JSON is a simple data interchange format which has gained tremendous popularity. The aim of this specification is to present a way in which people can export their Machine Learning models into JSON and then import this JSON model and run inference/scoring on new data in any platform of choice.
For example, a model developed using Python scikit-learn can be exported into the JSON model, which can then be imported by a Dart scoring engine to run inference on a Flutter mobile application.
A model specification json file includes the following top-level keys:
| # | Name | Value Type | Optional | Description |
|---|---|---|---|---|
| 1 | input |
object |
No | Provides the names and types of model input fields. Each field represents an independent variable of the model (X) |
| 2 | output |
object |
No | Provides the name and type of model onput field. It represents the target variable of the model (Y). |
| 3 | transformer |
object |
Yes | Provides the details in regards to the data transformation the input goes through before entering the model. |
| 4 | model |
object |
No | Provides the details of the Machine Learning model. |
Let us take a deep dive into each of the above objects:
The object value corresponding to input is a map of field names (keys) and details corresponding to those fields (values).
For example, if there is a field (independent variable) having name - Dependents which represents the number of family members (integer value) who depend on the given person, then it will be represented as "Dependents": {"type": "int"} in the field map. In case there is a categorical variable like Gender which can have only one of the fixed categorical values (Male and Female) as input, the field will be represented as "Gender": {"type": "category", "values": ["Female", "Male" ]}. The reason for including values for categorical fields is to perform One-Hot Encode operation where the input values are replaced by the corresponding index locations in the array.
Currently, this specification allows 4 types of fields - bool, int, float and category. A representative example is shown below for better understanding.
Example
"input": {
"Gender": {
"type": "category",
"values": [
"Female",
"Male"
]
},
"IsMarried": {
"type": "bool"
},
"Dependents": {
"type": "int"
},
"Applicant Income": {
"type": "float"
},
"Loan Amount": {
"type": "int"
},
"Property Area": {
"type": "category",
"values": [
"Rural",
"Semiurban",
"Urban"
]
}
},The object corresponding to output is a singleton map containing the field name of the target variable (Y) and the type & value details of this field.
Some examples are provided below:
"output": {
"Predicted Price": {
"type": "float"
}
},When a ML model outputs discrete indexes representing some meaningful output (in original data in case of supervised learning model), category type output is used where the array corresponding to values represent the text at the location corresponding to the output index generated by the model.
"output": {
"species": {
"type": "category",
"values": [
"versicolor",
"setosa",
"virginica"
]
}
},Transformers provide certain rules for transforming the input data before it enters the model. It can also include the parameters for transforming output field which is used to inverse transform the model output to fetch the real output of the model after scoring. The specification currently supports Standard and MinMax transformers which are two most popular ways of transforming the input data.
The transformer object is specified using a map with keys
type-"Standard"or"MinMax"scale_fields- a map of fields names (keys) and the corresponding map of scaling parameters (value) for the field.
The scaling parameters a field include:
meanandstddevif transformer type is"Standard". For a field in the data with valuexthe transformed input isx_new = (x - mean)/stddevscaleandminif transformer type is"MinMax". For a field in the data with valuexthe transformed input isx_new = x*scale + min
"transformer": {
"type": "Standard",
"scale_fields": {
"X1": {
"mean": 17.71256038647343,
"stddev": 11.378717175302857
},
"X2": {
"mean": 1083.8856889130436,
"stddev": 1260.5843868803893
},
"X3": {
"mean": 4.094202898550725,
"stddev": 2.94200221305731
},
"X4": {
"mean": 24.969030072463767,
"stddev": 0.012395199368547943
},
"X5": {
"mean": 121.53336108695655,
"stddev": 0.015328636553097923
},
"Y": {
"mean": 37.980193236714975,
"stddev": 13.590044806293161
}
}
},"transformer": {
"type": "MinMax",
"scale_fields": {
"sepal length (cm)": {
"scale": 0.27777777777777773,
"min": -1.1944444444444442
},
"sepal width (cm)": {
"scale": 0.41666666666666663,
"min": -0.8333333333333333
},
"petal length (cm)": {
"scale": 0.1694915254237288,
"min": -0.1694915254237288
},
"petal width (cm)": {
"scale": 0.4166666666666667,
"min": -0.04166666666666667
}
}
},Model represents the model parameters of the machine learning model to be deployed by the scoring engine. The specification currently supports Linear Regression, Kmeans Cluster Scoring and Decision Tree Classification models.
The model object is specified using a map with keys
type-"LinearRegression"(Linear Regression - OLS),"KMeans"(Kmeans Clustering) or"DecisionTreeClassifier"(Decision Tree Classification)scoring_params- a map representing the model parameters described in detail below.
The details of scoring_params corresponding to each type of model is provided below:
scoring_params maps to the coefficients (a map of field names and corresponding regression coefficient) and intercept of the model. In the regression equation y = mX + c, coefficients is the slope of the line m and intercept is c.
Example
"model": {
"type": "LinearRegression",
"scoring_params": {
"coefficients": {
"X1": -0.2088487324668208,
"X2": -0.4364737354827348,
"X3": 0.24137141607851909,
"X4": 0.2145464231393842,
"X5": -0.03920053208130342
},
"intercept": 0.03039926688849016
}
}scoring_params maps to the centers (an array of cluster ceter records) and distance metric of the model. The metric can map to values - "euclidean", "manhattan" or "cosine" which represent the function which has to be used to compare each new datum with the center of the clusters. An item at the ith location in the the array of cluster centers represents the value of centroid of cluster labelled i (model output). Each centroid is a map of feature names and the corresponding centroid values along the feature axis.
Example
"model": {
"type": "KMeans",
"scoring_params": {
"metric": "euclidean",
"centers": [
{
"sepal length (cm)": 0.4412568306010929,
"sepal width (cm)": 0.3073770491803278,
"petal length (cm)": 0.5757154765212559,
"petal width (cm)": 0.5491803278688525
},
{
"sepal length (cm)": 0.1961111111111111,
"sepal width (cm)": 0.595,
"petal length (cm)": 0.0783050847457627,
"petal width (cm)": 0.06083333333333335
},
{
"sepal length (cm)": 0.7072649572649572,
"sepal width (cm)": 0.4508547008547008,
"petal length (cm)": 0.7970447631464579,
"petal width (cm)": 0.8247863247863247
}
]
}
}The scoring_params of a Decision Tree Classifier is essentially the nested tree generated by the model containing nodes and splits starting at the root node.
Each node in the tree is represented by a map which tells whether it is a leaf (isleaf), the variable/field name on which the decison happens (field), the value of the split (split_value), the node on the left (l) and the node on the right (r). These left and right nodes have the same structure recursively.
A leaf node contains isleaf (set as true) and the output decision class (class) corresponding to the leaf node.
Example
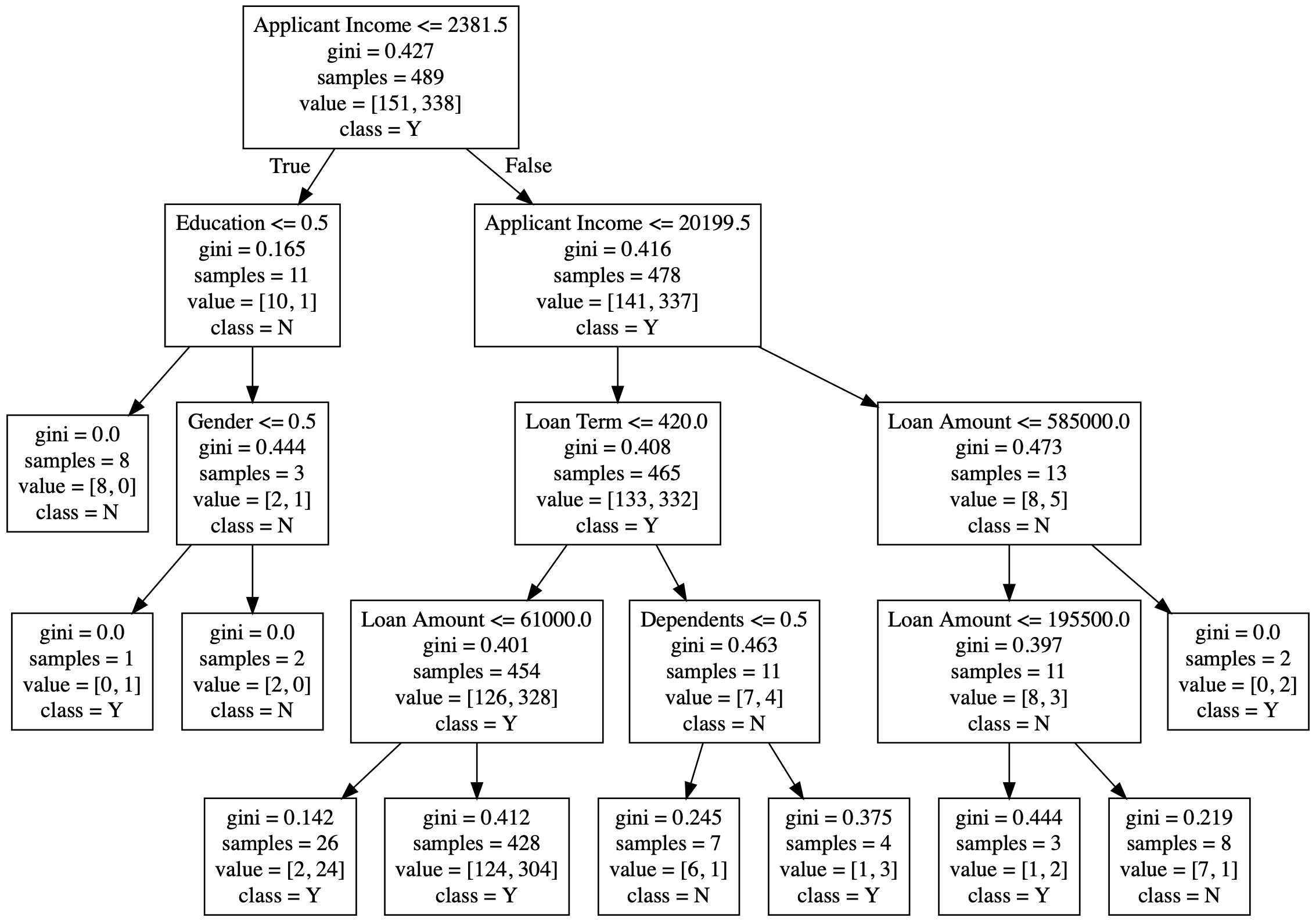
The json model for the above decision tree (graphviz image) is as follows:
"model": {
"type": "DecisionTreeClassifier",
"scoring_params": {
"tree": {
"isleaf": false,
"field": "Applicant Income",
"split_value": 2381.5,
"l": {
"isleaf": false,
"field": "Education",
"split_value": 0.5,
"l": {
"isleaf": true,
"class": 0
},
"r": {
"isleaf": false,
"field": "Gender",
"split_value": 0.5,
"l": {
"isleaf": true,
"class": 1
},
"r": {
"isleaf": true,
"class": 0
}
}
},
"r": {
"isleaf": false,
"field": "Applicant Income",
"split_value": 20199.5,
"l": {
"isleaf": false,
"field": "Loan Term",
"split_value": 420.0,
"l": {
"isleaf": false,
"field": "Loan Amount",
"split_value": 61000.0,
"l": {
"isleaf": true,
"class": 1
},
"r": {
"isleaf": true,
"class": 1
}
},
"r": {
"isleaf": false,
"field": "Dependents",
"split_value": 0.5,
"l": {
"isleaf": true,
"class": 0
},
"r": {
"isleaf": true,
"class": 1
}
}
},
"r": {
"isleaf": false,
"field": "Loan Amount",
"split_value": 585000.0,
"l": {
"isleaf": false,
"field": "Loan Amount",
"split_value": 195500.0,
"l": {
"isleaf": true,
"class": 1
},
"r": {
"isleaf": true,
"class": 0
}
},
"r": {
"isleaf": true,
"class": 1
}
}
}
}
}
}