Hey guys !! Back with another automation article. In this article you will find that how we can launch a wordpress application connected with MySql database inside kubernetes Cluster on AWS and automation using Ansible.

Now to start this project we need to look at the required steps: Steps to do this project: Launch 3 (t2.micro) ec2-instances on AWS using Ansible. You can use Terraform also but all the process has been done using ansible so that’s why i included ansible here. I have launched an extra instance on AWS that has ansible installed in it and by that i provisoined above three instances. For installing ansible you can visit here. So lets launch the ec2-instances on AWS using Ansible. Below is the explanation of each services launched on AWS. Below are the services we need to launch on AWS using Ansible
- Create a VPC (Virtual Private Cloud)
- Create subnets in that VPC.
- Create an internet gateway.
- Create routing table.
- Create an internet gateway.
- Creating security group.
- Launch ec2-instances in that subnet of respective VPC.
So, let's create one by one,
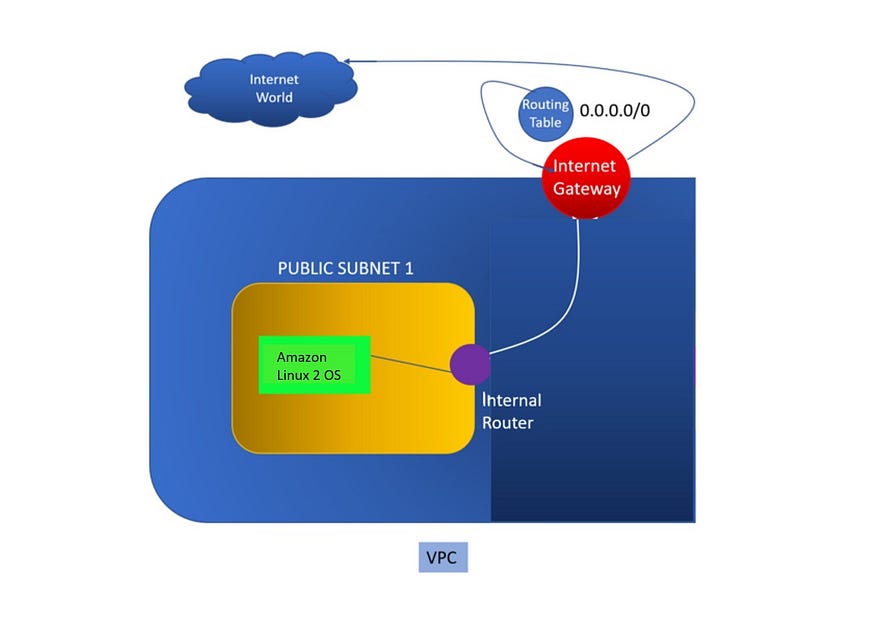
We need to use the respective module given by the ansible to create vpc. Here we have ec2_vpc_net. This will create a VPC in your respective region. Here, i have given ap-south-1 as my avialibility-zone. You need to provide access_key, secret_key name of the vpc, cidr_block, state, etc and all the values are provided in respective variable. At the last i have register the value of the VPC after creating in to a variable ec2_vpc_net_result. so, i can use id of vpc in other services.
!(vpc_archtecture)[https://miro.medium.com/max/875/1*qJEgyV7u8Ca1y4iMwoTulg.jpeg]
ec2_vpc_net:
aws_access_key: "{{ aws_access_key }}"
aws_secret_key: "{{ aws_secret_key }}"
name: "{{ vpc_name }}"
cidr_block: "{{ vpcCidrBlock }}"
region: "{{ region }}"
# enable dns support
dns_support: yes
# enable dns hostnames
dns_hostnames: yes
tenancy: default
state: "{{ state }}"
register: ec2_vpc_net_result

To create a subnet inside above VPC we need to provide the id of the VPC to the subnet which we are creating. You need to specify which availability zones we are creaying in that vpc. A subnet must have a cidr block within the range of cidr block of vpc. If you wanted to have mublic ip then you need to include map_public as yes and all the values of subnets in a variable subnet_result.
- name: create ec2 vpc subnet
ec2_vpc_subnet:
aws_access_key: "{{ aws_access_key }}"
aws_secret_key: "{{ aws_secret_key }}"
vpc_id: "{{ ec2_vpc_net_result.vpc.id }}"
region: "{{ region }}"
az: "{{ zone }}" # az is the availability zone
state: "{{ state }}"
cidr: "{{ subNetCidrBlock }}"
# enable public ip
map_public: yes
resource_tags:
Name: "{{ subnet_name }}"
register: subnet_result

Now we need to create internet gateway that will take our requests to internet world. The IG will be connected to our vpc. if you are creating VPC then only one IG is required. you need to specify name of the IG, the region in which your vpc is located and the state should be present. The whole output is register into a variable igw_result.
# create an internet gateway for the vpc
- name: create ec2 vpc internet gateway
ec2_vpc_igw:
aws_access_key: "{{ aws_access_key }}"
aws_secret_key: "{{ aws_secret_key }}"
vpc_id: "{{ ec2_vpc_net_result.vpc.id }}"
region: "{{ region }}"
state: "{{ state }}"
tags:
Name: "{{ igw_name }}"
register: igw_result

The routing table is the path we have to specify to the vpc. Above is the architecture i have mentioned. In that diagram you can get it easily. As already mentioned that routable will be connected between vpc and IG so, we need to give the id of IG as well as vpc. The state should be present and the region you need to specify in which region you want to create routing table. The output of the routing table is stored in public_route_table.
- name: create ec2 VPC public subnet route table
ec2_vpc_route_table:
aws_access_key: "{{ aws_access_key }}"
aws_secret_key: "{{ aws_secret_key }}"
vpc_id: "{{ ec2_vpc_net_result.vpc.id }}"
region: "{{ region }}"
state: "{{ state }}"
tags:
Name: "{{ route_table_name }}"
subnets: [ "{{ subnet_result.subnet.id }}" ]
# create routes
routes:
- dest: "{{ destinationCidrBlock }}"
gateway_id: "{{ igw_result.gateway_id }}"
register: public_route_table

To secure the services we want to run in the respective OS we need to create a firewall. So that our application running on a particular port no. would be safe. Also to create a security group in AWS is compulsory you cannot deny that. ec2_group is the module in ansible to creat security group. You need to specify the vpc id i.e in which vpc you want to create a security group also on which port your services are running and who will access it. So here i have mentioned that my services are running on any one of the port and all public IP can access my services. Hence i have mentioned below in proto as all. Also you need to give cidr ip that is stored inside variable port22CidrBlock. The output of the security group is stored inside variable security_group_results.
ec2_group:
aws_access_key: "{{ aws_access_key }}"
aws_secret_key: "{{ aws_secret_key }}"
vpc_id: "{{ ec2_vpc_net_result.vpc.id }}"
region: "{{ region }}"
state: "{{ state }}"
name: "{{ security_group_name }}"
description: "{{ security_group_name }}"
tags:
Name: "{{ security_group_name }}"
rules:
- proto: all
cidr_ip: "{{ port22CidrBlock }}"
rule_desc: allow all traffic
register: security_group_results

Now after creating all the required services we can launch no. of ec2-instances. Here i am launching three instances (2 instances will be behaving as a slave and 1 will be as a master). All the instances is launched using t2.micro instance type. t2.micro is comes under free tier and you can launch without free of cost. you need to specify the id’s subnet i.e in which subnet we are goin to launch the instance. Also the group_id i.e security group. You also need to mention the count of instances you will be launching. As i have used loop at the end of the below code so that loop will search Os_Names variable which i have created inside the main playbook. The Os_Names variable consists of three variables i.e K8S_Master_testing, K8S_Slave1_testing, K8S_Slave2_testing so the loop will run three times and will launch three instances respectively. Also you need to specify the keypair in the key_name variable.
- name: "provisioning OS on AWS using Ansible"
ec2:
key_name: "ansiblekey"
instance_type: "t2.micro"
image: "ami-08e0ca9924195beba"
wait: yes
count: 1
vpc_subnet_id: "{{ subnet_result.subnet.id }}"
assign_public_ip: yes
region: "ap-south-1"
state: present
group_id: "{{ security_group_results.group_id }}"
aws_access_key: "{{aws_access_key}}"
aws_secret_key: "{{aws_secret_key}}"
instance_tags:
Name: "{{ item }}"
loop: "{{ Os_Names }}"
Now you can create those instances by running the main playbook. I create roles to do the same. You can create the role using below command.
> Creating role to create VPC.
ansible galaxy init create_vpc
> Creating role to create ec2.
ansible galaxy init ec2_launch

As you can in the above picture that the two roles are created successfully. After creating the role you need to write the code inside the respective files. we have vars folder to keep variables and tasks folder to write tasks in that respective files.
# vars file for create_vpc
aws_access_key: 'enter access key'
aws_secret_key: 'enter secret key'
vpc_title: 'K8S Cluster'
vpc_name: "{{ vpc_title }} VPC"
igw_name: "{{ vpc_title }} IGW"
subnet_name: "{{ vpc_title }} Subnet"
security_group_name: "{{ vpc_title }} Security Group"
route_table_name: "{{ vpc_title }} route table"
vpcCidrBlock: '10.0.0.0/16'
subNetCidrBlock: '10.0.1.0/24'
port22CidrBlock: '0.0.0.0/0'
destinationCidrBlock: '0.0.0.0/0'
state: "present"
zone: "ap-south-1a"
region: "ap-south-1"
# vars file for ec2_launch
aws_access_key: 'enter access key'
aws_secret_key: 'enter secret key'
vpc_title: 'K8S Cluster'
vpc_name: "{{ vpc_title }} VPC"
igw_name: "{{ vpc_title }} IGW"
subnet_name: "{{ vpc_title }} Subnet"
security_group_name: "{{ vpc_title }} Security Group"
route_table_name: "{{ vpc_title }} route table"
vpcCidrBlock: '10.0.0.0/16'
subNetCidrBlock: '10.0.1.0/24'
port22CidrBlock: '0.0.0.0/0'
destinationCidrBlock: '0.0.0.0/0'
state: "present"
zone: "ap-south-1a"
region: "ap-south-1"
Os_Names:
- "K8S_Master_testing"
- "K8S_Slave1_testing"
- "K8S_Slave2_testing"
As you can see the Os_Names variable is a list and includes three variables i.e K8S_Master_testing, K8S_Slave1_testing, K8S_Slave2_testing. These three variable are the names of the ec2-instances that we are going to launch.
Now we can proceed with running the main playbook. you create a new file named as main_playbook.yml and the you need to insert the respective roles which you have created above.
- hosts: "localhost"
roles:
- name: "Creating VPC"
role: "/root/task19/create_vpc"
- name: "Launching ec2-instance"
role: "/root/task19/ec2_launch"
Now after creating main_playbook.yml then we can run that using ansible-playbook main_playbook.yml. Ensure one thing if the main playbook run then roles will run simultaneously.

Now you can check the ec2 dashboard you will be finding that three instances are created.

Now after launching the ec2-instances you can configure all the instances for the kubernetes multinode cluster.
Kubernetes is an open source container orchestration engine for automating deployment, scaling, and management of containerized applications. The open source project is hosted by the Cloud Native Computing Foundation.
A Kubernetes cluster is a set of node machines for running containerized applications. If you’re running Kubernetes, you’re running a cluster. At a minimum, a cluster contains a control plane i.e master and one or more compute machines, or nodes. The control plane is responsible for maintaining the desired state of the cluster, such as which applications are running and which container images they use. Nodes actually run the applications and workloads. You can see the below image to see the architecture of kubernetes multinode cluster.


So lets configure master and slaves which we have launched above. Here, i used Ansible Dynamic Inventory to configure master and slave. Dynamic inventory is an ansible plugin that makes an API call to AWS to get the instance information in the run time. It gives you the ec2 instance details dynamically to manage the AWS infrastructure. When I started using the Dynamic inventory, it was just a Python file. Later it became an Ansible plugin. To know how we can use Ansible Dynamic Inventory click here.
First we have to write a playbook for master. You need to do the following steps in the respective playbook.
- Install docker (As we are using Amazon Linux 2 image so we don’t need to configure repo for docker).
- Start docker.
- enable docker.
- Configure Kubernetes Repo.
- Install Kubeadm (it will automatically install kubectl and kubelet).
- enable kubelet.
- pull docker images using kubeadm.
- change driver of docker from cgroupfs to systemd.
- restart docker.
- Installing iproute-tc.
- Setting bridge-nf-call-iptables to 1.
- Initializing Master.
- Creating .kube directory.
- Copying /etc/kubernetes/admin.conf $HOME/.kube/config.
- changing owner permission of $HOME/.kube/config.
- Creating Flannel.
- Generating Token.
So, let’s achieve step by step automation to configure master.
As kubernetes uses container technology behind it so, i have installed docker. you can also use crio for the same. As we are using Amazon Linux 2 AMI which comes with pre-configured repository of docker. I am using package module to install docker. if you are using redhat image then you need to provide docker-ce inside the package module.
- name: "installing docker"
package:
name: docker
state: present
After installing docker we need to start the services of docker. Here i am using service module to start docker.
- name: "Starting Docker"
service:
name: docker
state: started
We need to enable the services of docker so if its your os start again then start will automatically start. In this i am using shell module and the changed_when: false module will helps you to make the command idempotent i.e if run the shell module again then if the docker services are already running then it will not run again.
- name: "enabling docker"
shell: "systemctl enable docker --now"
changed_when: false
After installing and enabling docker we need to configure kubernetes repo to install kuberenete’s kubeadm. Here i have used shell module and given the path /etc/yum.repos.d/kubernetes.repo. so the repo will be created inside the respective path.
- name: Configure kubernetes repo
shell: |
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
changed_when: false
Now we need to install kubeadm. Kubeadm is a tool built to provide kubeadm init and kubeadm join as best-practice “fast paths” for creating Kubernetes clusters. kubeadm performs the actions necessary to get a minimum viable cluster up and running. By design, it cares only about bootstrapping, not about provisioning machines. Installing kubeadm will install kubelet and kubectl behind the scene.
The kubelet is the primary “node agent” that runs on each node. It can register the node with the apiserver using one of: the hostname; a flag to override the hostname; or specific logic for a cloud provider. The kubelet works in terms of a PodSpec. A PodSpec is a YAML or JSON object that describes a pod.
The Kubernetes command-line tool, kubectl, allows you to run commands against Kubernetes clusters. You can use kubectl to deploy applications, inspect and manage cluster resources, and view logs. For a complete list of kubectl operations, see Overview of kubectl.
The output of the command will be stored/register inside kubeadm variable. So we can print the output while running the playbook. To do that i used debug module to print the output. .stdout_lines is the extension to print all the output in the proper format.
- name: "Installing KubeAdm, kubectl and kubelet"
shell: "yum install -y kubeadm --disableexcludes=kubernetes"
register: kubeadm
changed_when: false
- debug:
var: kubeadm.stdout_lines
Now we need to enable kubelet. So after booting our os we don’t need to install start it again and again. Kubelet is the one who connects the master node with the slave nodes or we can say that if some servers are running inside the salve nodes then when client hit the service port then master go to slave via kubelet program.
- name: "Enabling kubelet"
shell: "systemctl enable kubelet --now"
changed_when: false
Every services are running inside the containers. So we need to pull the image to run the containers. kubeadm pulls the images of config file. These images will helps to set up the kubernetes cluster. All these services you can see in the image above.
- name: "Pulling Images using KubeAdm"
shell: "kubeadm config images pull"
changed_when: false
Control groups are used to constrain resources that are allocated to processes. When systemd is chosen as the init system for a Linux distribution, the init process generates and consumes a root control group (cgroup) and acts as a cgroup manager. Systemd has a tight integration with cgroups and allocates a cgroup per systemd unit. It's possible to configure your container runtime and the kubelet to use cgroupfs. Using cgroupfs alongside systemd means that there will be two different cgroup managers. A single cgroup manager simplifies the view of what resources are being allocated and will by default have a more consistent view of the available and in-use resources. When there are two cgroup managers on a system, you end up with two views of those resources. In the field, people have reported cases where nodes that are configured to use cgroupfs for the kubelet and Docker, but systemd for the rest of the processes, become unstable under resource pressure. Changing the settings such that your container runtime and kubelet use systemd as the cgroup driver stabilized the system. To configure this for Docker, set native.cgroupdriver=systemd.
- name: "Creating daemon.json file inside /etc/docker"
shell: |
cat <<EOF | sudo tee /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
changed_when: false
After changing any system setting we need to restart docker to make the changes successful. Here i have used service module to restart docker.
- name: "Re-starting Docker"
service:
name: docker
state: restarted
We need to install the “iproute-tc” software on linux that manages the traffic control. I used package module to install iproute-tc software.
- name: "Installing iproute-tc"
package:
name: iproute-tc
Linux Nodes iptables to see brigged traffic correctly its configuration must be set to 1. we need to set 1 inside /proc/sys/net/bridge/bridge-nf-call-iptables so echo command will do that for you.
- name: "Setting bridge-nf-call-iptables to 1"
shell: |
echo "1" > /proc/sys/net/bridge/bridge-nf-call-iptables
changed_when: false
To ready the master we need to initialize the master. We can do that by using “kubeadm init --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=NumCPU --ignore-preflight-errors=Mem”.
--pod-network-cidr=10.244.0.0/16 will helps to give the range of IP’s to the newly launched pods inside the slave nodes. i.e the ip’s of the pods will be will assigned within the range of 10.244.0.0/16. The range is fixed but if you change the range to something different then you need to edit the range in flannel's configmap. Because the default network assigned by flannel is 10.244.0.0/16. If the range isn’t match then pods ip’s will be of different range and master ip’s range will be different. So it will a conflict between the pods.
As we are using t2.micro instance type i.e it provides us 1gb ram and 1 cpu. Therefore to ignore the error at the preflight check i have used --ignore-preflight-errors=NumCPU to ignore cpu error and --ignore-preflight-errors=Mem to ignore the memory errors while initializing the master. The output of the initialize command contains the tokens that helps to join slave in this newly created master node.
- name: "Initializing Master"
shell: "kubeadm init --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=NumCPU --ignore-preflight-errors=Mem"
ignore_errors: yes
register: init
The output will consists of command that to be run in the master node only so that master node will be in the ready state.
.kube is the main folder where kubernetes keeps all the required files. These commands comes while initializing master and this command has to be run in master node only to ready the master node. After that we need to copy the content from /etc/kubernetes/admin.conf to $HOME/.kube/config. Then we need to change the owner permission of the configuration file (config).
# Creating .kube directory:
- name: "Creating .kube directory"
shell: "mkdir -p $HOME/.kube"
# Copying /etc/kubernetes/admin.conf $HOME/.kube/config.
- name: "Copying /etc/kubernetes/admin.conf $HOME/.kube/config"
shell: "sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config"
# Changing owner permission of $HOME/.kube/config.
- name: "changing owner permission"
shell: "sudo chown $(id -u):$(id -g) $HOME/.kube/config"
Flannel is a plugin that helps to connect the nodes of the slaves and master internally. As in the master initializing section we have already used the range of ip should be assigned to our pods in the respective slave nodes. So to manage the range of ip address to respective pods in the respective slave node is done by flannel only. Flannel acts as a DHCP server as well as router. So DHCP will assign the ip and for NAT flannel has the facility of routing also. If you wanted to ping the container of one nodes to another nodes then flannel will helps you as Nating is done by flannel only. Flannel follows the method of underlaying network as all the steps are hidden and user will not have to know the connection between the containers of different nodes. Users can only feel that both the nodes are in the same LAN but its not. there for its feels like an overlay network and to achieve this flannel uses one of the best tunneling method i.e Vx LAN(Virtual Extended LAN). The services of the flannel is running inside the containers of a particular nodes.
- name: "Running Flannel Command"
shell: "kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml"
Now we need to create the tokens which is provided while initializing the master. The output of the tokens will be stored/registered into tokens variable. The output will be printed using debug module and tokens.stdout_lines is the variable that will print the output in the proper format.
- name: "Generating Token"
shell: "kubeadm token create --print-join-command"
register: tokens
ignore_errors: yes
- debug:
var: tokens.stdout_lines
register: tokens
We have completed all the required steps to achieve configuration on master node. Now we need to do configuration on Slave nodes. The Configuration on Slave nodes is much simpler as most of the steps are repeated.
- Install docker (As we are using Amazon Linux 2 image so we don’t need to configure repo for docker).
- Start docker.
- enable docker.
- Configure Kubernetes Repo.
- Install Kubeadm (it will automatically install kubectl and kubelet).
- enable kubelet.
- pull docker images using kubeadm.
- change driver of docker from cgroupfs to systemd.
- restart docker.
- Installing iproute-tc.
- Setting bridge-nf-call-iptables to 1.
- Join the Slave with the master.
As you can see that most of the steps are same so i am showing step 12 i.e to join slave with master using tokens which we have got while initializing master.
- name: "Initializing Master"
shell: "{{ master_token }}"
ignore_errors: yes
register: init1
- debug:
var: init1.stdout_lines
As you can see that i have used variable master_token in the code. The shell module will run the token after receiving the token from the master_token variable. The user who will run the playbook will have to copy the token after initializing the master and then paste in the prompt “Enter your token to join slave”. Remember all the codes we have to write in tasks section of the role. For the Slave i have created the role. you can create the role using ansible-galaxy init Slaves.

As the title shows you that we have to launch the word press with mysql data base. So i am launching wordpress and mysql inside a pod but you can launch using a yml file. I have create a role to do the same. You can create the role using ansible-galaxy init wordpress-mysql.

As you can see the role is created in above snap successfully. Along with roles of Master and Slaves we now also have Wordpress-mysql role. Now we need to create a pod for the wordpess and mysql to launch them respectively.
---
# tasks file for wordpress-mysql
#task to launch wordpress
- name: "Launching Wordpress"
shell: "kubectl run mywp1 --image=wordpress:5.1.1-php7.3-apache"
register: Wordpress
- debug:
var: "Wordpress.stdout_lines"
#task to launch mysql
- name: "Launching MySql"
shell: "kubectl run mydb1 --image=mysql:5.7 --env=MYSQL_ROOT_PASSWORD=redhat --env=MYSQL_DATABASE=wpdb --env=MYSQL_USER=amit --env=MYSQL_PASSWORD=redhat"
register: MySql
Now in the above tasks we have launched the word press and mysql respectively. To launch the wordpress us euse this command “kubectl run mywp1 --image=wordpress:5.1.1-php7.3-apache” the image version i am using is wordpress:5.1.1-php7.3-apache. To launch mysql pod you need to set the user name and password. Here you can user secret resource kuberenetes or vault module from ansible. You can use this command to launch mysql pod “kubectl run mydb1 --image=mysql:5.7 --env=MYSQL_ROOT_PASSWORD=redhat --env=MYSQL_DATABASE=wpdb --env=MYSQL_USER=amit --env=MYSQL_PASSWORD=redhat” .
#mysql root password
MYSQL_ROOT_PASSWORD=redhat
#mysql database name
MYSQL_DATABASE=wpdb
#mysql user name
MYSQL_USER=amit
#myd=sql password
MYSQL_PASSWORD=redhat
These are the required variable that need to be answered while launching the mysql pod. If you don’t use these variables then it will give error.
- name: "Exposing wordpess"
shell: "kubectl expose pods mywp1 --type=NodePort --port=80"
register: expose
ignore_errors: yes
- debug:
var: "expose.stdout_lines"
To access the wordpress in public world we need to expose. Here, i am exposing on NodePort as the the client is in the public world.
- name: "get service"
shell: "kubectl get svc"
register: svc
- debug:
var: "svc.stdout_lines"
As we are automating whole thing so we don’t need to go inside the master node and check the exposed service port. The above code will get the services an give the output while running the main playbook.
- name: "Pausing playbook for 60 seconds"
pause:
seconds: 60
- name: "gettin database IP"
shell: "kubectl get pods -o wide"
register: Database_IP
- debug:
var: "Database_IP.stdout_lines"
After launching the pods it takes time to launch so, i am pausing the playbook for 60 seconds so all the pods will be ready and we get the complete information of the pods. Now we need to make the main playbook so all the roles will be running by that main playbook.
Creating main playbook to configure master, slave, launch wordpress pod and mysql pod using Dynamic Inventory for AWS:
This main playbook consists of the following:
- Configuring Master Node.
- Configuring Slaves Node.
- Launching Wordpress Pod.
- Launching Mysql Pod.
- hosts: ["tag_Name_K8S_Master_testing"]
roles:
- name: "Configuring Master Node"
role: "/root/MultiNodeK8SCluster/Master"
- hosts: ["tag_Name_K8S_Slave1_testing", "tag_Name_K8S_Slave2_testing"]
vars_prompt:
- name: "master_token"
prompt: "Enter Token To Join To Master: "
private: no
roles:
- name: "Configuring Slave Node"
role: "/root/MultiNodeK8SCluster/Slaves"
- hosts: ["tag_Name_K8S_Master_testing"]
roles:
- name: "Launching Wordpress and Mysql"
role: "/root/MultiNodeK8SCluster/wordpress-mysql"
As we are using dynamic inventory then the inventory plugins for AWS i.e ec2.ini and ec2.py will fetch the ip address of the master and slaves using the tag names respectively. The first role will run for configuring master node and then role for configuration of Slave Nodes. As you can see that i have used here the vars_prompt module that will prompt ask for the token while running the main playbook. Here user needs to copy the token generated after initializing the master and to be pasted inside the prompt variable “Enter Token To Join To Master”. The last role will launch the wordpress and mysql pods respectively as well as expose that pods. You can run the main playbook using ansible-playbook main_plybook.yml.

Now you can take th public of any node wither master or slave with the exposed port you will landed to the wordpress login page and then enter password and username of the mysql database and hit the run installation button. your wordpress application will be ready !! You can check the example in the below gif.


{kind=link}