
For the past few years I’ve been thinking about how I could build SaaS and deploy it on my own infrastructure without needing to use any cloud platforms like AWS or GCP. In this repo I document my progress on building a clone of AWS S3 that functions the same as S3 (automated bucket deployment, dynamically expanding volumes, security, etc) using an exclusively open-source technology stack.
- Console
- Nodes
- Source Control: GitLab
- K3s: Production Cluster
- Deploying From GitLab Registry To Local K3s Cluster
- K3s: Storage Cluster
- Automated Bucket Deployment
- API
- Frontend
- Connecting to the Internet
const { S3Client, ListObjectsV2Command, PutObjectCommand } = require("@aws-sdk/client-s3");
const Bucket = 'BUCKET_NAME_HERE';
const Namespace = 'NAMESPACE_HERE';
const accessKeyId = "xxxxxxxxxxxxxxxxxxxx";
const secretAccessKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
(async function () {
const client = new S3Client({
region: 'us-west-2',
endpoint: `https://${Bucket}.${Namespace}.s3.anthonybudd.io`,
forcePathStyle: true,
sslEnabled: true,
credentials: {
accessKeyId,
secretAccessKey
},
});
const Key = `${Date.now().toString()}.txt`;
await client.send(new PutObjectCommand({
Bucket,
Key,
Body: `The time now is ${new Date().toLocaleString()}`,
ACL: 'public-read',
ContentType: 'text/plain',
}));
console.log(`New object successfully written to: ${Bucket}://${Key}\n`);
const { Contents } = await client.send(new ListObjectsV2Command({ Bucket }));
console.log("Bucket Contents:");
console.log(Contents.map(({ Key }) => Key).join("\n"));
})();


Since this project needs to be "Enterprise-grade" we need a distinct and replicable compute unit that we can buy and build in bulk. I all this a "Node" which is a Raspberry Pi with a 1TB SSD and POE hat. I have also 3D printed a rack-mount solution (Source: Merocle From UpTimeLabs, Files: ./node/rack-mount-mk3.zip)2 for easy install into the rack.

We will need a "console" so we can locally interact with the infrastructure. I have tried using a Raspberry Pi with a monitor and keyboard attached but I have found that using an old MacBook Pro works best for this. In this section I explain how to set-up the console so you can use it to store secrets, manage the network, provision K3s clusters and deploy pods.
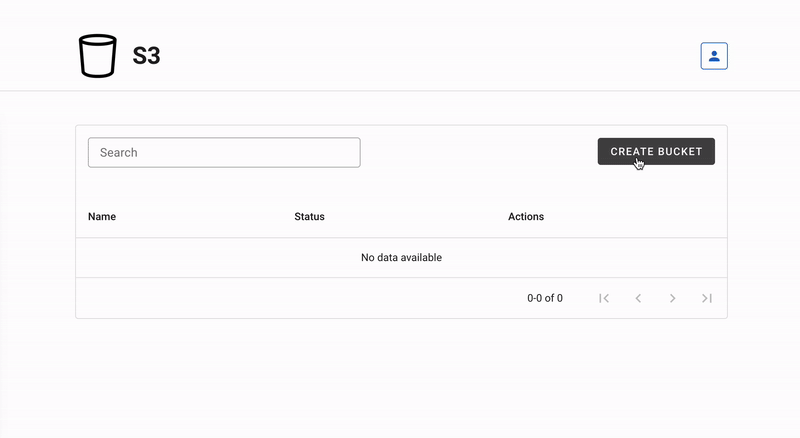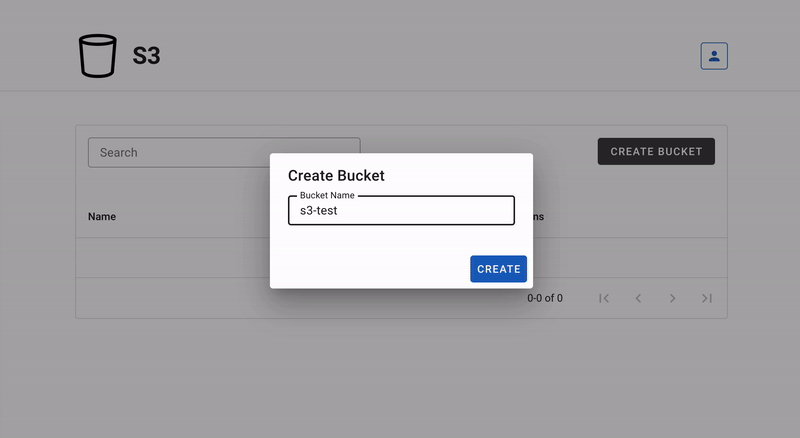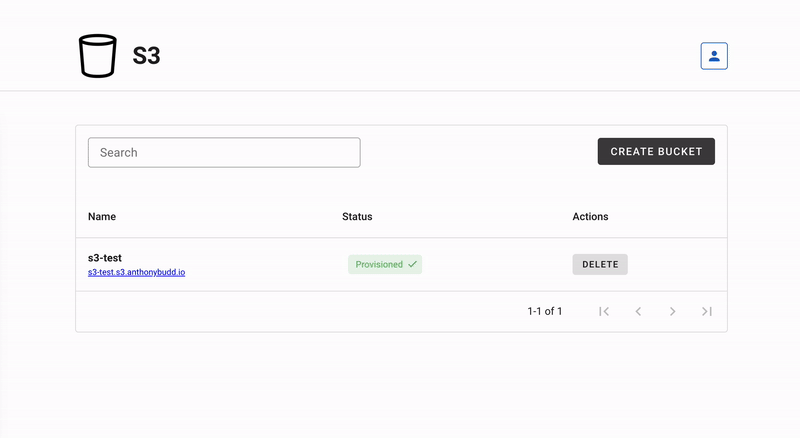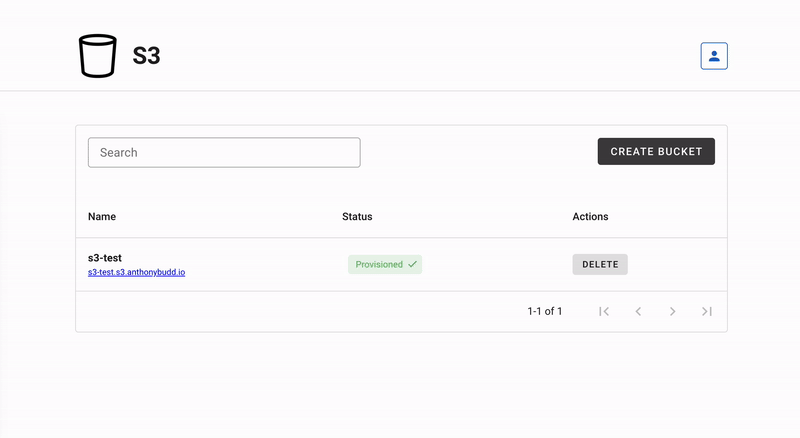
Live: s3.AnthonyBudd.io
This represents the AWS management console found at aws.amazon.com/console. This is a Vue.js SPA that makes HTTP requests to the S3 REST API for users to create, manage and delete their S3 buckets.
curl -X POST \
-H 'Authorization: Bearer $JWT' \
-H 'Content-Type: application/json' \
-d '{ "name":"s3-test-bucket"}' \
https://s3-api.anthonybudd.io/bucketsLive: s3-api.AnthonyBudd.io
This API simulates the back-end of the AWS Console. A user can sign-up, login, create a bucket then delete the bucket.
![]()
We will need a way to store the code for the landing website, the front-end app and the back-end REST API. We will also need CI/CD to compile the code and deploy it into our infrastructure. GitLab will work perfectly for these two tasks.

We will need a network for the nodes to communicate. For the a router I have chosen OpenWRT. This allows me to use a Raspberry Pi with a USB 3.0 Ethernet adapter so it can work as as a router between the internet and the “datacenter”.
When you create an S3 bucket on AWS, everything is automated, there isn’t a human in a datacenter somewhere typing out CLI commands to get your bucket scheduled. This project must also work the same way, when a user wants to create a resource it must not require any human input to provision and deploy the bucket.
Due to the scale of AWS it would not be financially practical to give each user their own dedicated server hardware, instead the hardware is virtualized, allowing multiple tenants to share a single physical CPU. Similarly it would not be practical to assign a whole node and SSD to each bucket, to maximize resource utilization my platform must be able to allow multiple tenants to share the pool of SSD storage space available. In addition, AWS S3 buckets can store an unlimited amount of data, so my platform will also need to allow a user to have a dynamically increasing volume that will auto-scale based on the storage space required.
You will need to SSH into multiple devices simultaneously I have added an annotation (example: [Console] nano /boot/config.txt) to all commands in this repo, to show where you should be executing each command. Generally you will see [Console] and [Node X].
Because this is still very much a work-in-progress you will see my notes in italics "AB:" throughout, please ignore.