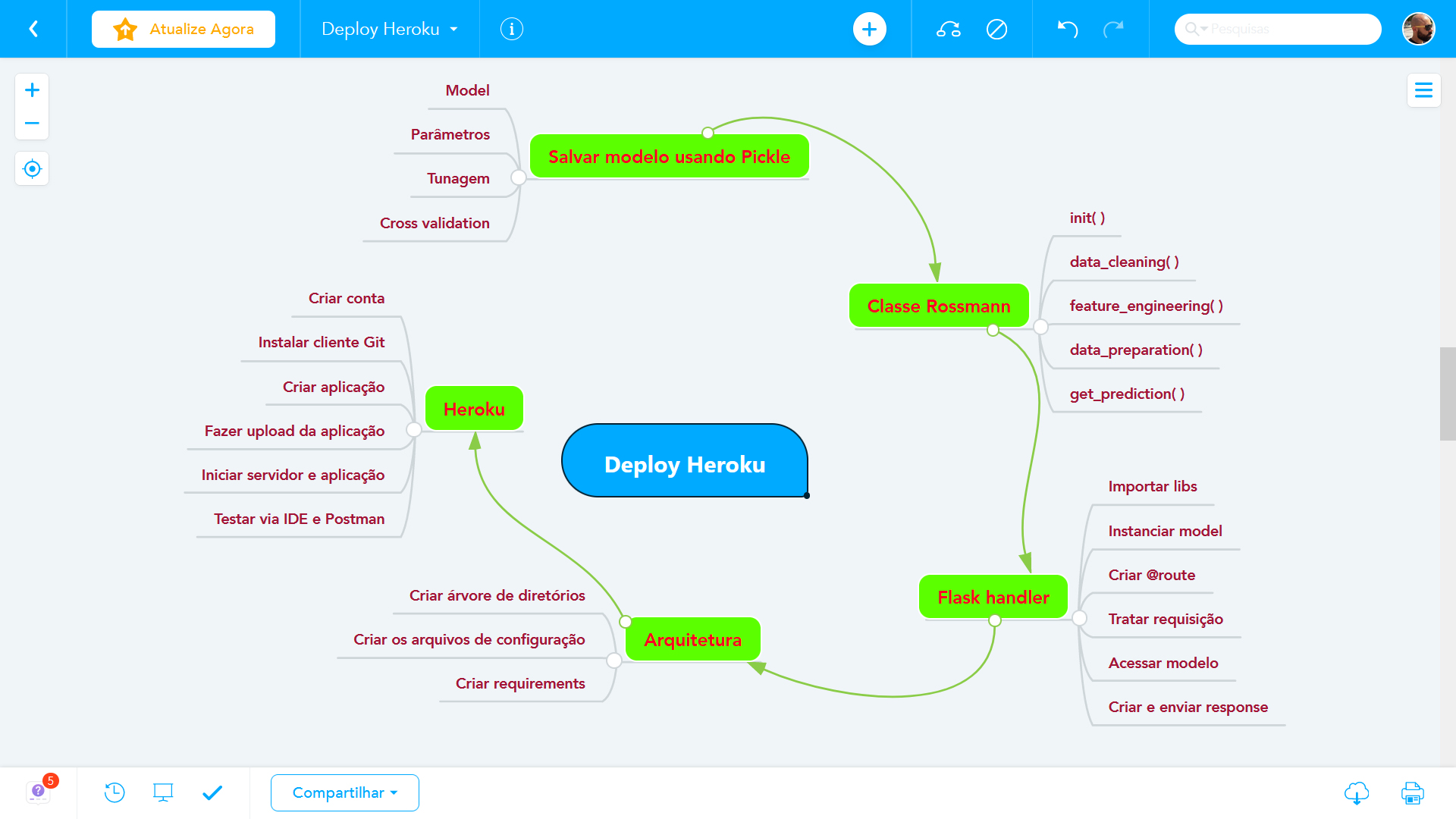
Passo 11 - Bot do Telegram:
Em desenvolvimento
A etapa final do projeto é criar um bot no app de mensagens - Telegram, que possibilita consultar as previsões a qualquer momento e lugar.
No passo de engenharia de features foram levantadas algumas hipóteses empíricas baseadas no problema de negócio e foram criadas/derivadas também algumas features para que essas hipóteses fossem respondidas. Na etapa da análise as hipóteses puderam ser provadas ou refutadas. Segue abaixo algumas destas hipóteses:
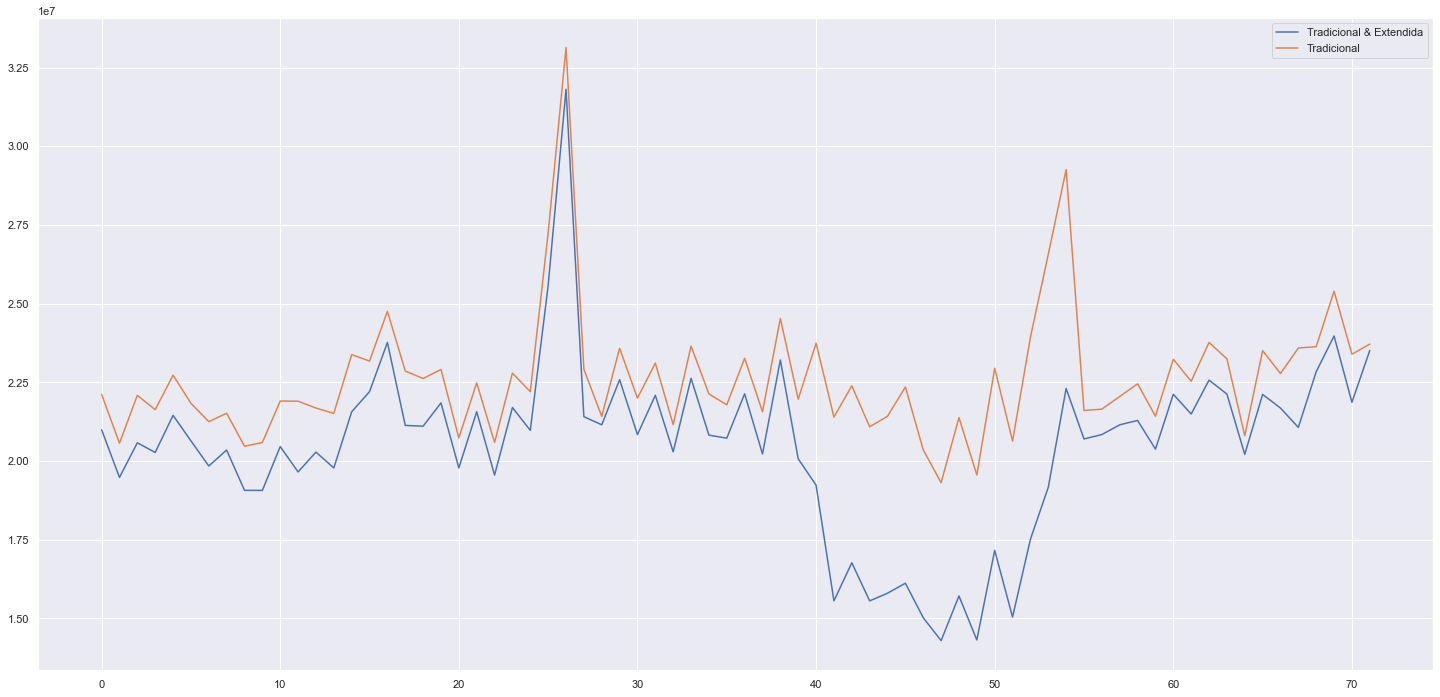
Hipótese 1: Lojas com mais dias de promoção deveriam vender mais. Refutada, lojas com promoção estendida vendem menos que com promoção tradicional.
Promoções vs Vendas
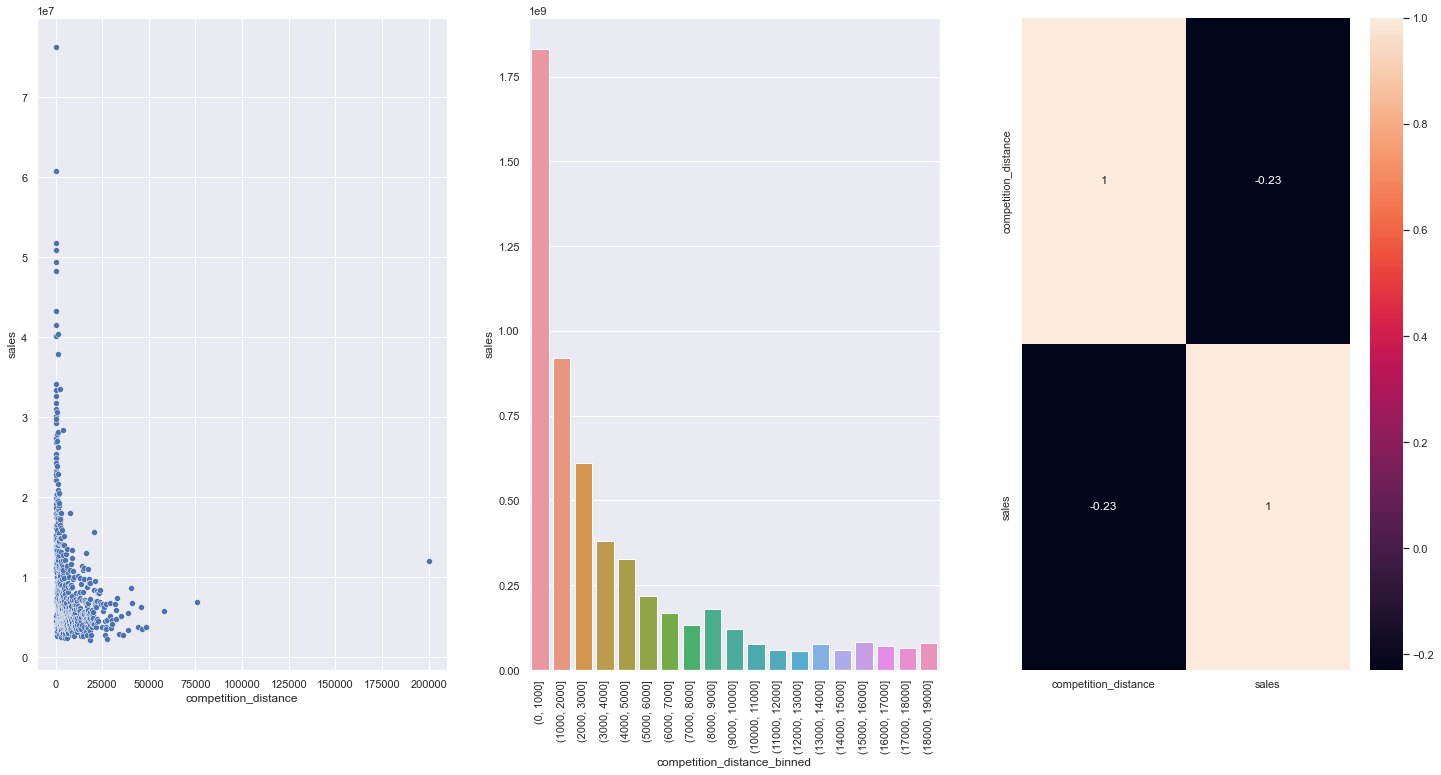
Hipótese 2: Lojas com concorrentes mais próximos deveriam vender menos. Refutada, lojas com concorrência próxima vendem mais.
Vendas vs Distância do concorrente
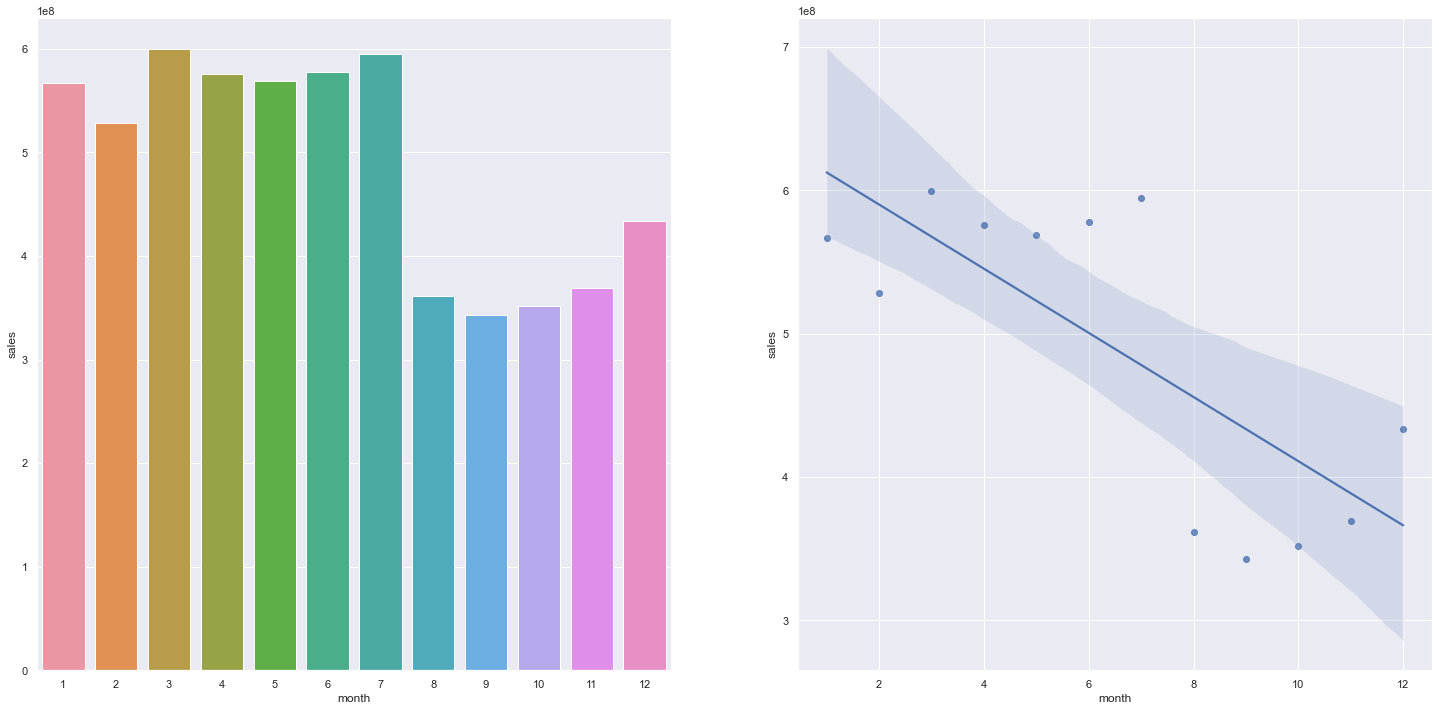
Hipótese 3: Lojas devem vender mais no segundo semestre. Refutada, lojas vendem menos no segundo semestre do ano.
Vendas por Mês
(Demais insights podem ser consultados nos notebooks do projeto)
Foram utilizados cinco modelos para aplicar sobre os dados do projeto, sendo três lineares e dois não lineares. O modelo de média simples foi inserido para servir de referência (baseline) na medição do desempenho dos demais. Os modelos lineares servem para avaliar a complexidade de aprendizado do conjunto de dados usando o princípio de Occan's Razor que prega a busca sempre pelo modelo mais simples que solucione o problema, em sintonia com a filosofia do MVP. A performance dos modelos lineares mostrou a necessidade de modelos mais complexos.
Modelos Lineares:
- Média
- Linear Regression
- Linear Regression Regularized
Modelos Não Lineares:
- Random Forest Regressor
- XGBoost Regressor
Comparação da performance dos modelos:
| Model Name | MAE CV | MAPE CV | RMSE CV |
|---|---|---|---|
| Random Forest Regressor | 842.56 +/- 220.07 | 0.12 +/- 0.02 | 1264.33 +/- 323.29 |
| XGBoost Regressor | 1048.45 +/- 172.04 | 0.14 +/- 0.02 | 1513.27 +/- 234.33 |
| Average Model | 1354.80 | 0.45 | 1835.13 |
| Linear Regression | 2081.73 +/- 295.63 | 0.3 +/- 0.02 | 2952.52 +/- 468.37 |
| Lasso | 2116.38 +/- 341.5 | 0.29 +/- 0.01 | 3057.75 +/- 504.26 |
Performance final do modelo escolhido após Hyperparameter Fine Tuning:
| Model Name | MAE | MAPE | RMSE |
|---|---|---|---|
| XGBoost Regressor | 673.394631 | 0.097298 | 965.731681 |
O resultado final do projeto foi muito satisfatório, sendo entregue a solução necessária para o problema de negócio. Apenas um número muito pequeno de lojas mostrou necessitar de ajustes futuros por destoar da média das predições, conforme pode ser visto no gráfico abaixo, mas isso pode ser facilmente corrigido nas outras iterações do CRISP. Em outros ciclos do projeto também poderão ser melhorados os modelos, o tuning dos parâmetros e a elaboração de novas hipóteses.
Previsões vs Erro MAPE
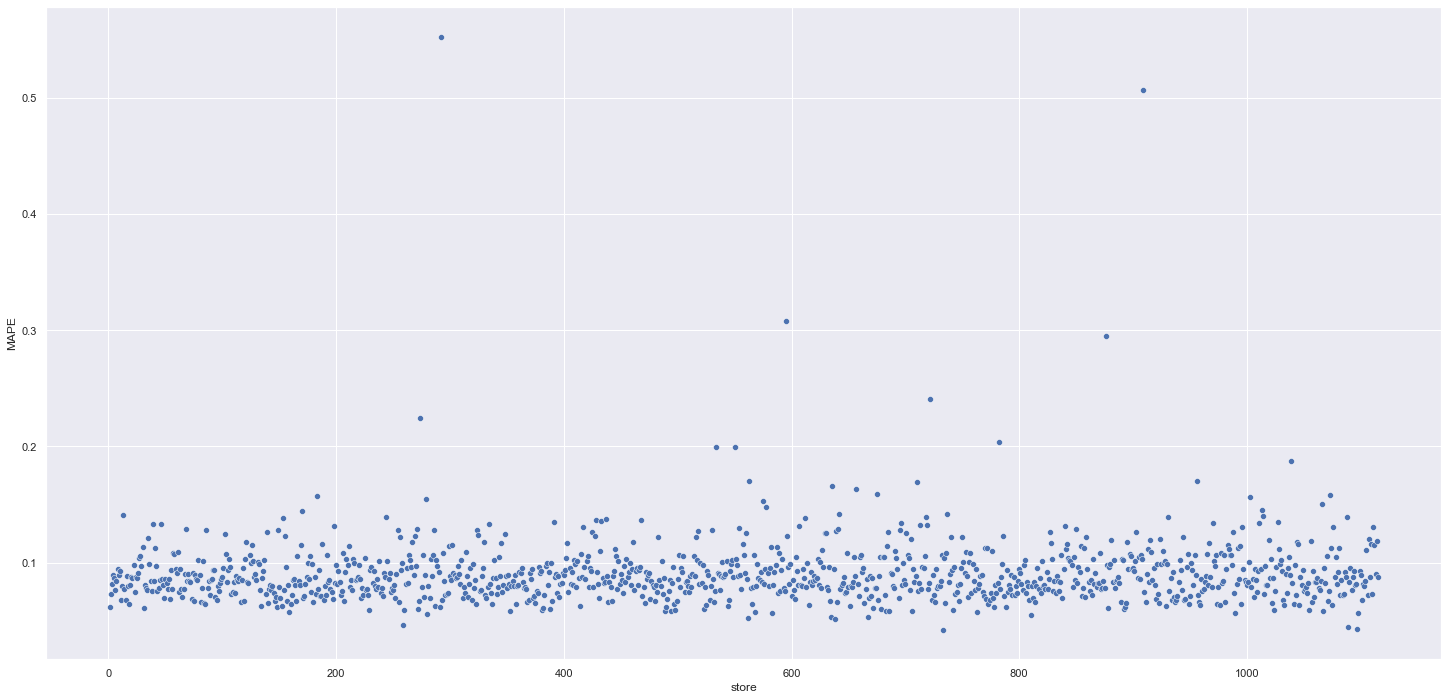
A maior parte das lojas tiveram o erro MAPE muito próximo do erro performado no modelo - MAPE Error de 9%
Como indicado no resumo prévio do projeto, o resultado que pode ser obtido utilizando-se do modelo, considerando o melhor e pior cenário, é o seguinte:
| Scenarios | Values |
|---|---|
| predictions | US$ 282.662.848,00 |
| worst scenario | US$ 281.907.880,11 |
| best scenario | US$ 283.417.771,65 |
Podemos observar a performance do modelo avaliando a relação entre as vendas (dados de teste) e as predições:
Vendas reais vs Previsões
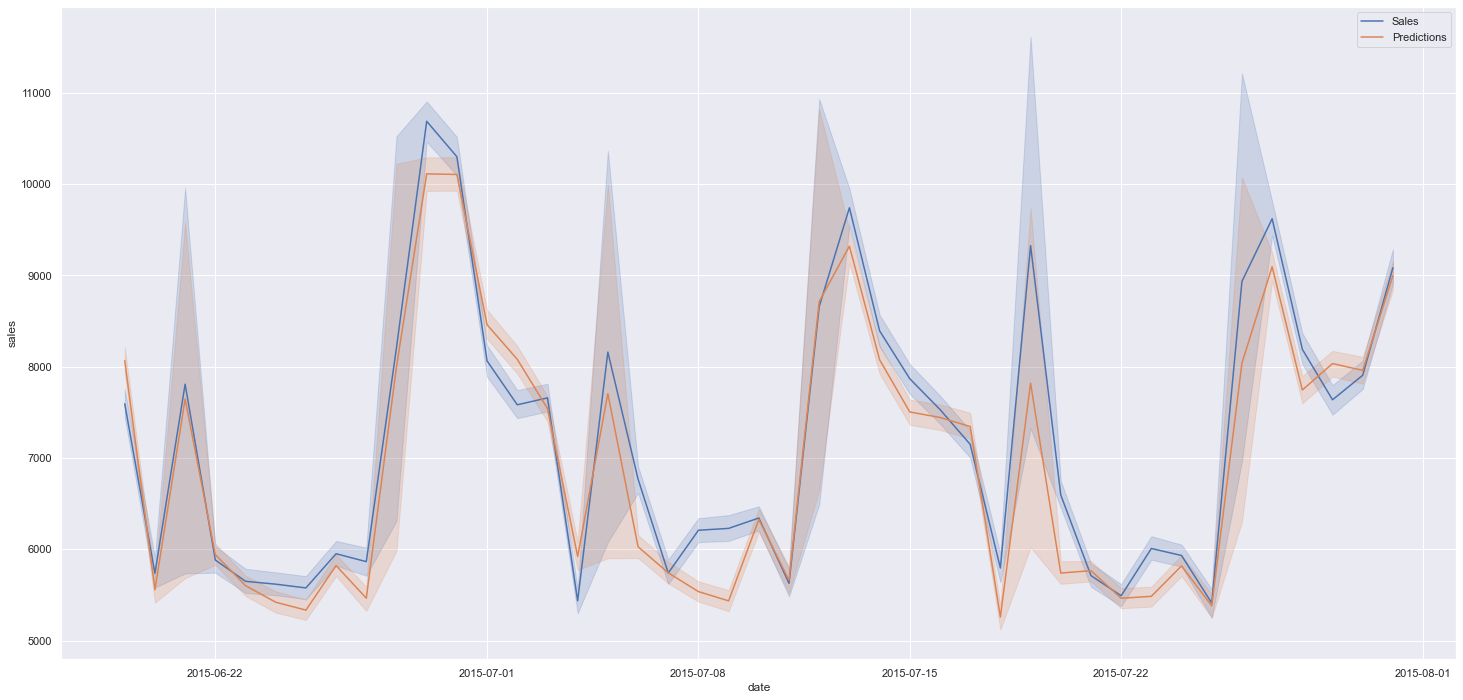
O projeto desenvolvido foi concluído com êxito, onde foi possível projetar as vendas das próximas semanas para que o CFO tenha informações reais para estimar o budget das lojas, podendo consultar em tempo real cada predição.
O deploy do modelo desenvolvido e da aplicação do Bot do Telegram foram construídos no ambiente em nuvem do Heroku e estão em funcionamento.
Toda documentação do projeto pode ser consultada no repositório, incluindo os notebooks desenvolvidos e todos os scripts finais para as aplicações web.
Começar um segundo ciclo do CRISP para analisar o problema sob o ponto de vista da experiência adquirida durante o pipeline de desenvolvimento procurando novas abordagens. Possíveis pontos à serem revisitados:
- Nova abordagem no tratamento de dados faltantes;
- Fazer Rescaling e Encoding utilizando métodos diferentes;
- Criar novas hipóteses;
- Criar/derivar novas features;
- Usar métodos mais robustos para seleção dos melhores Hiper parâmetros;
- Testar diferentes algoritmos de Machine Learning.
Este repositório contém código para a previsão de vendas da rede de drogarias Rossmann. Os dados usados estão disponíveis no Kaggle. Todas as informações adicionais foram criadas para dar contexto ao problema.