Wine Dataset Analysis by using Python
Problem arises in the need of wine classification. We need to classify the wines according to its ingredients. Because we need to diverse wines to match with the meal that goes along the best.
We decide on three types for the classification system. First one goes well with the meal that includes white meat, second one goes well with the meal that includes red meat, third one goes well with both.
We believe that best way to solve this problem is to use one of the supervised classification models of wines according to its ingredients.
These data are the results of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars. The analysis determined the quantities of 13 constituents found in each of the three types of wines.
The features are depicted as below in order:
Alcohol, Malic acid, Ash, Alcalinity of ash, Magnesium, Total phenols, Flavanoids, Nonflavanoid phenols, Proanthocyanins, Color intensity, Hue, OD280/OD315 of diluted wines, Proline
The features are numerical values of chemicals inside of the wine. All attributes are continuous. There are no missing values in the dataset.

Statistical Descriptions of the Data:

We believe all the features are essential to classify and should be used for the model training.
We have used train_test_split method from sklearn.model_selection with default parameters. Therefore, we picked randomly, and it consist of %20 of the total dataset. As stated, “Data Analysis” part, we do not have any missing values nor categorical features to handle. We normalized the values due to fact that size of scale between features are way too much.
We have used the formula above within the sklearn.preprocessing package. Model Selection and Training Selected Models: Logistic Regression, Decision Tree, Gaussian Naïve Bayes
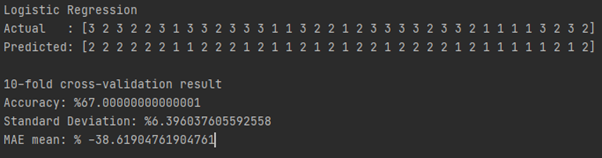
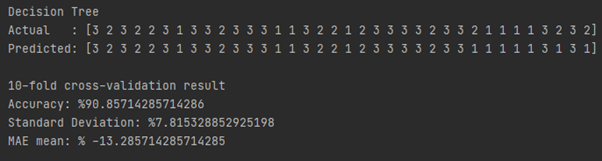
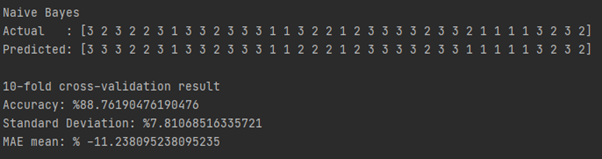
We have selected the best result according to accuracy scores. Therefore, we have picked decision tree model.
We have used GridSearchCV to fine tune our model. Parameters are as given below: criterion: entropy, gini max_depth: 3-9 min_samples_leaf: 1-9

Accuracy increased from %90.86~ to %93.05~ thanks to fine-tuning step.
We have used accuracy, precision, recall, F-score, confusion matrix methods from sklearn.metrics to measure the performance. Results can be seen at below.
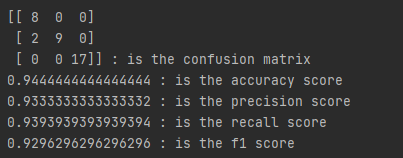
We tried different models to classify our dataset. We believe decision tree model outperforms others in this dataset. Therefore, we fine-tuned that and tested again. Consequently, we achieved around %94 accuracy as a best result.